QUESTION 1–6
Discuss the relative advantages and disadvantages of light and electron microscopy. How could you best visualize a living skin cell, a yeast mitochondrion, a bacterium, and a microtubule?
All cells appear to be descended from an ancient ancestor whose fundamental properties have been conserved through evolution. Therefore, knowledge gained from the study of one organism contributes to our understanding of all others, including ourselves. However, certain organisms are easier to study in the laboratory than others. Some reproduce rapidly and are convenient for genetic manipulation; others are multicellular but transparent, so the development of all their internal tissues and organs can be observed directly in the live animal.
QUESTION 1–6
Discuss the relative advantages and disadvantages of light and electron microscopy. How could you best visualize a living skin cell, a yeast mitochondrion, a bacterium, and a microtubule?
For reasons such as these, biologists have become dedicated to studying a few representative species. By focusing on such model organisms, scientists around the world can effectively pool their knowledge and resources to gain a deeper understanding than could be achieved if their efforts were spread over many different species. Although the roster of these representative organisms is continually expanding, a few stand out in terms of the breadth and depth of information that has been accumulated about them over the years—knowledge that contributes to our understanding of how all cells work.
In this section, we introduce some of these model systems and review the advantages that each offers to the study of cell biology. Studies conducted on these and other model organisms led to the discoveries that underlie all of information we present in this book. In many cases, they have also led to direct benefits for human health.
Geneticist Jacques Monod is reported to have remarked that “anything found to be true of E. coli must also be true of elephants.” Befitting this belief, biologists have been studying the bacterium Escherichia coli—E. coli for short—for the better part of a century. In molecular terms, we understand the workings of this humble organism more thoroughly than those of any other living thing on our planet. This small, rod-shaped cell (see Figure 1–12) lives harmlessly in the gut of humans and other vertebrates, but it will also grow happily and reproduce rapidly in a simple nutrient broth in the laboratory.
Most of our knowledge of the fundamental mechanisms of life has come from studies of E. coli. Monod fittingly used E. coli to explore how cells regulate gene expression, as discussed in Chapter 8. The bacterium has also revealed how cells replicate their DNA and how they decode the instructions contained in DNA to make proteins. Decades of research have since confirmed that the same principles operate in our own cells.
E. coli has also facilitated many practical advances in biotechnology. Studies of enzymes produced by this bacterium led to the development of tools that launched the “recombinant DNA” revolution, enabling us for the first time to be able to manipulate genes and DNA in the laboratory (discussed in Chapter 10). At the same time, E. coli has also been harnessed as a biological factory for producing large quantities of therapeutic proteins, including insulin. This one small organism therefore continues to have an oversized impact on basic science and biomedicine.

A micrograph shows a cluster of budding yeast cells. Each yeast cell is about 10 micrometers in diameter.
Figure 1–32 The yeast Saccharomyces cerevisiae is a model eukaryote. In this scanning electron micrograph, a number of the cells are captured in the process of dividing, which they do by budding. A light micrograph of the same species is shown in Figure 1–16. (Courtesy of Ira Herskowitz and Eric Schabtach.)
As human beings, we tend to be preoccupied with eukaryotes because we are eukaryotes ourselves. But Homo sapiens is challenging to study directly. So, to efficiently explore the fundamental biology of eukaryotes, we focus on simpler representatives—ones that are easier to keep and that reproduce more rapidly. A popular stand-in has been the budding yeast Saccharomyces cerevisiae (Figure 1–32)—the same species that is used for brewing beer and baking bread.
S. cerevisiae is a small, single-celled fungus that, like all fungi, is more closely related to animals than it is to plants (Figure 1–33). Similar to other fungi, it has a rigid cell wall, is relatively immobile, and possesses an array of organelles—including a nucleus, Golgi apparatus, ER, and mitochondria—but no chloroplasts. When nutrients are plentiful, S. cerevisiae can grow and divide almost as rapidly as a bacterium. Yet it carries out all the basic tasks that every eukaryotic cell must perform and can even mate with S. cerevisiae of the opposite “sex,” providing biologists a simple system in which to study the genetics of sexual reproduction.
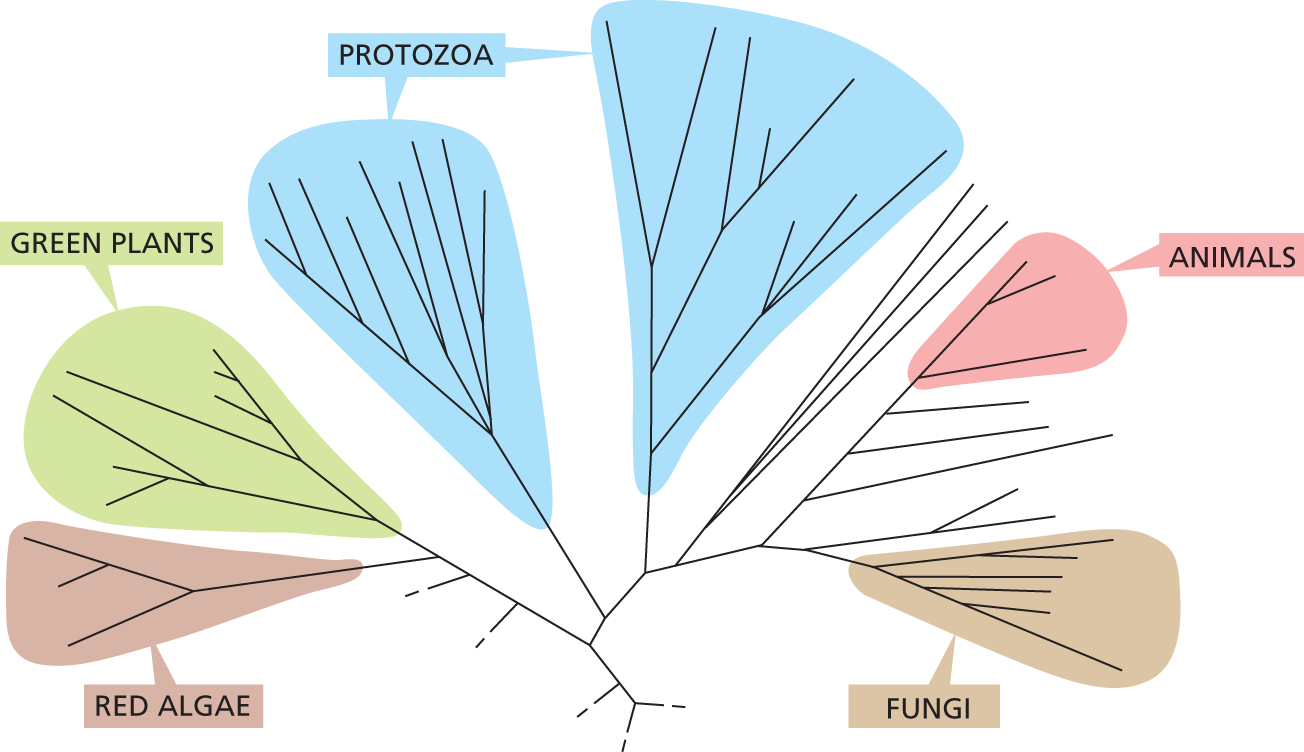
A simplified family tree for several groups of eukaryotic organisms. All the branches originate from a single point. Further branching creates groups which are designated. Green Plants and Red Algae are on the same branch and branch off first. Next there are two groups of branches which are both labeled protozoa. Further along there are Animals and Fungi which are smaller groups of branches.
Figure 1–33 A portion of the eukaryotic family tree shows that fungi are closely related to animals. Although many fungi seem plantlike—mushrooms, for example, sprout from the soil and are immotile—these eukaryotes are more closely related to animals. This is also true of yeasts such as S. cerevisiae, which—like their animal kin—lack chloroplasts and are incapable of carrying out photosynthesis. Note that, in this eukaryotic tree, the animal group is separated from the plant cluster by a collection of single-celled protozoa, suggesting that multicellularity evolved independently multiple times during the course of eukaryotic evolution. This “in between” group includes protozoans like Euglena (see Figure 1–31F); this creature has chloroplasts, like plants, but can also ingest food, like animals. (Adapted from F. Burki, Cold Spring Harb. Perspect. Biol. 6:a016147, 2014.)
Genetic and biochemical studies in yeast have been crucial to understanding many fundamental mechanisms in eukaryotic cells, including the cell-division cycle—the chain of events by which the nucleus and all the other components of a cell are duplicated and parceled out to create two daughter cells. The machinery that governs cell division has been so well conserved over the course of evolution that many of its components can function interchangeably in yeast and human cells (How We Know, pp. 33–34). Darwin himself would no doubt have been delighted by this dramatic example of evolutionary conservation.
The large, multicellular organisms that we see around us—both plants and animals—are fantastically varied in appearance. But they are much closer to one another, in their evolutionary origins and their basic cell biology, than they are to the great host of microscopic single-celled organisms we have been discussing. Whereas bacteria and archaea are separated from each other by more than 3 billion years of evolution, plants, animals, and fungi diverged about 1.5 billion years ago, and the different species of flowering plants only about 150 million years ago (see Figure 1–22).
The close evolutionary relationship among all flowering plants means that we can gain insight into their cell and molecular biology by focusing on just a few convenient species for detailed analysis. Out of the nearly 400,000 known species of flowering plants on Earth today, molecular biologists have chosen to concentrate their efforts on a small weed in the cabbage family, a common wall cress called Arabidopsis thaliana (Figure 1–34). Arabidopsis can be grown indoors in large numbers: each plant can produce thousands of offspring within 8–10 weeks.

A botanical print shows Arabidopsis thaliana on a scale of 1 centimeter. It is about 11 centimeters tall and has rounded leaves. The seed pods are on the top half of the plant and are long and and narrow.
Figure 1–34 Arabidopsis thaliana, the common wall cress, is a model plant. This small weed has become the favorite organism of plant molecular and developmental biologists. (Courtesy of Toni Hayden and the John Innes Centre.)
Work on Arabidopsis has provided a deep understanding of the mechanisms that enable plants to grow toward sunlight, to flower in spring, and to coordinate their development with the cycle of the seasons. Because genes found in Arabidopsis have counterparts in agricultural species, studying this simple weed provides insights into the development and physiology of the crop plants upon which our lives depend, as well as into the evolution of all the other plant species that dominate nearly every ecosystem on the planet.
Although plants make up about 80% of Earth’s biomass, animals account for the majority of all named species of living organisms and they are, by far, the most intensively studied. Of this plethora, a few species have emerged as the optimal vehicles with which to explore the molecular, cell, and developmental biology of animals. The smallest and simplest of these is a nematode worm called Caenorhabditis elegans (Figure 1–35). This compact creature develops with clockwork precision from a fertilized egg cell into an adult that has exactly 959 body cells (plus a variable number of egg and sperm cells)—an unusual degree of regularity for an animal. We now have a minutely detailed description of the sequence of events by which this occurs—as the cells divide, move, and become specialized according to strict and predictable rules. Some 70% of human genes have some counterpart in this worm, and C. elegans has proved to be a valuable model for many of the developmental processes that occur in our own bodies. Studies of nematode development, for example, have led to a detailed molecular understanding of apoptosis, a form of programmed cell death by which animals dispose of surplus cells, a topic discussed in Chapter 18. This process is also of great importance in the development of cancer, as we discuss in Chapter 20.
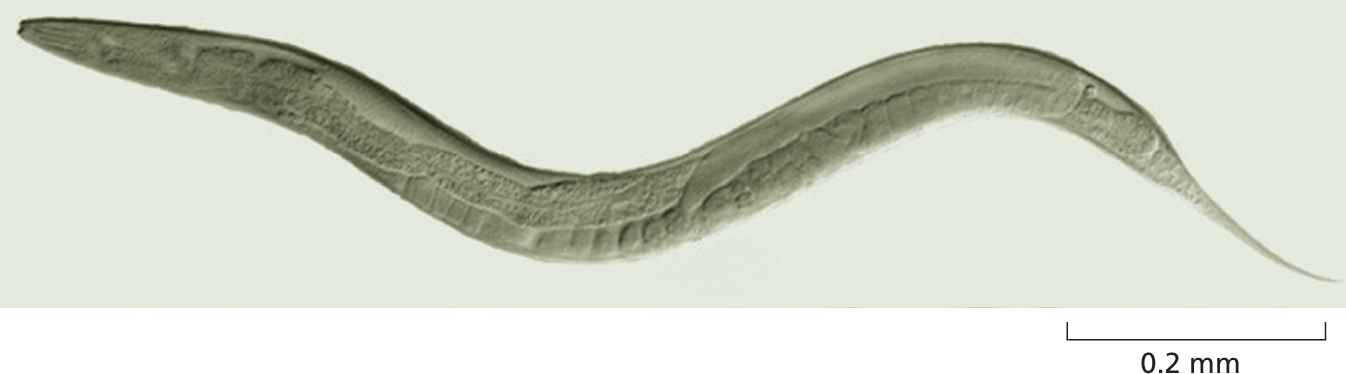
A photo shows Caenorhabditis elegans on a scale of 0.2 millimeters. It is about 1 millimeter long, translucent, and in an elongated S shape.
Figure 1–35 Caenorhabditis elegans is a small nematode worm that normally lives in the soil. Most individuals are hermaphrodites, producing both sperm and eggs (the latter of which can be seen just beneath the skin along the underside of the animal). C. elegans was the first multicellular organism to have its complete genome sequenced. (Courtesy of Maria Gallegos.)
QUESTION 1–7
Your next-door neighbor has donated $100 in support of cancer research and is horrified to learn that her money is being spent on studying brewer’s yeast. How could you put her mind at ease?
Although it doesn’t have a spine, the fruit fly Drosophila melanogaster (Figure 1–36) has long been the backbone of the study of animal genetics. Nearly 100 years ago, genetic analysis of the fruit fly provided definitive proof that genes—the units of heredity—are carried on chromosomes. In more recent times, Drosophila, more than any other organism, has shown us how the genetic instructions encoded in DNA molecules direct the development of a fertilized egg cell (or zygote) into an adult multicellular organism containing vast numbers of different cell types organized in a precise and predictable way. Drosophila mutants with body parts strangely misplaced or oddly patterned have provided the key to identifying and characterizing the genes that are needed to make a properly structured adult body, with gut, wings, legs, eyes, and all the other bits and pieces—all in their correct places. These genes—which are copied and passed on to every cell in the body—define how each cell will behave in its social interactions with its sisters and cousins, thus controlling the structures that the cells can create, a regulatory feat we return to in Chapter 8. More importantly, the genes responsible for the development of Drosophila have turned out to be amazingly similar to those of humans—far more similar than one would suspect from the outward appearances of the two species. Thus the fly serves as a valuable model for studying human development as well as the genetic basis of many human diseases.

A photo shows Drosophila melanogaster on a scale of 1 millimeter. The fly is about 3 millimeters long and has reddish orange body with black striped on its abdomen.
Figure 1–36 Drosophila melanogaster is a favorite among developmental biologists and geneticists. Molecular genetic studies on this small fly have provided a key to the understanding of how all animals develop. (Edward B. Lewis. Courtesy of the Caltech Archives, California Institute of Technology.)
Another animal that is providing molecular insights into developmental processes, particularly in vertebrates, is the zebrafish (Figure 1–37A). Popular in home aquaria, this fish can be easily bred and maintained in the laboratory. Because zebrafish are transparent for their first 2 weeks of life, they provide an ideal system in which to observe how cells behave during development in a living animal (Figure 1–37B). As a result, studies of zebrafish have provided key insights into the development of the heart and blood vessels.

A photo of adult zebra fishes on a 1 centimeter scale. Each fish is 2 to 3 centimeters long. They have blue and gold stripes on their sides.
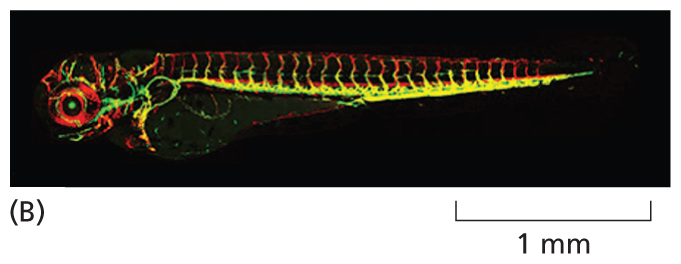
A micrograph of a two-day old embryo of a zebra fish, 1 millimeter scale. The embryo is about 3 millimeters long. The micrograph shows a distinct head and a tapering body. There are red lines in the head region and a yellow line along the spine.
Mammals are among the most complex of animals, and the mouse has long been used as the model organism in which to study mammalian genetics, development, immunology, and cell biology. Thanks to modern molecular biological techniques, it is possible to breed mice with deliberately engineered mutations in any specific gene, or with artificially constructed genes introduced into them (as we discuss in Chapter 10). In this way, one can test the function of any gene and determine how it works in a living mammal. Almost every human gene has a counterpart in the mouse, with a similar DNA sequence and function. Thus, this animal has proven an excellent model for studying genes that are important in both human health and disease.
All living things are made of cells, and all cells—as we have discussed in this chapter—are fundamentally similar inside: they store their genetic instructions in DNA molecules, which direct the production of RNA molecules that direct the production of proteins. It is largely proteins that carry out the cell’s chemical reactions, many of which are common to all living things. But how deep do the similarities between cells—and the organisms they comprise—really run? Are proteins from one organism interchangeable with proteins from another? Would an enzyme that breaks down glucose in a bacterium, for example, be able to digest the same sugar if it were placed inside a yeast cell or a cell from a lobster or a human? What about the molecular machines that copy and interpret genetic information? Are they functionally equivalent from one organism to another? Insights have come from many sources, but the most stunning and dramatic answer came from experiments performed on humble yeast cells. These studies, which shocked the biological community, focused on one of the most fundamental processes of life—cell division.
All cells come from other cells, and the only way to make a new cell is through division of a preexisting one. To reproduce, a parent cell must execute an orderly sequence of reactions, through which it duplicates its contents and divides in two. This critical process of duplication and division—known as the cell-division cycle, or cell cycle for short—is complex and carefully controlled. Defects in any of the proteins involved can be devastating to the cell.
Fortunately for biologists, this acute reliance on crucial proteins makes them easy to identify and study. If a protein is essential for a given process, a mutation that results in an abnormal protein—or in no protein at all—can prevent the cell from carrying out the process. By isolating organisms that are defective in their cell-division cycle, scientists have worked backward to discover the proteins that are necessary to control progress through the cycle.
The study of cell-cycle mutants has been particularly successful in yeasts. Yeasts are unicellular fungi and are popular organisms for such genetic studies. Like us, they are eukaryotes, but they are also small, simple, rapidly reproducing, and easy to manipulate genetically, which makes them excellent models for studying the fundamental processes that operate in our own cells. Yeast mutants that are defective in their ability to complete cell division have led to the discovery of many genes that control the cell-division cycle—the so-called Cdc genes—and have provided a detailed understanding of how these genes, and the proteins they encode, actually work.
Paul Nurse and his colleagues used this approach to identify Cdc genes in the yeast Schizosaccharomyces pombe, which is named after the African beer from which it was first isolated. S. pombe is a rod-shaped cell, which grows by elongation at its ends and divides by fission into two, through the formation of a partition in the center of the rod (see Figure 1–1E). The researchers found that one of the Cdc genes they had identified, called Cdc2, was required to trigger several key events in the cell-division cycle. When that gene was inactivated by a mutation, the yeast cells would not divide. And when the cells were provided with a normal copy of the gene, their ability to reproduce was restored.
It’s obvious that replacing a faulty Cdc2 gene in S. pombe with a functioning Cdc2 gene from the same yeast should repair the defect and enable the cell to divide normally. But what about using a similar cell-division gene from a different organism? That’s the question the Nurse team tackled next.
Saccharomyces cerevisiae is another kind of yeast, and is one of a handful of model organisms biologists have chosen to study to expand their understanding of how eukaryotic cells work. Also used to brew beer, S. cerevisiae divides by forming a small bud that grows steadily until it separates from the mother cell (see Figure 1–16 and Figure 1–32). Although S. cerevisiae and S. pombe differ in their style of division, both rely on a complex network of interacting proteins to get the job done. But could the proteins from one type of yeast substitute for those of the other?
To find out, Nurse and his colleagues prepared DNA from healthy S. cerevisiae, and they introduced this DNA into S. pombe cells that contained a temperature-sensitive mutation in the Cdc2 gene that kept the cells from dividing when the heat was turned up. And they found that some of the mutant S. pombe cells regained the ability to proliferate at the elevated temperature. If spread onto a culture plate containing a growth medium, the rescued cells could divide again and again to form visible colonies, each containing millions of individual yeast cells (Figure 1–38). Upon closer examination, the researchers discovered that these “rescued” yeast cells had received a piece of DNA that contained the S. cerevisiae version of Cdc2—a gene that had been discovered in pioneering studies of the cell cycle by Lee Hartwell and colleagues and which closely resembled the S. pombe gene in its nucleotide sequence.
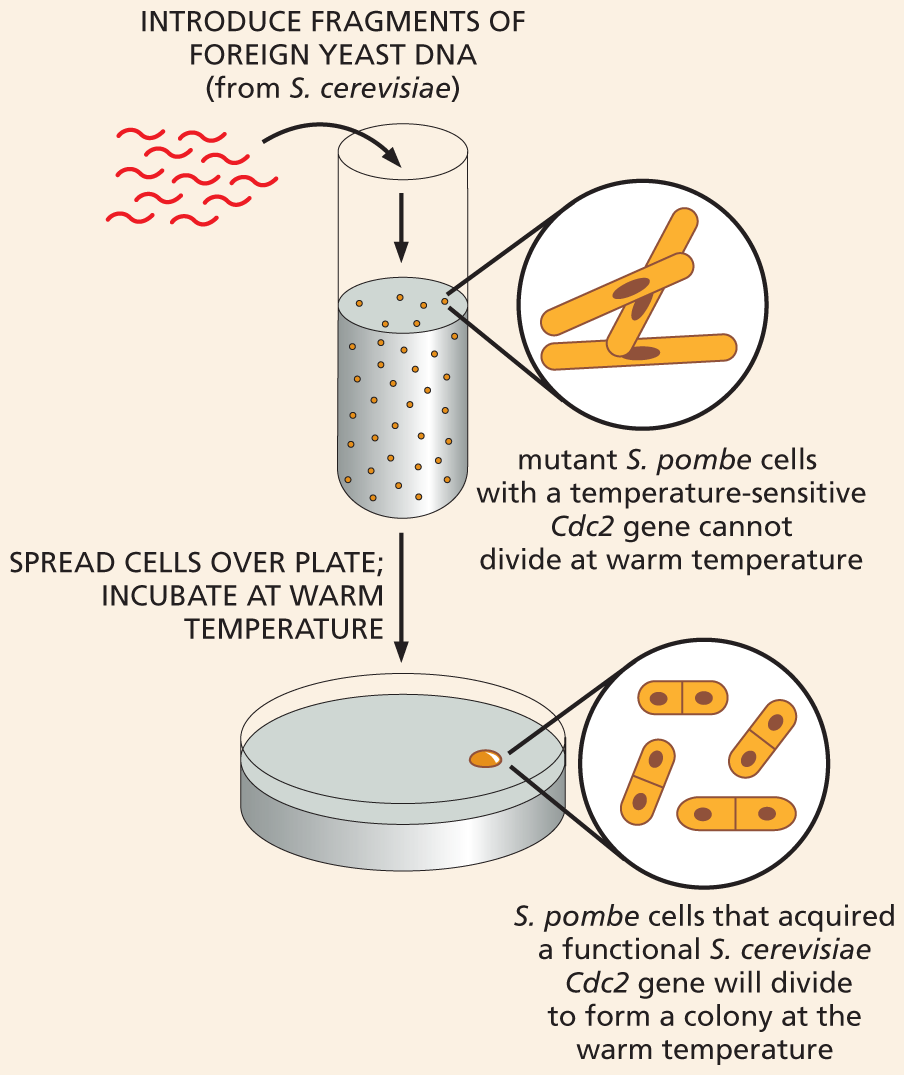
An illustration shows an experimental setup for gene rescue. Step 1: Fragments of foreign yeast D N A from Saccharomyces cerevisiae are introduced into a test tube, corresponding text reads mutant Schizosaccharomyces pombe cells with a temperature-sensitive cell division control 2 gene cannot divide at warm temperature. A magnified view shows rod shaped cells.
Step 2: Text reads: spread cells over plate; incubate at warm temperature. Cells are collected in a petri dish. Text reads, cells that received a functional Saccharomyces cerevisiae substitute for the cell division control 2 gene will divide to form a colony at the warm temperature. A magnified view of the content in the petri dish shows a colony of oval shaped cells that are dividing.
Figure 1–38 S. pombe mutants defective in a cell-cycle gene can be rescued by the equivalent gene from S. cerevisiae. DNA is collected from S. cerevisiae and broken into large fragments, which are introduced into a culture of mutant S. pombe cells dividing at room temperature. (We discuss how DNA can be manipulated and transferred into different types of cells in Chapter 10.) These yeast cells are then spread onto a plate containing a suitable growth medium and are incubated at a warm temperature, at which the mutant Cdc2 protein is inactive. The rare cells that survive and proliferate on these plates have been “rescued” by incorporation of a foreign DNA fragment containing the S. cerevisiae Cdc2 gene, allowing them to divide normally at the higher temperature.
The result was exciting, but perhaps not all that surprising. After all, how different can one yeast be from another? A more demanding test would be to use DNA from a more distant relative. So Nurse’s team repeated the experiment, this time using human DNA. And the results were the same. The human equivalent of the S. pombe Cdc2 gene could rescue the mutant yeast cells, allowing them to divide normally.
This result was much more surprising—even to Nurse. The ancestors of yeast and humans diverged some 1.5 billion years ago. So it was hard to believe that these two organisms would orchestrate cell division in such a similar way. But the results clearly showed that the human and yeast proteins are functionally equivalent. Indeed, Nurse and colleagues demonstrated that the proteins are almost exactly the same size and consist of amino acids strung together in a very similar order; the human Cdc2 protein is identical to the S. pombe Cdc2 protein in 63% of its amino acids and is identical to the equivalent protein from S. cerevisiae in 58% of its amino acids (Figure 1–39). Together with Tim Hunt, who discovered a different cell-cycle protein called cyclin, Nurse and Hartwell shared a 2001 Nobel Prize for their studies of key regulators of the cell cycle.
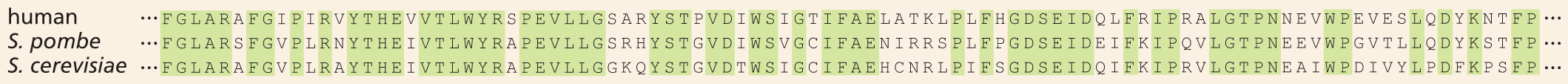
Amino acid sequences of a human, a Schizosaccharomyces pombe, and a Saccharomyces cerevisiae. There are many codons that are common in the three sequences which are highlighted.
Figure 1–39 The cell-division-cycle proteins from yeasts and human are very similar in their amino acid sequences. Identities between the amino acid sequences of a region of the human Cdc2 protein and a similar region of the equivalent proteins in S. pombe and S. cerevisiae are indicated by green shading. Each amino acid is represented by a single letter (see the inside front cover of this book).
The Nurse experiments showed that proteins from very different eukaryotes can have very similar amino acid sequences and can be functionally interchangeable; they also suggested that the cell cycle is controlled in a similar fashion in every eukaryotic organism alive today. Apparently, the proteins that orchestrate the cycle in eukaryotes are so fundamentally important that they have been conserved almost unchanged over more than a billion years of eukaryotic evolution.
The same experiment also highlights another, even more basic point. The mutant yeast cells were rescued, not by direct injection of the human protein, but by introduction of a piece of human DNA. Thus the yeast cells could read and use this information correctly, indicating that, in eukaryotes, the molecular machinery for reading the information encoded in DNA must be similar from cell to cell and from organism to organism. A yeast cell has all the equipment it needs to interpret the instructions encoded in a human gene and to use that information to direct the production of a fully functional human protein.
The story of Cdc2 is just one of thousands of examples of how research in yeast cells has provided critical insights into human biology. Although it may sound paradoxical, the shortest, most efficient path to improving human health often begins with detailed studies of the biology of simple organisms such as brewer’s or baker’s yeast.
Humans are not mice—or fish or flies or worms or yeast. So to learn about human biology, many scientists directly study human beings themselves. Like bacteria or yeast, our individual cells can be harvested and grown in culture, where investigators can study their biology and more closely examine the genes that govern their functions. Given the appropriate surroundings, many human cell types—indeed, many cell types from other animals or from plants—will survive, proliferate, and even produce specialized properties in a culture dish. Experiments using such cultured cells are sometimes said to be carried out in vitro (literally, “in glass”) to contrast them with experiments on intact organisms, which are said to be carried out in vivo (literally, “in the living”).
Although not true for all cell types, many cells, when grown in culture—including those harvested from human tissue—continue to display the differentiated properties appropriate to their origin: fibroblasts, a major cell type in connective tissue, continue to secrete proteins that form the extracellular matrix; embryonic heart muscle cells “beat” spontaneously in the culture dish; nerve cells extend axons and make functional connections with other nerve cells; and epithelial cells join together to form continuous sheets, as they do inside the body (Figure 1–40 and Movie 1.7). Because cultured cells are maintained in a controlled environment, they are accessible to study in ways that are often not possible in vivo. For example, cultured cells can be exposed to known concentrations of hormones or growth factors, and the effects that these signal molecules have on the shape or behavior of the cells can be easily explored. Remarkably, certain human embryo cells can be coaxed into differentiating into multiple cell types, which can self-assemble into organlike structures that closely resemble a normal organ such as an eye or brain. Such organoids can be used to study developmental processes—and how they are derailed in certain human genetic diseases (discussed in Chapter 20).
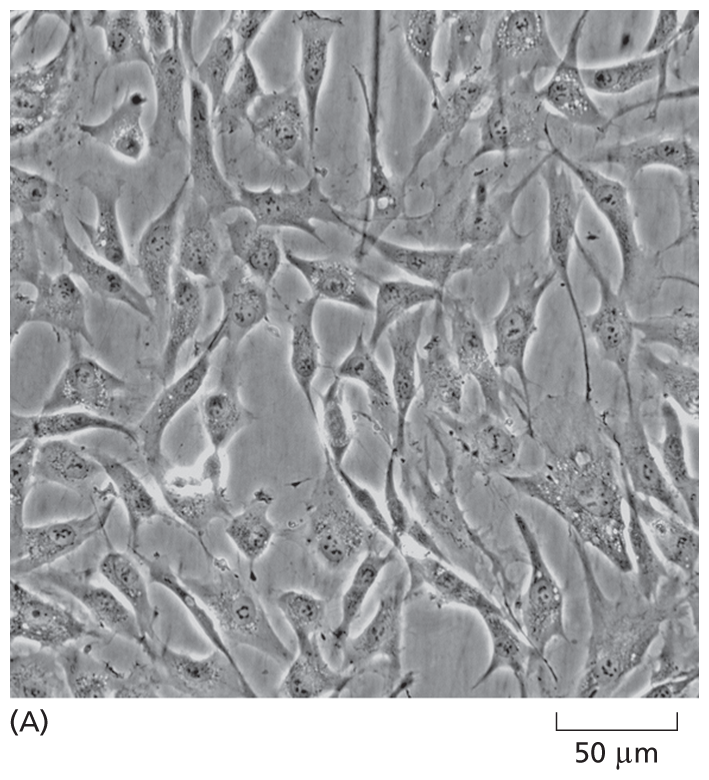
A micrograph shows spindle shaped cells from human skin; some of the cells are interconnected. The scale reads, 50 micrometers, and each cell is about that long.
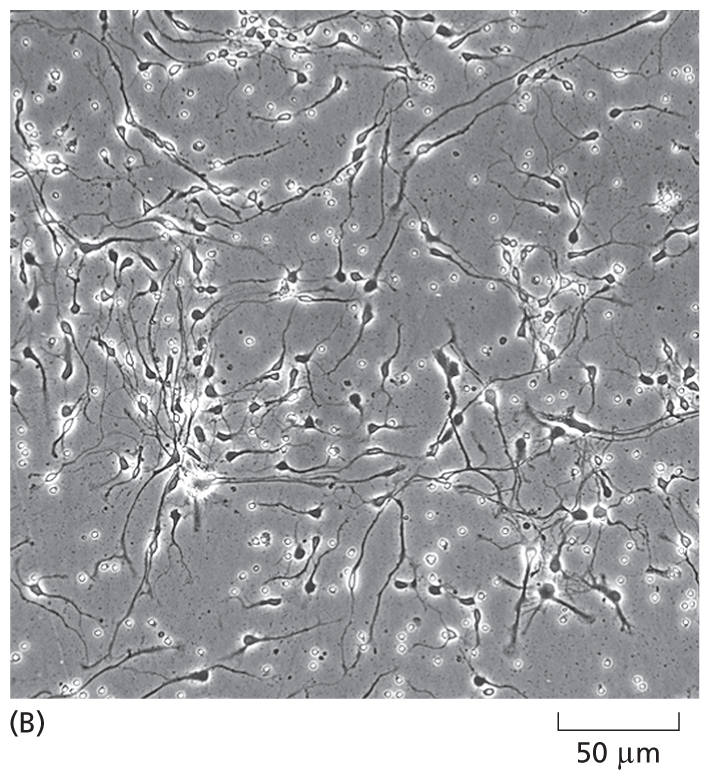
A micrograph shows interconnected human neurons on a scale of 50 micrometers. The cells have small cell bodies and long axons.
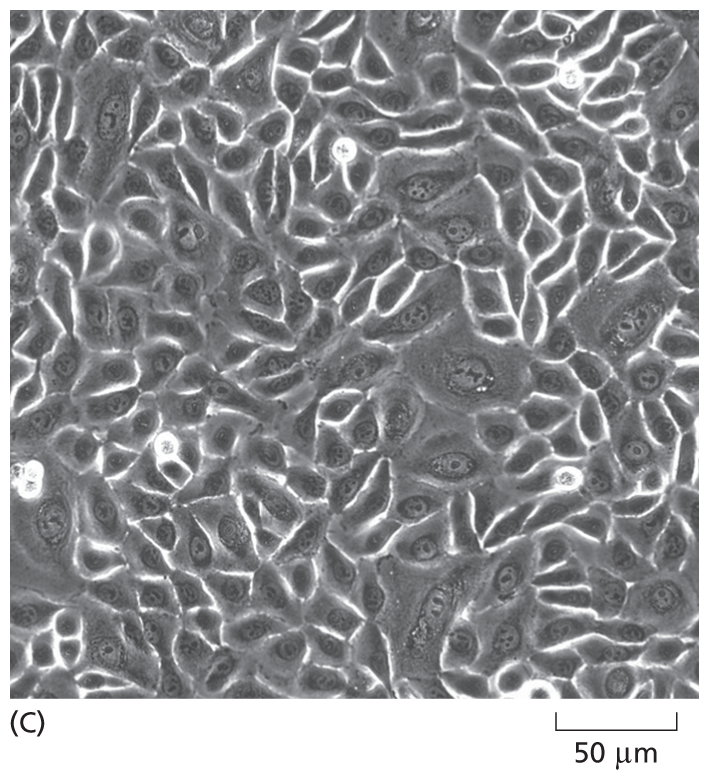
A micrograph shows closely packed scutoid shaped epithelial cells from a human cervix. The cells are each about 30 micrometers wide.
In addition to studying our cells in culture, humans are also examined directly in clinics. Much of the research on human biology has been driven by an interest in human health, and the medical database on the human species is enormous. Although naturally occurring, disease-causing mutations in any given human gene are rare, the consequences are well documented. This is because humans are unique among animals in that they report their own medical and genetic peculiarities: in no other species are billions of individuals so intensively examined, described, and investigated.
Even with thousands of biologists working tirelessly on the same set of model organisms, scientific progress operates at its own plodding pace: it can take decades before a discovery or observation shapes our understanding of basic biology—and even longer for this understanding to benefit human health. But on rare occasions, basic research can be translated into a clinical application in record time. A spectacular example of such rapid scientific success was the mobilization of resources to study SARS-CoV-2, the culprit behind the COVID-19 pandemic.
Viruses are particularly formidable foes because they infiltrate not just our bodies, but our cells. Once inside, they usurp our cellular machinery to replicate themselves, generating vast viral armies that can spread to other cells—and to other people, including our friends, families, and anyone else with whom we have close contact. As soon as the first cases of COVID-19 were detected, scientists isolated the virus responsible and determined the nucleotide sequence of its genome. This information revealed that the virus belongs to the coronavirus family, so-called because the fringe of proteins that bristle from the surface of these viruses look like the solar corona that surrounds the sun (Figure 1–41). Coronaviruses use these spike proteins to grab hold of—and then invade—the cells that line our respiratory tract; spike proteins therefore present an excellent target for thwarting viral infection.
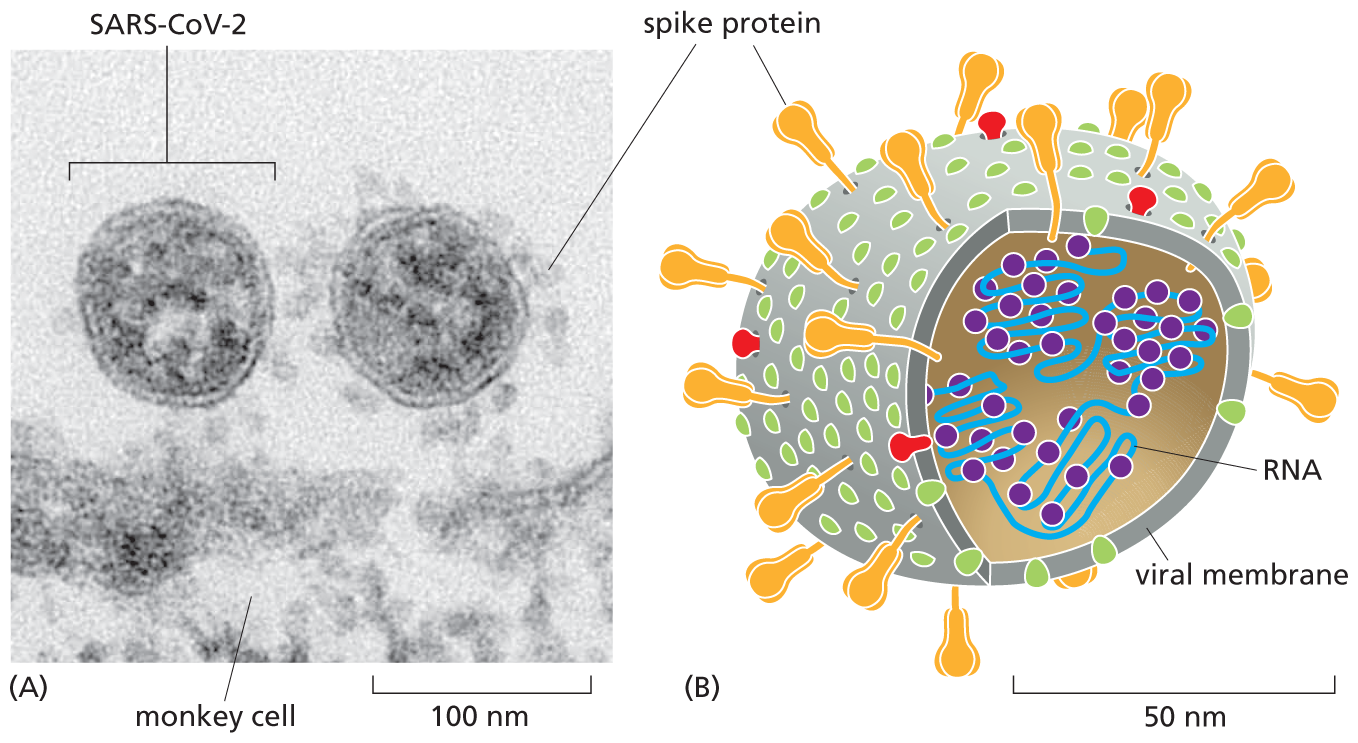
Parts A and B show a micrograph and an illustration of SARS Co V 2. The micrograph shows two SARS Co V 2 viruses next to a monkey cell. The illustration shows the structure of a SARS Co V 2 virus.
Figure 1–41 SARS-CoV-2 belongs to a family of coronaviruses. (A) An electron micrograph shows two SARS-CoV-2 viruses attached to the surface of a cultured monkey cell (which spans the bottom of the image). The spike proteins that adorn the surface of SARS-CoV-2 allow the viruses to recognize proteins on the surface of the host cell—and give coronaviruses their characteristic appearance. Because the spike protein is critical for the recognition and infiltration of host cells, it serves as the major target for all of the vaccines that have been designed to block SARS-CoV-2 infection. (B) A cutaway drawing of SARS-CoV-2 shows several of its key components, including the spike proteins that protrude from its surface (green) plus a type of protein (purple) that helps to package the viral genome (blue)—which is made of RNA rather than DNA—into new viral particles. We describe the life cycle of the virus, and how it propagates itself inside a host cell, in Chapter 9. (From M. Laue et al., Sci. Rep. 11:3515, 2021. With permission from Cold Spring Harbor Laboratory Press.)
Once the SARS-CoV-2 genome sequence was made public, biotech companies were able to identify the gene that encodes the spike protein and, within days, use this information to design a handful of candidate vaccines. These novel vaccines, the first of their kind, contain messenger RNAs (or mRNAs) that direct the body's cells to produce copies of the spike protein, which elicit a robust immune response. Within 2 months of the first diagnosis of COVID-19, mRNA vaccines were being tested in clinical trials; less than 1 year later, more than a billion doses had been administered worldwide.
In addition to fueling the speedy development of vaccines, the ability to quickly determine the nucleotide sequences of SARS-CoV-2 samples from infected individuals has provided a highly sensitive method to test for the virus. It also led to a better understanding of how SARS-CoV-2 operates. By comparing the genome sequences of SARS-CoV-2 samples collected in hospitals and nursing homes, investigators were able to determine that the virus could be spread by individuals who were asymptomatic. This finding led to the recommendations for masking and social distancing, policies that helped curb the explosion of cases before vaccines became available. Additional genetic comparisons will continue to shed light on what makes SARS-CoV-2 so harmful, whereas other closely related coronaviruses cause little more than a mild cold.
Although studies of this virus are still in their infancy, SARS-CoV-2 is well on its way to becoming a model system for understanding viruses that attack eukaryotic cells. The efforts to mine its genome for clues to its infectiousness will no doubt become a model for how scientific investigation can be rapidly deployed to detect, identify, and extinguish the next virus that threatens us, before it initiates a future pandemic.
If simple viruses that contain only a handful of genes are challenging to understand, it might seem impossible to ever unpack how our 20,000 protein-coding genes provide the instructions needed to produce our entire bodies, which contain thousands of billions of interdependent cells. Yet the revelations of molecular biology have made such questions seem eminently approachable. This optimism comes, in large part, from the realization that the genes of one type of animal have close counterparts in most other types of animals, apparently serving similar functions (Figure 1–42). We all have a common evolutionary origin, and under the surface it seems that we share the same molecular mechanisms. We therefore end this chapter by considering a little more closely the family relationships and genetic similarities among all living things. This topic has been dramatically clarified by technological advances that have allowed us to determine the complete genome sequences of thousands of organisms, including our own species (as discussed in more detail in Chapter 9).
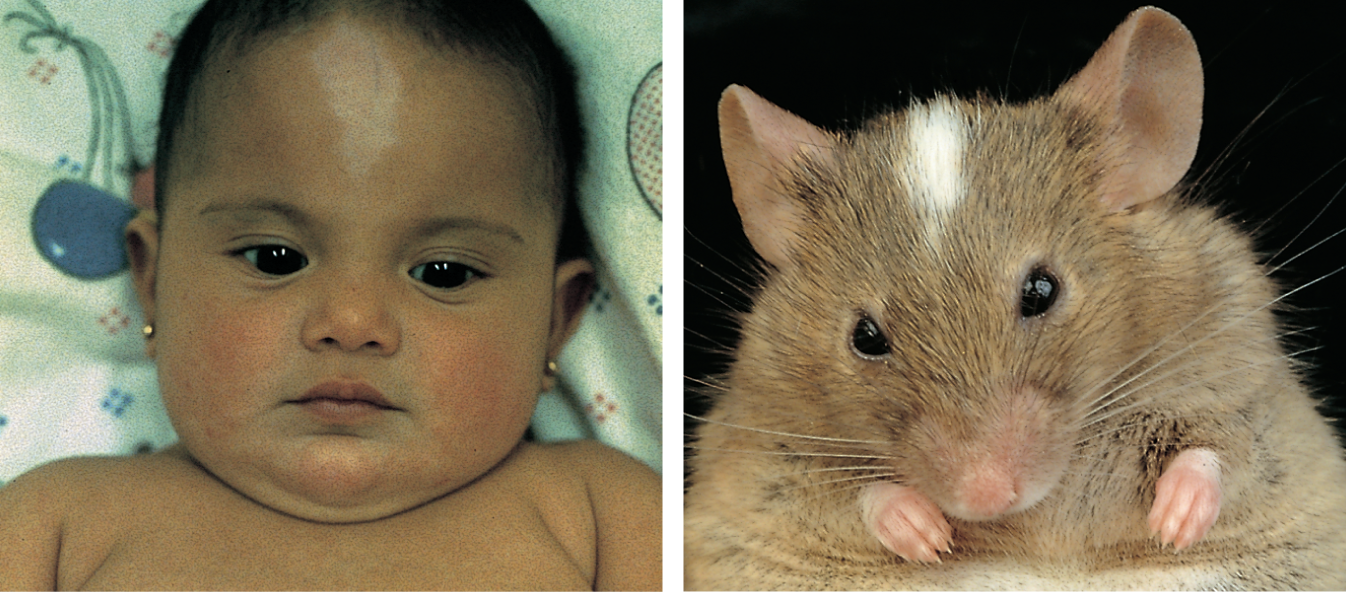
Two photos show a human baby and a mouse both with white patches on their foreheads.
Figure 1–42 Different species share similar genes. The human baby and the mouse shown here have remarkably similar white patches on their foreheads because they both have defects in the same gene (called Kit), which is required for the normal development, migration, and maintenance of some skin pigment cells. (Courtesy of R.A. Fleischman, from Proc. Natl. Acad. Sci. USA 88:10885–10889, 1991.)
The first thing we note when we look at an organism’s genome is its overall size and how many genes it packs into that length of DNA. (We review how genes are counted in Chapter 9.) Bacteria carry very little superfluous genetic baggage and, nucleotide for nucleotide, they squeeze a lot of information into their relatively small genomes. E. coli, for example, carries its genetic instructions in a single, circular, double-stranded molecule of DNA that contains 4.6 million nucleotide pairs and 4300 protein-coding genes. (We focus on the genes that code for proteins because they are the best characterized and the most abundant.) The simplest known bacterium contains only about 500 protein-coding genes, but most have genomes that contain at least 1 million nucleotide pairs and 1000–8000 protein-coding genes. With these few thousand genes, bacteria are able to thrive in even the most hostile environments on Earth.
In terms of total DNA, the compact genomes of bacteria are dwarfed by the sprawling genomes of eukaryotes. The human genome, for example, contains about 700 times more DNA than the E. coli genome, and the genome of an amoeba contains about 10 times more than ours (Figure 1–43). The rest of the model organisms we have described have genomes that fall somewhere between E. coli and humans in terms of size. S. cerevisiae contains about 2.5 times as much DNA as E. coli; D. melanogaster has about 10 times more DNA than S. cerevisiae; and the mouse, Mus musculus, has about 20 times more DNA than D. melanogaster (Table 1–2).
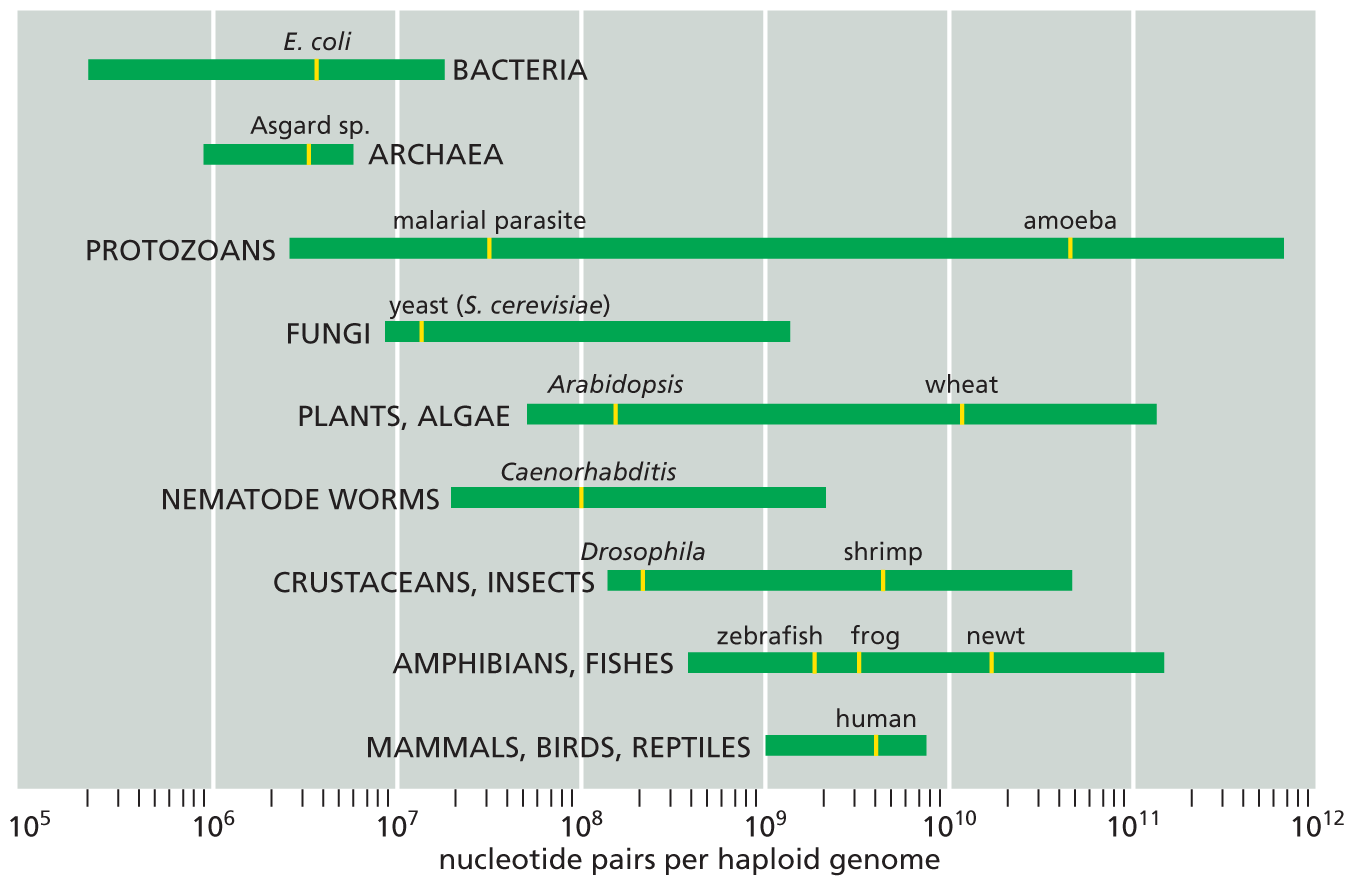
A chart shows genome size for different types of organisms with examples. The type of organism with examples and their nucleotide pairs per haploid genome are as follows: Bacteria, between 10 to fifth power and 10 to the eighth power. Example: Escherichia coli, between 10 to sixth power and 10 to the seventh power; Archaea, between 10 to the fifth power and 10 to the seventh power. Example: Halobacterium species, between 10 to the fifth power and 10 to the seventh power; Protozoans, between 10 to the sixth power and 10 to the twelfth power. Examples: malarial parasite, between 10 to the seventh power and 10 to the eighth power and amoeba, between 10 to the eleventh power and 10 to the twelfth power; Fungi, between 10 to the sixth power and 10 to the tenth power. Example: yeast (Saccharomyces cerevisiae) between 10 to seventh power and 10 to the eighth power; Plants and Algae, between 10 to the seventh power and 10 to the twelfth power. Examples: Arabidopsis, between 10 to the eighth power and 10 to the ninth power and wheat, between 10 to the tenth power and 10 to the eleventh power; Nematode worms, between 10 to the seventh power and 10 to tenth power. Example: Caenorhabditis, 10 to the eighth power; Crustaceans and Insects, between 10 to the eighth power and 10 to the eleventh power. Examples: Drosophilia, between 10 to the eighth power and 10 to the ninth power and Shrimp, between 10 to the ninth power and 10 to the tenth power; Amphibians and Fishes, between 10 to the eighth power and 10 to the twelfth power. Examples: Zebra fish, between 10 to the eighth power and 10 to the tenth power; Frog, between 10 to the ninth power and 10 to the tenth power; and newt, between 10 to the tenth power and 10 to the twelfth power; and Mammals, Birds, and Reptiles, between 10 to the ninth power and 10 to the tenth power. Example: human, between 10 to the ninth power and 10 to the tenth power.
Figure 1–43 Organisms vary enormously in the size of their genomes. Genome size is measured in nucleotide pairs of DNA per haploid genome; that is, per single copy of the genome. (The body cells of sexually reproducing organisms such as ourselves are generally diploid: they contain two copies of the genome, one inherited from the mother, the other from the father.) Closely related organisms can vary widely in the quantity of DNA in their genomes (as indicated by the length of the green bars), even though they contain similar numbers of functionally distinct genes; this is because most of the DNA in large genomes does not code for protein. (Data from T.R. Gregory, 2021, Animal Genome Size Database: www.genomesize.com.)
In terms of gene numbers, however, the differences are not as great. We have only about five times as many protein-coding genes as E. coli, for example. Moreover, many of our genes—and the proteins they encode—fall into closely related family groups, such as the family of hemoglobins, which has nine closely related members in humans. Thus the number of fundamentally different proteins in a human is not radically different from that in a bacterium, and the number of human genes that have identifiable counterparts in the bacterium is a significant fraction of the total.
This high degree of “family resemblance” is striking when we compare the genome sequences of different organisms. When genes from different organisms have very similar nucleotide sequences, it is highly probable that they descended from a common ancestral gene. Such genes (and their protein products) are said to be homologous. Now that we have the complete genome sequences of many different organisms from all three domains of life—archaea, bacteria, and eukaryotes—we can search systematically for homologies that span this enormous evolutionary divide to identify ancient genes that were in place before the three-way split in the tree of life. By taking stock of the common inheritance of all living things, scientists are attempting to trace life’s origins back to the earliest ancestral cells. We return to this topic in Chapter 9.
|
TABLE 1–2 SOME MODEL ORGANISMS AND THEIR GENOMES |
||
|
Organism |
Genome Size* (Nucleotide Pairs) |
Approximate Number of Protein-Coding Genes |
|
Homo sapiens (human) |
3100 × 106 |
20,000 |
|
Mus musculus (mouse) |
2800 × 106 |
20,000 |
|
Drosophila melanogaster (fruit fly) |
180 × 106 |
14,000 |
|
Arabidopsis thaliana (plant) |
135 × 106 |
27,000 |
|
Caenorhabditis elegans (nematode) |
100 × 106 |
20,000 |
|
Saccharomyces cerevisiae (yeast) |
12.5 × 106 |
6600 |
|
Escherichia coli (bacterium) |
4.6 × 106 |
4300 |
Although our view of genome sequences tends to be “gene-centric,” our genomes contain much more than just genes. The vast bulk of our DNA does not code for proteins or for functional RNA molecules. Instead, it includes a mixture of sequences that help regulate gene activity, plus sequences that seem to be dispensable. The large quantity of regulatory DNA contained in the genomes of eukaryotic multicellular organisms allows for enormous complexity and sophistication in the way different genes are brought into action at different times and places. Yet, in the end, the basic list of parts—the set of proteins that the cells can make, as specified by the DNA—is not much longer than the parts list of an automobile, and many of those parts are common not only to all animals, but also to the entire living world. So although biology is complex, it is not incomprehensibly so.
That DNA can program the growth, development, and reproduction of living cells and complex organisms is truly amazing. In the following chapters, we will explain what is known about how cells work—by examining their component parts, how these parts work together, and how the genome of each cell directs the manufacture of the parts the cell needs to function and to reproduce.
WHY TRUST SCIENCE?
From the eighteenth- and nineteenth-century battles over spontaneous generation to our current struggle to grapple with a deadly pandemic, science is not immune to controversy.
So how do scientists determine what’s “true”? And why should we trust what science tells us?
To understand how the scientific method produces knowledge on which we can rely—and, in the case of the COVID-19 pandemic, produced life-saving vaccines and treatments—visit our web resource at digital.wwnorton.com/ecb6.
This chapter outlines our central understanding of life processes. The acquisition of this knowledge has been very hard-earned—requiring more than a hundred years of research by many thousands of individual scientists. As illustrated by the nineteenth-century battle over the then-novel claim that “living organisms do not arise spontaneously but can be generated only from preexisting organisms,” disputes arise frequently in science. To be judged as credible, new findings must be reproduced by other scientists, and the claims of one scientist are often challenged by others. But eventually, through methods specifically designed to sort out the truth, the scientific community produces vast amounts of reliable knowledge.
The huge, firm platform of what is scientifically known about the world has been essential for improving the human condition. As just one example, it enabled the development of vaccines that have prevented hundreds of thousands of deaths during the COVID-19 pandemic (see the “How the Scientific Community Produces Reliable Knowledge” web resource).