QUESTION 2–7
What is meant by “polarity” of a polypeptide chain and by “polarity” of a chemical bond? How do the meanings differ?
On the basis of mass, macromolecules are by far the most abundant of the organic molecules in a living cell (Figure 2–29). They are the principal building blocks from which a cell is constructed and also the components that confer the most distinctive properties on living things. Intermediate in size and complexity between small organic molecules and organelles, macromolecules are constructed simply by covalently linking small organic monomers, or subunits, into long chains, or polymers (Figure 2–30 and How We Know, pp. 64–65). Yet they have many unexpected properties that could not have been predicted from their simple constituents. For example, it took a long time to determine how the nucleic acids, DNA and RNA, store and transmit hereditary information (see the How We Know section in Chapter 5, pp. 203–205).
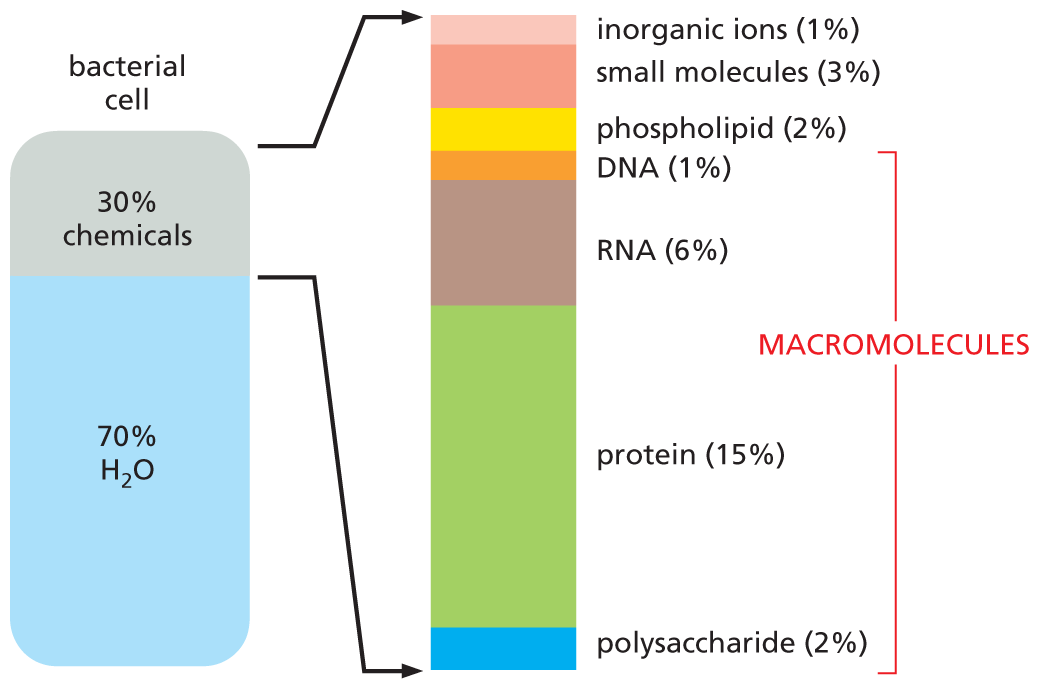
An illustration shows the approximate composition of a bacterial cell. About 70 percent of the bacterial cell is composed of water and 30 percent is composed of chemicals. An extended view shows the percent composition of different chemicals as follows: inorganic ions 1 percent, small molecules 3 percent; phospholipid 2 percent; D N A 1 percent; R N A 6 percent; protein 15 percent; and polysaccharide 2 percent. The D N A, R N A, protein, and polysaccharide components are labeled as macromolecules.
Figure 2–29 Macromolecules are abundant in cells. The approximate composition (by mass) of a bacterial cell is shown. The composition of an animal cell is similar.
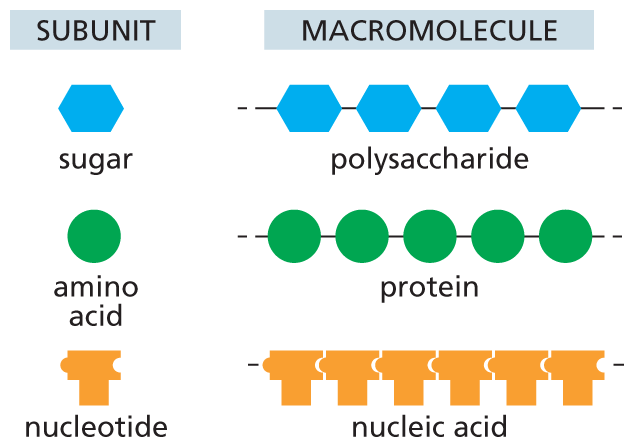
An illustration shows macromolecules and their corresponding subunits. A hexagon shaped subunit represents sugar. A chain of sugar subunits form a polysaccharide macromolecule.
A circular subunit represents amino acid. A chain of amino acid units form a protein macromolecule.
A T-shaped subunit represents nucleotide. A chain of nucleotides form a nucleic acid macromolecule.
Figure 2–30 Polysaccharides, proteins, and nucleic acids are made from monomeric subunits. Each macromolecule is a polymer formed from small molecules (called monomers or subunits) that are linked together by covalent bonds.
Proteins are especially versatile and they perform thousands of distinct functions. Many proteins act as highly specific enzymes that catalyze the chemical reactions that take place in cells. For example, an abundant enzyme in plants—called ribulose 1,5-bisphosphate carboxylase/oxygenase—plays a central role in the conversion of CO2 to sugars, which produces most of the organic matter used by the rest of the living world. Other proteins are used to build structural components: tubulin, for example, self-assembles to make the cell’s long, stiff microtubules (see Figure 1–27B), and histone proteins assemble into disc-like structures that help wrap up the cell’s DNA in chromosomes. Yet other proteins, such as myosin, act as molecular motors to produce force and movement. We examine the molecular basis for many of these wide-ranging functions in later chapters. Here, we consider some of the general principles of macromolecular chemistry that make all of these activities possible.
Although the chemical reactions for adding subunits to each polymer are different in detail for proteins, nucleic acids, and polysaccharides, they share important features. Each polymer grows by the addition of a monomer onto one end of the polymer chain via a condensation reaction, in which a molecule of water is lost for each subunit that is added (Figure 2–31). In all cases, the reactions are catalyzed by specific enzymes, which ensure that only the appropriate monomer is incorporated.
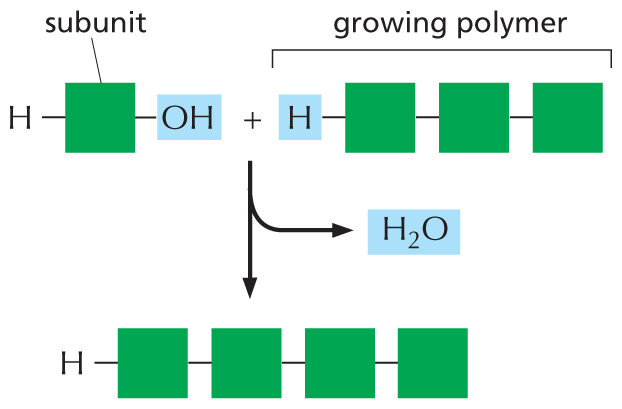
An illustration shows the addition of a subunit to a growing polymer. In the first molecule, a hydrogen atom is single bonded to a square shaped subunit which is further single bonded to a hydroxyl group. In the second molecule, a hydrogen atom is single bonded to a growing polymer chain of three single bonded subunits. In the resultant macromolecule, a hydrogen atom is single bonded to four subunits. A water molecule is released in the process.
Figure 2–31 Macromolecules are formed by adding subunits to one end of a chain. In a condensation reaction, a molecule of water is lost with the addition of each monomer to one end of the growing chain. The reverse reaction—the breakdown of the polymer—occurs by the addition of water (hydrolysis). The condensation reaction that produces a sugar polymer is shown in Figure 2–19. To see how condensation reactions produce a polypeptide or a polynucleotide, consult Panel 2–6 (p. 80) and Panel 2–7 (p. 83), respectively.
The stepwise polymerization of monomers into a long chain is a simple way to manufacture a large, complex molecule, because the subunits are added by the same reaction performed over and over again by the same set of enzymes. In a sense, the process resembles the repetitive operation of a machine in a factory—with some important differences. First, apart from some of the polysaccharides, most macromolecules are made from a set of monomers that are slightly different from one another; for example, proteins are constructed from 20 different amino acids (see Panel 2–6, pp. 80–81). Second, and most important, the polymer chain is not assembled at random from these subunits; instead, the subunits are added in a particular order, or sequence.
QUESTION 2–7
What is meant by “polarity” of a polypeptide chain and by “polarity” of a chemical bond? How do the meanings differ?
The biological functions of proteins, nucleic acids, and many polysaccharides are absolutely dependent on the particular sequence of subunits in the linear chains. By varying the sequence of subunits, the cell could in principle make an enormous diversity of the polymeric molecules. Thus, for a protein chain 200 amino acids long, there are 20200 possible combinations (20 × 20 × 20 × 20... multiplied 200 times), while for a DNA molecule 10,000 nucleotides long (small by DNA standards), with its four different nucleotides, there are 410,000 different possibilities—an unimaginably large number. Thus the machinery of polymerization must be subject to a sensitive control that allows it to specify exactly which subunit should be added next to the growing polymer end. We discuss the mechanisms that specify the sequence of subunits in DNA, RNA, and protein molecules in Chapters 6 and 7.
The idea that proteins, polysaccharides, and nucleic acids are large molecules constructed from smaller subunits, linked one after another into long molecular chains, may seem fairly obvious today. But this was not always the case. In the early part of the twentieth century, few scientists believed in the existence of biological polymers built from repeating units held together by covalent bonds. The notion that such “frighteningly large” macromolecules could be assembled from simple building blocks was, by some accounts, considered “downright shocking” by chemists of the day. Instead, they thought that proteins and other seemingly large organic molecules were simply heterogeneous aggregates of small organic molecules held together by weak “association forces” (Figure 2–32).
The first illustration shows a continuous polymer chain. Atoms are represented by green spheres securely attached to a winding chain,
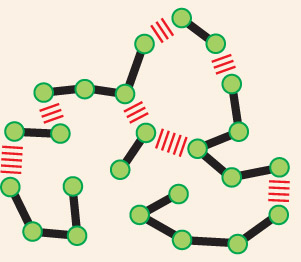
The second illustration shows individual molecules linked together by weak interactions. Small organic molecules are represented by green spheres loosely attached to other green spheres by hash marks along a winding chain.
The first hint that proteins and other organic polymers are large molecules came from observing their behavior in solution. At the time, scientists were working with various proteins and carbohydrates derived from foodstuffs and other organic materials—albumin from egg whites, casein from milk, collagen from gelatin, and cellulose from wood. Their chemical compositions seemed simple enough: like other organic molecules, they contained carbon, hydrogen, oxygen, and, in the case of proteins, nitrogen. But they behaved oddly in solution, showing, for example, an inability to pass through a fine filter.
Why these molecules misbehaved in solution was a puzzle. Were they really giant molecules, composed of an unusually large number of covalently linked atoms? Or were they more like a colloidal suspension of particles—a big, sticky hodgepodge of small organic molecules that associate only loosely?
One way to distinguish between the two possibilities was to determine the actual size of one of these molecules. If a protein such as albumin were made of molecules all identical in size, that would support the existence of true macromolecules. Conversely, if albumin were instead a miscellaneous conglomeration of small organic molecules, these should show a whole range of molecular sizes in solution.
Unfortunately, the techniques available to scientists in the early 1900s were not ideal for measuring the sizes of such large molecules. Some chemists estimated a protein’s size by determining how much it would lower a solution’s freezing point; others measured the osmotic pressure of protein solutions. These methods were susceptible to experimental error and gave variable results. Different techniques, for example, suggested that cellulose was anywhere from 6000 to 103,000 daltons in mass (where 1 dalton is approximately equal to the mass of a hydrogen atom). Such results helped to fuel the hypothesis that carbohydrates and proteins were loose aggregates of small molecules rather than true macromolecules.
Many scientists simply had trouble believing that molecules heavier than about 4000 daltons—the largest compound that had been synthesized by organic chemists—could exist at all. Take hemoglobin, the oxygen-carrying protein in red blood cells. Researchers tried to estimate its size by breaking it down into its chemical components. In addition to carbon, hydrogen, nitrogen, and oxygen, hemoglobin contains a small amount of iron. Working out the percentages, it appeared that hemoglobin had one atom of iron for every 712 atoms of carbon—and a minimum mass of 16,700 daltons. Could a molecule with hundreds of carbon atoms in one long chain remain intact in a cell and perform specific functions? Emil Fischer, the organic chemist who determined that the amino acids in proteins are linked by peptide bonds, thought that a polypeptide chain could grow no longer than about 30 or 40 amino acids. As for hemoglobin, with its purported 700 carbon atoms, the existence of molecular chains of such “truly fantastic lengths” was deemed “very improbable” by leading chemists.
Definitive resolution of the debate had to await the development of new techniques. Convincing evidence that proteins are macromolecules came from studies using the ultracentrifuge—a device that uses centrifugal force to separate molecules according to their size (see Panel 4–3, pp. 170–171). Theodor Svedberg, who designed the machine in 1925, performed the first studies. If a protein were really an aggregate of smaller molecules, he reasoned, it would appear as a smear of molecules of different sizes when sedimented in an ultracentrifuge. Using hemoglobin as his test protein, Svedberg found that the centrifuged sample revealed a single, sharp band. The finding strongly supported the theory that proteins are true macromolecules (Figure 2–33).
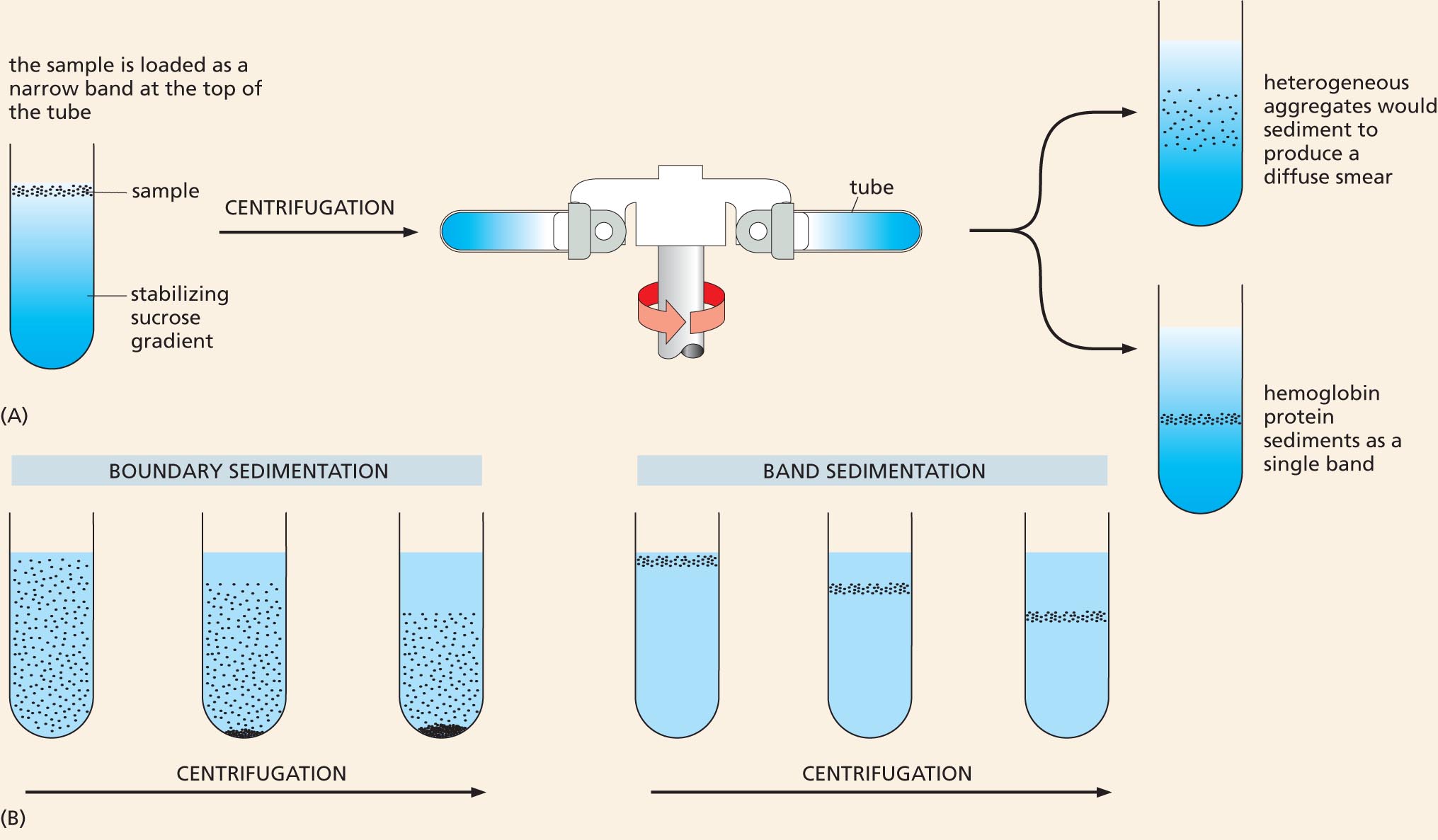
Two illustrations show the general process of ultracentrifugation and the resulting sedimentation types.
Figure 2–33 The ultracentrifuge helped to settle the debate about the nature of macromolecules. In the ultracentrifuge, centrifugal forces exceeding 500,000 times the force of gravity can be used to separate proteins or other large molecules. (A) In a modern ultracentrifuge, samples are loaded in a thin layer on top of a gradient of sucrose solution formed in a tube. The tube is placed in a metal rotor that is rotated at high speed in a vacuum. Molecules of different sizes sediment at different rates: larger and denser molecules experience the greatest centrifugal force and therefore move more rapidly. Molecules with a similar size and density will migrate at a similar rate, thereby forming a distinct band in the sample tube. If hemoglobin were a loose aggregate of heterogeneous peptides, it would show a broad smear of sizes after centrifugation (top tube). Instead, it appears as a single, sharp band (bottom tube); the molecules in this band have a mass of 68,000 daltons, reflecting the fact that hemoglobin consists of a tight complex of four polypeptide chains, each containing a single iron atom (see Figure 9–8)
Although the ultracentrifuge is now a standard, almost mundane, fixture in most biochemistry laboratories, its construction was a huge technological challenge. The centrifuge rotor must be capable of spinning centrifuge tubes at high speeds for many hours at constant temperature and with high stability to avoid disrupting the gradient and ruining the samples. In 1926, Svedberg won the Nobel Prize in Chemistry for his ultracentrifuge design and its application to chemistry. (B) In his actual experiment, Svedberg filled a special tube in the centrifuge with a homogeneous solution of hemoglobin; by shining light through the tube, he then carefully monitored the moving boundary between the sedimenting protein molecules and the clear aqueous solution left behind (so-called boundary sedimentation). The more recently developed method shown in (A) is a form of band sedimentation.
Additional evidence continued to accumulate throughout the 1930s, when other researchers were able to obtain crystals of pure protein that could be studied by x-ray diffraction. Only molecules with a uniform size and shape can form highly ordered crystals and diffract x-rays in such a way that their three-dimensional structure can be determined, as we discuss in Chapter 4. A heterogeneous suspension could not be studied in this way.
We now take it for granted that large macromolecules carry out many of the most important activities in living cells. But chemists once viewed the existence of such polymers with the same sort of skepticism that a zoologist might show on being told that “In Africa, there are elephants that are 100 meters long and 20 meters tall.” It took decades for researchers to develop the techniques required to convince everyone that molecules 10 times larger than anything they had ever encountered were a cornerstone of biology. As we shall see throughout this book, such a labored pathway to discovery is not unusual, and progress in science—as in the discovery of macromolecules—is often driven by advances in technology.
QUESTION 2–8
In principle, there are many different, chemically diverse ways in which small molecules can be joined together to form polymers. The individual subunits of the three major classes of biological macromolecules, however, are all linked by similar reaction mechanisms—that is, by condensation reactions that eliminate water. Can you think of any benefits that this chemistry offers and why it might have been selected in evolution over a linking chemistry that does not involve water?
Most of the covalent bonds that link together the subunits in a macromolecule allow rotation of the atoms that they join; thus the polymer chain has great flexibility. In principle, this allows a single-chain macromolecule to adopt an almost unlimited number of shapes, or conformations, as the polymer chain writhes and rotates under the influence of random thermal energy. However, the shapes of most biological macromolecules are highly constrained by the numerous weaker, noncovalent bonds that form between different parts of the molecule. These weaker interactions are the electrostatic attractions, hydrogen bonds, van der Waals attractions, and hydrophobic force that we described earlier (see Panel 2–3, pp. 74–75). In many cases, these noncovalent bonds ensure that the polymer chain preferentially adopts one particular conformation, determined by the linear sequence of monomers in the chain. Most protein molecules and many of the RNA molecules found in cells fold tightly into a highly preferred conformation in this way (Figure 2–34). These unique conformations—selected for and shaped by billions of years of evolution—determine the chemistry and activity of these macromolecules, dictating their specific interactions with other molecules in the cell.
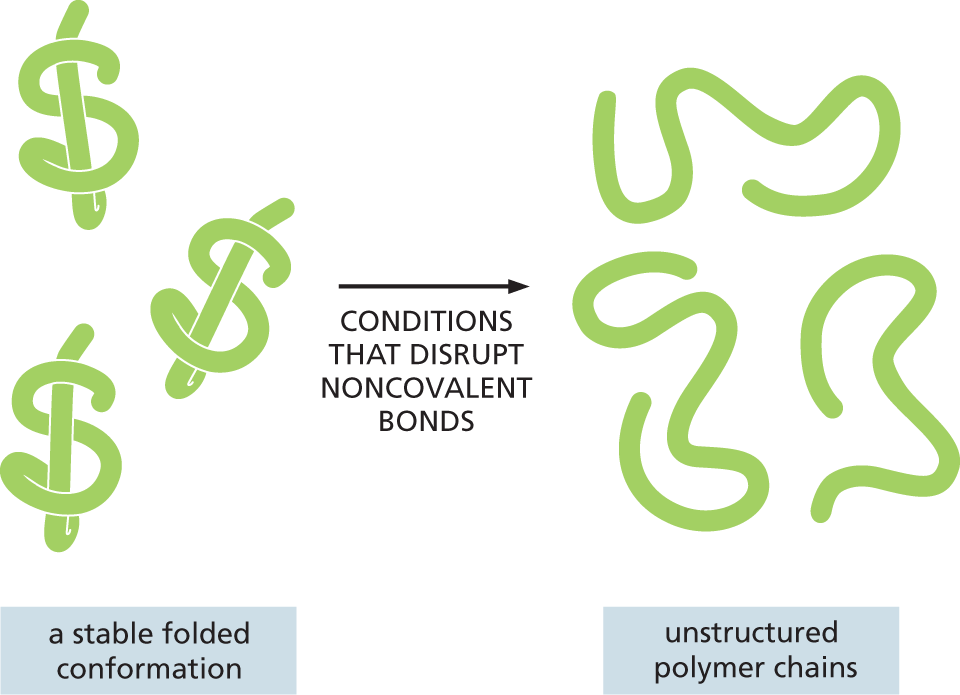
An illustration depicts conformational changes in proteins. A stable folded conformation of three protein molecules is subjected to conditions that disrupt noncovalent bonds to form unstructured polymer chains.
Figure 2–34 Most proteins and many RNA molecules fold into a particularly stable three-dimensional shape, or conformation. This shape is directed mostly by a multitude of weak, noncovalent, intramolecular bonds. If the folded macromolecules are subjected to conditions that disrupt noncovalent bonds, the molecule becomes a flexible chain that loses both its conformation and its biological activity.
As we discussed earlier, although noncovalent bonds are individually weak, they can add up to create a strong attraction between two molecules when these molecules fit together very closely, like a hand in a glove, so that many noncovalent bonds can occur between them (see Panel 2–3, pp. 74–75). This form of molecular interaction provides for great specificity in the binding of a macromolecule to other small and large molecules, because the multipoint contacts required for strong binding make it possible for a macromolecule to select just one of the many thousands of different molecules present inside a cell. Moreover, because the strength of the binding depends on the number of noncovalent bonds that are formed, associations of almost any strength are possible. As one example, binding of this type makes it possible for proteins to function as enzymes. Enzymes recognize their substrates via noncovalent bonds, and an enzyme that acts on a positively charged substrate will often use negatively charged amino acid side chains to guide the substrate to its proper position. We discuss such interactions in detail in Chapter 4.
QUESTION 2–9
Why could covalent bonds not be used in place of noncovalent bonds to mediate most of the interactions of macromolecules?
Noncovalent bonds can also stabilize associations between any two macromolecules, as long as their surfaces match closely (Figure 2–35). Such associations allow macromolecules to be used as building blocks for the formation of much larger structures. For example, proteins often bind together into multiprotein complexes that function as intricate machines with multiple moving parts, carrying out such complex tasks as DNA replication and protein synthesis (Figure 2–36). On a larger scale, these weak interactions among macromolecules can even drive the formation of functional subcompartments and membraneless organelles within the cell, a topic we discuss in later chapters. Noncovalent bonds therefore account for a great deal of the distinctive chemistry that makes life possible.
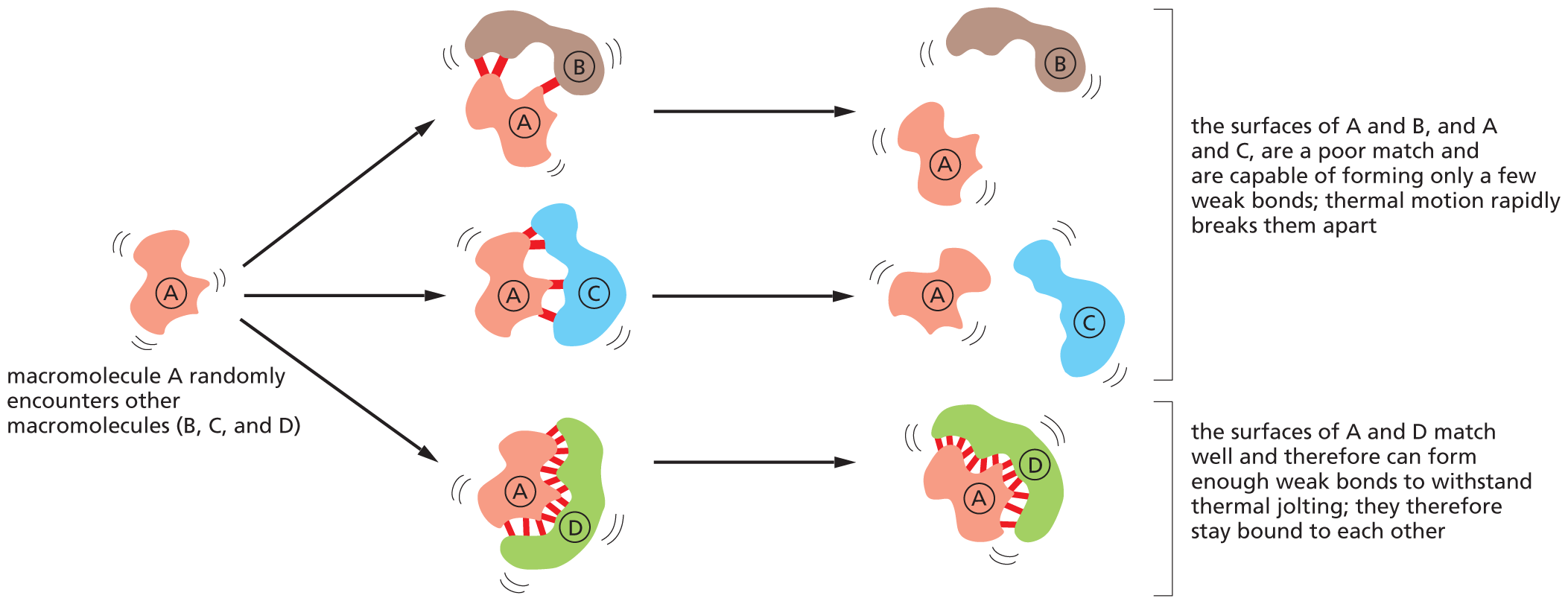
A flow diagram shows how noncovalent bonds mediate interactions between macromolecules. The macromolecule A randomly encounters the macromolecules B, C, and D. Three other units are formed; weak bonds are formed between A and B, A and C, and A and D. In the next step, the bonds between A-B and A-C break, resulting in the formation of separate protein units A and B, A and C. Corresponding text reads, the surface of A and B, and A and C, are a poor match and are capable of forming only a few weak bonds; thermal motion rapidly breaks them apart. The bond between A-D remains intact, hence the A-D protein complex continues to exist. Corresponding text reads, the surfaces of A and D match well and therefore can form enough weak bonds to withstand thermal jolting; they therefore stay bound to each other.
Figure 2–35 Noncovalent bonds mediate interactions between macromolecules and other molecules. The strength and duration of the interaction depends on the number of noncovalent bonds that form (Movie 2.4).
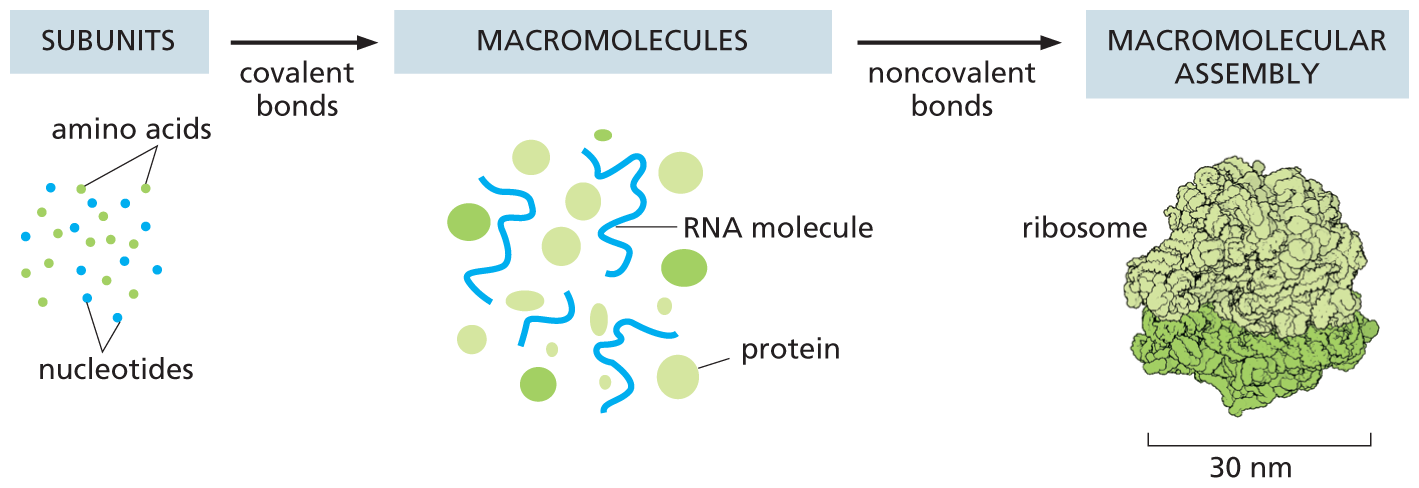
An illustration shows the assembly of subunits into macromolecules, then macromolecular assembly. The subunits such as amino acids and nucleotides form macromolecules such as R N A molecules and globular proteins via covalent bonds. The macromolecules form a macromolecular assembly: a ribosome of 30 nanometers via noncovalent bonds.
Figure 2–36 Both covalent bonds and noncovalent bonds are needed to form a macromolecular assembly such as a ribosome. Covalent bonds allow small organic molecules to join together to form macromolecules, which can assemble into large macromolecular complexes via noncovalent bonds. Ribosomes are large macromolecular machines that synthesize proteins inside cells. Each ribosome is composed of about 90 macromolecules (proteins and RNA molecules), and it is large enough to see in the electron microscope (see Figure 7–36). The subunits, macromolecules, and ribosome shown here are drawn roughly to scale.