THE UNIVERSAL FEATURES OF LIFE ON EARTH
There are more than 2 million described species living on Earth today, but many, many more are yet to be discovered. Each species is different, and each reproduces itself faithfully, yielding progeny that are unique to that species. Thus, the parent organism hands down information specifying, in extraordinary detail, the characteristics that the offspring will have. This phenomenon of heredity is central to the definition of life: it distinguishes life from other processes, such as the growth of a crystal, or the burning of a candle, or the formation of waves on water, in which structures are generated without the same type of link between the peculiarities of parents and offspring. A living organism must consume free energy to exist, as does a candle flame. But life employs this free energy to drive a very complex system of chemical reactions that create and maintain the intricate organization of its cells, all as specified by the hereditary information in those cells.
Most living organisms are single cells. Others, such as us, are like vast multicellular cities in which groups of cells perform specialized functions that are linked by intricate systems of intercellular communication. But even for the aggregate of more than 1013 cells that makes up a human body, the whole organism has been generated by cell divisions from a single cell. The single cell therefore contains all of the hereditary information that defines a species (Figure 1–1). The cell must also contain all of the machinery needed to gather raw materials from the environment and to construct from them a new cell in its own image, complete with a new copy of the hereditary information of its parent. Every cell on Earth is truly amazing.

All Cells Store Their Hereditary Information in the Form of Double-Strand DNA Molecules
Computers have made us familiar with the concept of information as a measurable quantity—106 bytes to record a few hundred pages of text or an image from a digital camera, 109 bytes for a 60-minute video streamed from the Internet, and so on. Computers have also made us well aware that the same information can be recorded in many different physical forms: the discs and tapes that we used 25 years ago for our electronic archives have become unreadable on present-day machines. Living cells, like computers, store information, and it is estimated that they have been evolving and diversifying for more than 3.5 billion years. One might not expect that they would all store their information in the same form or that the hereditary information carried by one type of cell should be readable by the information-handling machinery of another. And yet it is so. This fact provides compelling evidence that all living things on Earth have inherited the form of their genetic instructions, as well as how to use them, from a universal common ancestral cell. This ancestor is thought to have existed roughly 3.5–3.8 billion years ago.
All cells on Earth today store their hereditary information in the form of double-strand molecules of DNA—long, unbranched, paired polymer chains, which are always composed of the same four types of monomers. These monomers, chemical compounds known as nucleotides, have nicknames drawn from a four-letter alphabet—A, T, C, G—and they are strung together in a long linear sequence that encodes the hereditary information, just as the sequence of 1’s and 0’s encodes the information in a computer file. We can take a piece of DNA from a human cell and insert it into a bacterium or a piece of bacterial DNA and insert it into a human cell, and, with only a few minor modifications, the information will be successfully read, interpreted, and copied. As we describe in Chapter 8, scientists can now rapidly read out the sequence of nucleotides in any DNA molecule and thereby determine the complete DNA sequence of any cell’s genome—the totality of its hereditary information embodied in the linear sequence of nucleotides in its DNA. As a result, we now know the complete genome sequences for tens of thousands of species, ranging from the smallest bacterium to the largest plants and animals on Earth.
All Cells Replicate Their Hereditary Information by Templated Polymerization
The mechanisms that make life possible depend on the structure of the double-strand DNA molecule. We discuss this remarkable molecule in detail in Chapters 4 and 5; here we provide only an overview of its structure and means of reproduction. Each monomer in a single DNA strand—that is, each nucleotide—consists of two parts: a sugar (deoxyribose) with a phosphate group attached to it, and a base, which may be either adenine (A), guanine (G), cytosine (C), or thymine (T) (Figure 1–2). Each sugar is linked to the next via the phosphate group, creating a polymer chain composed of a repetitive sugar–phosphate backbone with a series of bases protruding from it. The DNA polymer is extended by adding monomers at one end. For a single isolated strand, these monomers can, in principle, be added in any order, because each one links to the next in the same way, through the part of the molecule that is the same for all of them. In the living cell, however, DNA is not synthesized as a free strand in isolation, but on a template formed by a preexisting DNA strand. The bases that protrude from this template can bind to bases of the strand being synthesized, according to a strict rule defined by the complementary structures of the bases: A binds to T, and C binds to G. This base-pairing holds fresh monomers in place and thereby controls the selection of which one of the four monomers will next be added to a growing strand. In this way, a double-strand structure is created, consisting of two exactly complementary sequences of A’s, C’s, T’s, and G’s. These two strands twist around each other, forming a DNA double helix (see Figure 1–2E).
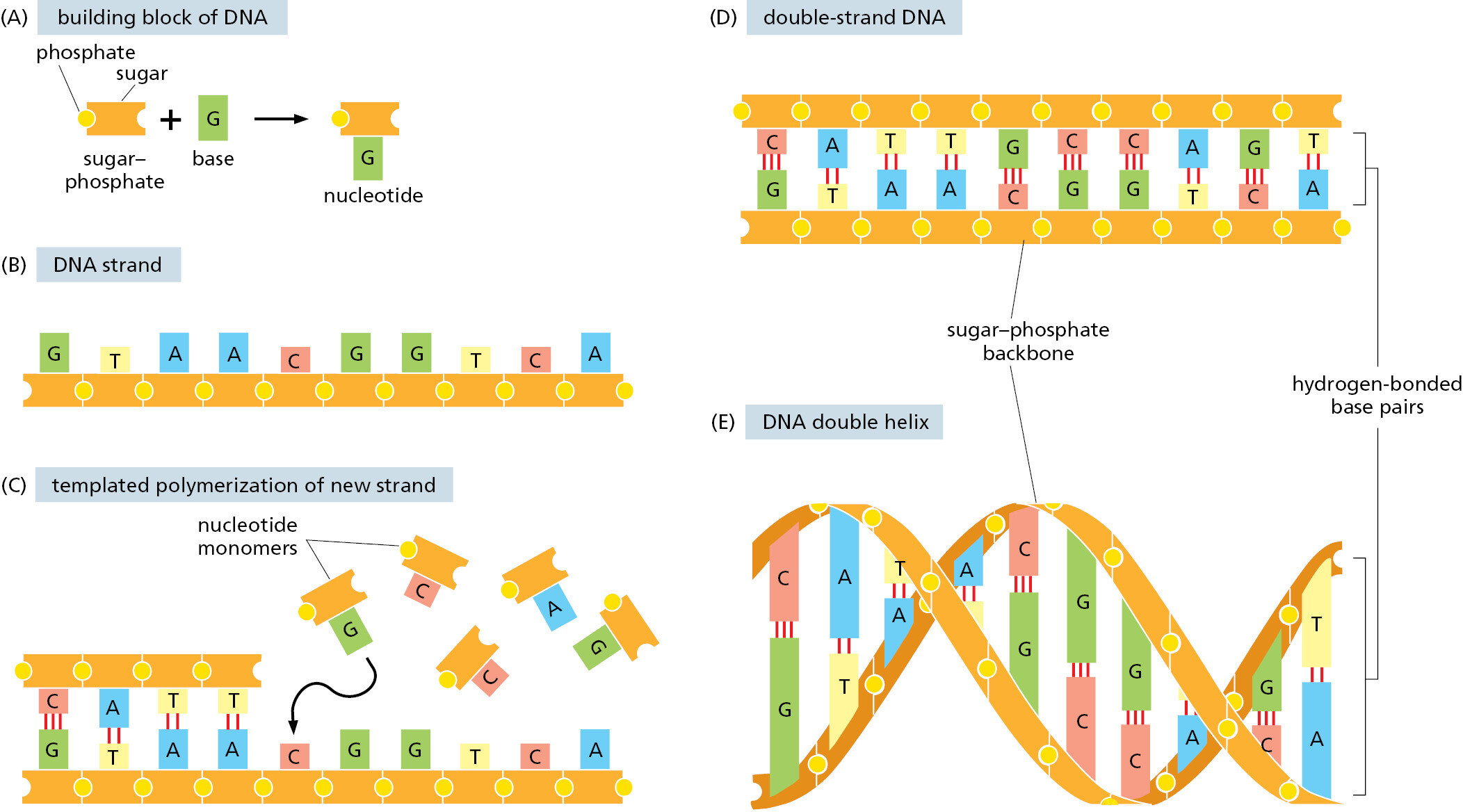
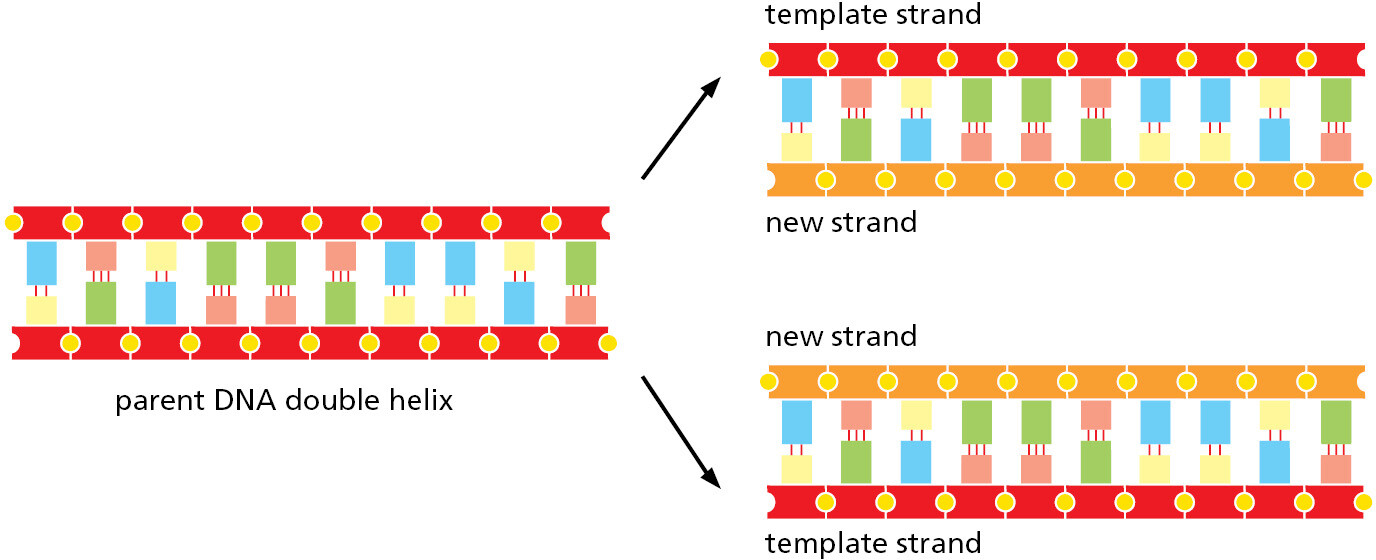
Compared with the covalent sugar–phosphate bonds, the hydrogen bonds between the base pairs are weak, which allows the two DNA strands to be pulled apart without breakage of their backbones. Each strand then can serve as a template, in the way just described, for the synthesis of a fresh DNA strand complementary to itself—a fresh copy, that is, of the hereditary information (Figure 1–3). In different types of cells, this process of DNA replication occurs at different rates, with different controls to start it or stop it, and with different auxiliary molecules to help the process along (discussed in Chapters 5 and 17). But the basics are universal: DNA is the information store for heredity, and templated polymerization is the way in which this information is copied throughout the living world.
All Cells Transcribe Portions of Their DNA into RNA Molecules
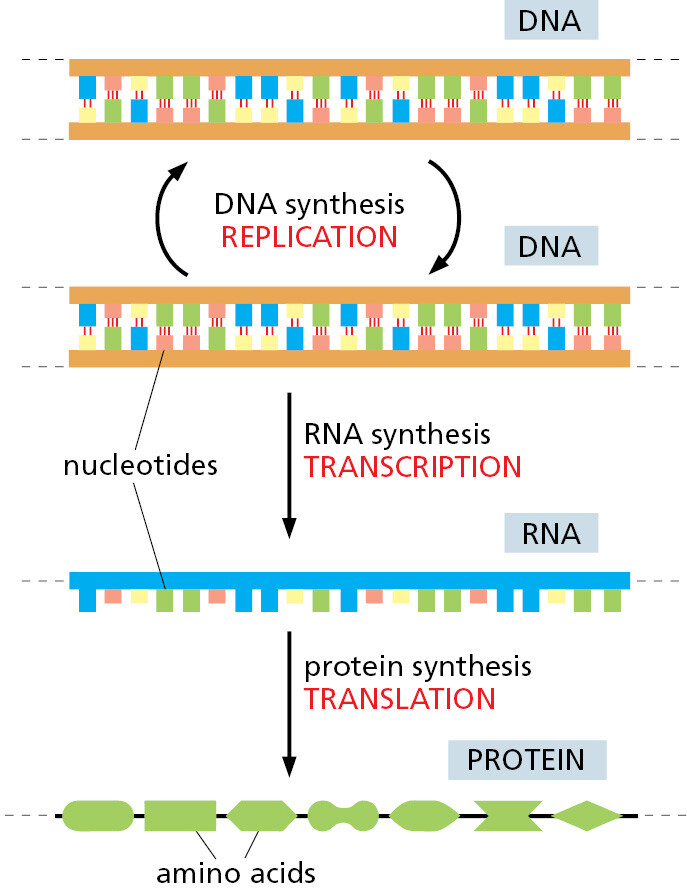
To carry out its information-bearing function, DNA must do more than copy itself. It must also express its information, by letting the information guide the synthesis of other molecules in the cell. This expression occurs by a mechanism that is the same in all living organisms, leading first and foremost to the production of two other crucial classes of biological polymers: RNA molecules and protein molecules. The process begins with a templated polymerization called transcription, in which segments of the DNA sequence are used as templates for the synthesis of shorter molecules of the closely related polymer ribonucleic acid, or RNA. Subsequently, in a process called translation, many of these RNA molecules direct the synthesis of polymers of a radically different chemical class—the proteins (Figure 1–4). The detailed chemical reactions involved are presented in Chapter 6; here they will only be briefly outlined.
The backbone of an RNA molecule is formed by a slightly different sugar from that in DNA—ribose instead of deoxyribose; in addition, one of the four bases is slightly different—uracil (U) replaces thymine (T). Most important, however, the other three bases—A, C, and G—are identical to those in DNA, and all four bases will pair with their complementary counterparts in DNA—the A, U, C, and G of RNA with the T, A, G, and C of DNA, respectively. During transcription, this pairing allows the RNA monomers to be lined up and selected for polymerization on a template strand of DNA, just as DNA monomers are selected during replication. The outcome is a single-strand polymer molecule whose sequence of nucleotides faithfully represents a portion of the cell’s genetic information, even though it is written in a slightly different alphabet—consisting of the four RNA monomers instead of the four DNA monomers.
The same segment of DNA can be used repeatedly to guide the synthesis of many identical RNA molecules. Thus, whereas the cell’s archive of genetic information in the form of DNA is fixed and sacrosanct, RNA transcripts are mass-produced and disposable. Most of these transcripts function as intermediates in the transfer of genetic information by serving as messenger RNA (mRNA) molecules that guide the synthesis of proteins according to the genetic instructions stored in the DNA. But as we discuss in Chapter 6, some RNA transcripts do not serve as information carriers; instead, they function directly in the cell to carry out a variety of other functions.
All Cells Use Proteins as Catalysts
Like DNA and RNA molecules, protein molecules are long unbranched polymer chains, formed by stringing together monomeric building blocks (subunits) drawn from a standard repertoire that is the same for all living cells. Like DNA and RNA, proteins carry information in the form of a linear sequence of subunits in the same way as a human message written in an alphabetic script. There are many different protein molecules in each cell, and—if we ignore water molecules—they form the major portion of the cell’s mass.
The subunits of proteins are the amino acids, which are quite different from the nucleotides of DNA and RNA, and there are 20 types instead of 4. Each amino acid is built around a core structure that allows it to be covalently linked in a standard way to any other amino acid in the set; attached to this core is a side group of atoms that gives each amino acid a distinctive chemical character. Each protein molecule is a polypeptide chain that is created by joining its amino acids in a particular sequence; this sequence determines how the polypeptide folds up, giving the protein its unique three-dimensional structure. Through several billion years of evolution, these sequences have been selected to give each protein a useful function.
By folding into a precise structure that binds with high specificity to other molecules, each protein performs a specific function according to its genetically specified sequence of amino acids. Proteins form and maintain diverse cell and extracellular structures, generate movements, sense signals, and so on. Many have reactive sites on their surface, allowing them to act as enzymes that catalyze reactions that make or break specific covalent bonds. Proteins, above all, are the main molecules that put the cell’s genetic information into action. Thus, polynucleotides (DNA and mRNAs) specify the amino acid sequences of proteins. Proteins, in turn, serve as catalysts to cause many different chemical reactions to occur, including those that synthesize new DNA and RNA molecules.
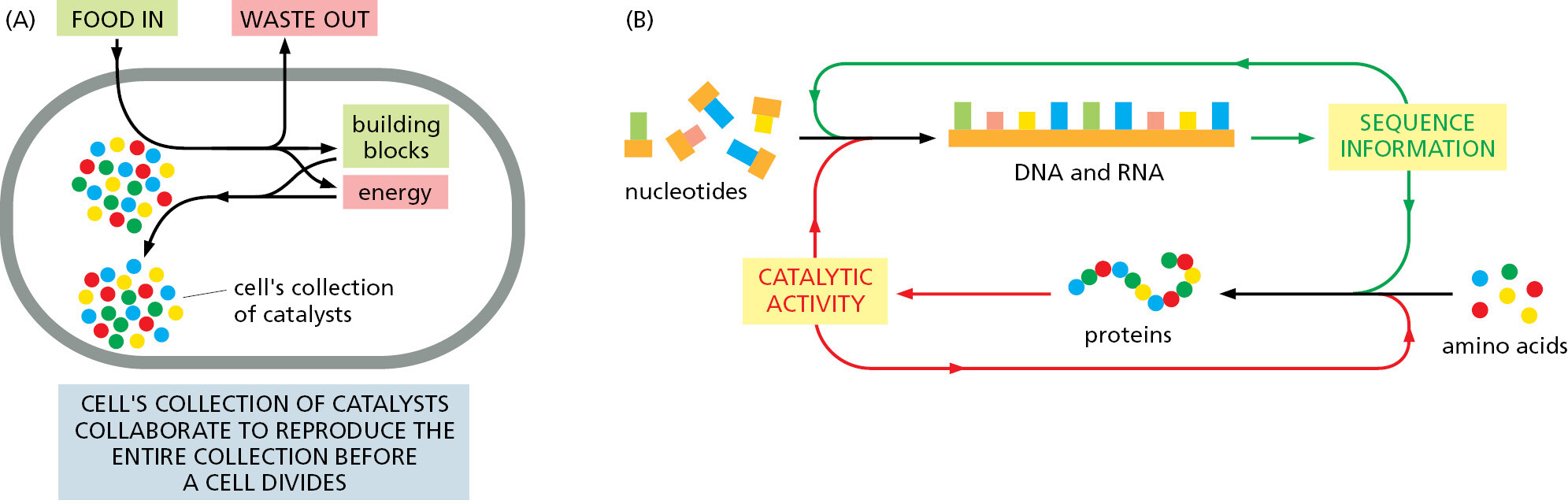
In everyday speech, a catalyst refers to “any agent that provokes or speeds significant change or action.” But in chemistry, the term catalyst is defined more narrowly, being applied to any molecule that speeds up a specific chemical reaction without itself being changed. From the most fundamental point of view, a living cell is a self-replicating collection of catalysts that takes in food, processes this food to provide both the building blocks and energy needed to make more catalysts, and discards the materials left over as waste (Figure 1–5A). Together, these feedback loops that connect proteins and polynucleotides form the basis for this autocatalytic, self-reproducing behavior of all living organisms (Figure 1–5B).
All Cells Translate RNA into Protein in the Same Way
How the information in DNA specifies the production of proteins was a complete mystery in the 1950s when the double-strand structure of DNA was first revealed as the basis of heredity. But in subsequent years, scientists discovered the elegant mechanisms involved. The translation of genetic information from the 4-letter alphabet of polynucleotides into the 20-letter alphabet of proteins is a complex process. The rules of this translation seem in some respects neat and rational but in other respects strangely arbitrary, given that they are (with minor exceptions) identical in all living things. These arbitrary features, it is thought, reflect frozen accidents in the early history of life. They stem from the chance properties of the earliest organisms that were passed on by heredity and have become so deeply embedded in the constitution of all living cells that they cannot be changed without disastrous consequences.
It turns out that the information in the sequence of a messenger RNA (mRNA) molecule is read out in groups of three nucleotides at a time: each triplet of nucleotides, or codon, specifies (codes for, or encodes) a single amino acid in a corresponding protein. Because the number of distinct triplets that can be formed from four nucleotides is 43, there are 64 possible codons, all of which occur in nature. However, there are only 20 naturally occurring amino acids, which means there are necessarily many cases in which several codons correspond to the same amino acid. This genetic code is read out by a special class of small RNA molecules, called transfer RNAs (tRNAs). Each type of tRNA becomes attached at one end to a specific amino acid and displays at its other end a specific sequence of three nucleotides—an anticodon—that enables it to recognize, through base-pairing, a particular codon or subset of codons in mRNA. The intricate chemistry that enables these tRNAs to translate a specific sequence of A, C, G, and U nucleotides in an mRNA molecule into a specific sequence of amino acids in a protein molecule occurs on a ribosome, a large multimolecular machine composed of both protein and ribosomal RNA. All of these processes will be described in detail in Chapter 6.
Each Protein Is Encoded by a Specific Gene
DNA molecules as a rule are very large, containing the specifications for thousands of proteins and RNA molecules. Special sequences in the DNA serve as punctuation, defining where the information for each RNA and protein begins and ends. And individual segments of the long DNA sequence are transcribed into separate mRNA molecules, coding for different proteins. Each such DNA segment represents one gene. As previously mentioned, some DNA segments—a smaller number—are transcribed into RNA molecules that are not translated into protein but have other functions in the cell; such DNA segments also count as genes. A gene therefore is defined as the segment of DNA sequence corresponding either to a single protein (but sometimes to a set of closely related, alternative protein variants) or to a single catalytic, regulatory, or structural RNA molecule.
In all cells, the expression of individual genes is regulated: instead of manufacturing its full repertoire of possible proteins and RNAs at full tilt all the time, the cell adjusts the rate of transcription and translation of different genes independently, according to need. As we shall see in Chapter 7, stretches of regulatory DNA are interspersed among the segments that code for protein, and these noncoding regions bind to special protein molecules that control the rate of transcription of individual genes. The organization of this regulatory DNA varies widely from one class of organisms to another, but the basic strategy is universal. In this way, the genome of the cell dictates not only the nature of the cell’s proteins but also when and where they are to be made.
Life Requires a Continual Input of Free Energy
A living cell is a dynamic chemical system, operating far from chemical equilibrium. For a cell to grow or to make a new cell in its own image, it must take in free energy from the environment, as well as raw materials, to drive the necessary synthetic reactions. This consumption of free energy is fundamental to life. When this energy is not available, a cell decays toward chemical equilibrium and soon dies.
As one example, free energy is required for the propagation of genetic information. Picture the molecules in a cell as a swarm of objects endowed with thermal energy, moving around violently at random, buffeted by collisions with one another. To copy genetic information—in the form of a DNA sequence, for example—nucleotide molecules from this wild crowd must be captured, arranged in a specific order defined by a preexisting template, and linked together in a fixed relationship. The bonds that hold the nucleotides in their proper places on the template and join them together must be strong enough to resist the disordering effect of thermal motion, which we describe shortly. The joining process is driven forward by a consumption of free energy, which is needed to ensure that the correct bonds are made, and made robustly. As an analogy, the molecules might be compared with spring-loaded traps, ready to snap into a more stable, lower-energy attached state when they meet their proper partners. As they snap together into the bonded arrangement, their available stored energy—their free energy—like the energy of the spring in the trap, is released and dissipated as heat. In a cell, the chemical processes underlying information transfer are more complex, but the same basic principle applies: free energy must be spent for the creation of order.
To replicate its genetic information faithfully, and indeed to make all its complex molecules according to the correct specifications, the cell therefore requires free energy, which has to be imported somehow from the surroundings. As we will discuss in detail in Chapter 2, the free energy required by animal cells is derived from chemical bonds in food molecules that the animals eat, whereas plants get their free energy from sunlight.
All Cells Function as Biochemical Factories
Because all cells make DNA, RNA, and protein, they all have to contain and manipulate a similar collection of small organic (carbon-containing) molecules, including simple sugars, nucleotides, and amino acids, as well as other substances that are universally required. All cells, for example, require the phosphorylated nucleotide ATP (adenosine triphosphate), not only as a building block for the synthesis of DNA and RNA but also as a carrier of the free energy that is needed to drive a huge number of chemical reactions in the cell.
Although all cells function as biochemical factories of a broadly similar type, many of the details of their small-molecule transactions differ. Plants, for example, require only the simplest of nutrients because they harness the energy of sunlight to make all their own small organic molecules. Other organisms, such as animals and some bacteria, feed on living (or once living) organisms and must obtain many of their organic molecules ready-made. We return to this point later in the chapter.
All Cells Are Enclosed in a Plasma Membrane Across Which Nutrients and Waste Materials Must Pass
Each living cell is enclosed by a membrane—the plasma membrane. This membrane acts as a selective barrier that enables the cell to concentrate nutrients gathered from its environment and retain the products it synthesizes for its own use, while excreting its waste products. Without a plasma membrane, the cell could not maintain its integrity as a coordinated chemical system.
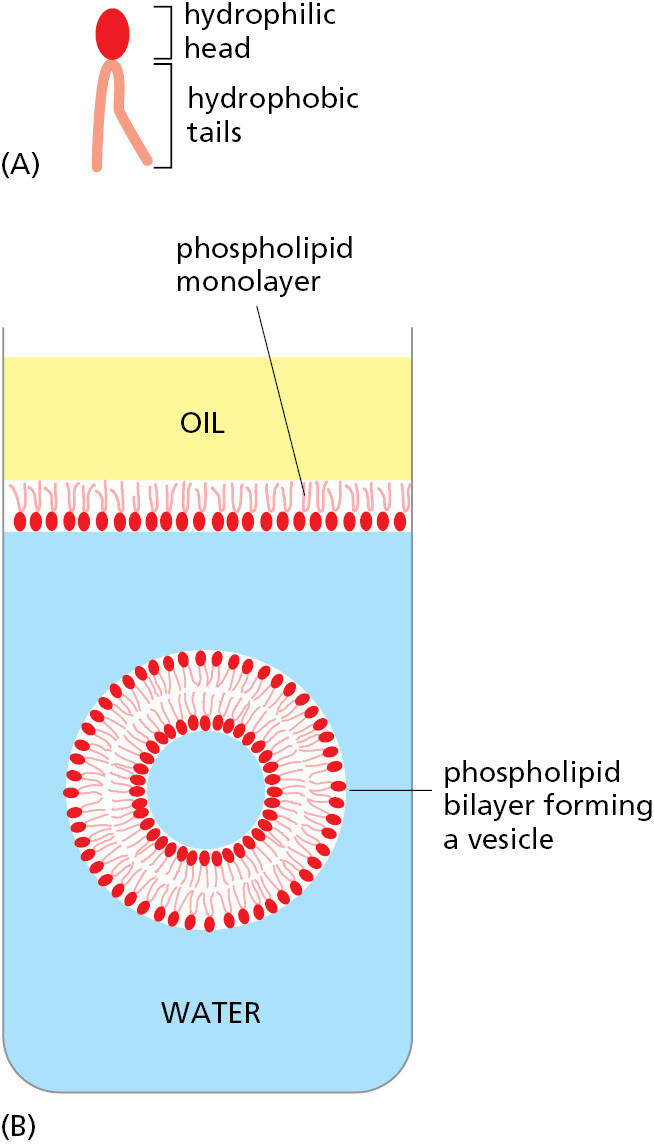
The molecules that form cell membranes have the simple physicochemical property of being amphiphilic; that is, they consist of one part that is hydrophilic (water-soluble) and another part that is hydrophobic (water-insoluble). Such molecules placed in water aggregate spontaneously, arranging their hydrophobic portions to be as much in contact with one another as possible to hide them from the water, while keeping their hydrophilic portions exposed. Amphiphilic molecules of appropriate shape, such as the phospholipid molecules that compose most of the molecules of the plasma membrane, spontaneously aggregate in water to create a bilayer that forms small closed vesicles (Figure 1–6).
Although the chemical details vary, the hydrophobic tails of the predominant lipid molecules in all cells are hydrocarbon polymers (–CH2–CH2–CH2–), and their spontaneous assembly into a lipid bilayer is but one of many examples of an important general principle: cells produce molecules whose chemical properties cause them to self-assemble into the structures that a cell needs.
The cell boundary cannot be totally impermeable. If a cell is to grow and reproduce, it must be able to import raw materials and export waste across its plasma membrane. All cells therefore have specialized proteins embedded in their plasma membrane that transport specific molecules from one side to the other. Some of these membrane transport proteins, like some of the proteins that catalyze the fundamental small-molecule reactions inside the cell, have been so well conserved over the course of evolution that we can recognize the family resemblances between them when even the most distantly related organisms are compared.
The transport proteins in the plasma membrane largely determine which molecules enter the cell, while the catalytic proteins (enzymes) inside the cell determine the reactions that the entering molecules undergo. Thus, by specifying the RNAs and proteins that the cell produces, the genetic information recorded in the DNA sequence dictates the entire chemistry of the cell—in fact, not only its chemistry but also its form and its behavior, for these too are chiefly determined and controlled by the cell’s proteins.
Cells Operate at a Microscopic Scale Dominated by Random Thermal Motion
Thus far we have described the cell as a self-replicating, membrane-bound bag of chemicals and macromolecules; but, as the unit of life, the cell is much more than the sum of its parts. Although not obvious from microscopy images, even the simplest cell is highly ordered internally: its individual components must self-assemble and become highly organized for the cell to function. And the cell contents are in perpetual motion. The most obvious movements are catalyzed by motor proteins, enzymes that use the energy of ATP hydrolysis for a wide variety of purposes; these include pumping ions across the plasma membrane, translocating large assemblies from one intracellular site to another, and propelling the cell through its environment. In addition, and as previously mentioned, random thermal motions of molecules (including water) are prominent at the scale of cells—whose dimensions can be as small as a micrometer (10–6 meters) in diameter. This type of spontaneous movement, called thermal or Brownian motion, was first observed by Robert Brown in 1827, while looking through a microscope at pollen grains immersed in water. Caused by random molecular collisions, the constant fluctuating movement has important repercussions. Brownian motion drives a process called diffusion, and it determines the rates of biochemical reactions as molecules collide with one another within the interior of a cell (described in Chapter 2; see Movie 2.4).
Even though random, the cell can harness Brownian motion for its own advantage. For example, during one step in the crawling migration of animal cells, the plasma membrane at the leading edge extends forward (see Chapter 16). This movement does not involve motor proteins. Instead, a cytoskeletal filament (an actin polymer) polymerizes adjacent to the inner membrane surface. When the membrane fluctuates in the forward direction, actin quickly fills in the gap so that the membrane cannot slip back to its original position. This phenomenon, in which random thermal motions are harnessed in a directed way, creates a Brownian ratchet (Figure 1–7).
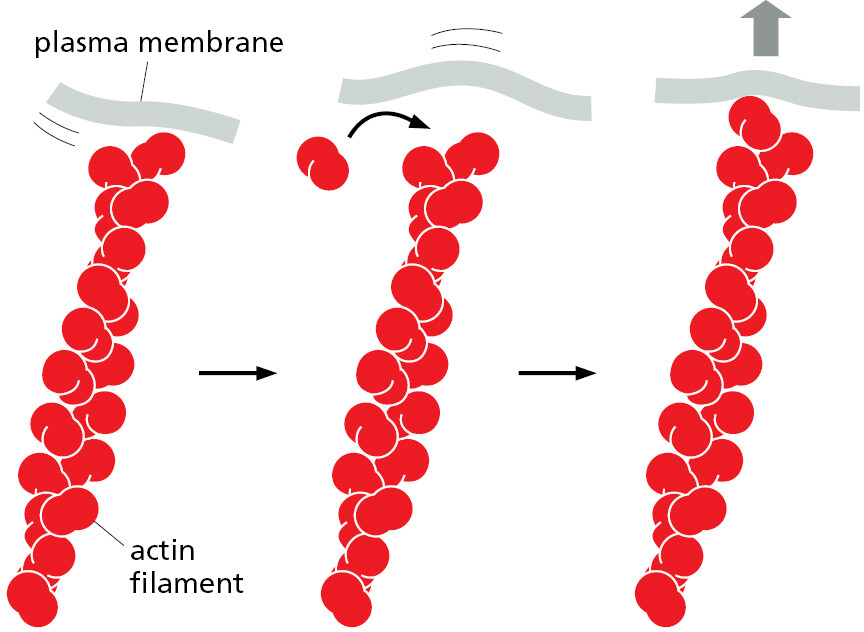
Because an object at the micrometer scale is constantly buffeted by water molecules, its movement requires overcoming high viscous drag forces. As a result, the directed movement of a complex of molecules inside the cell (by a motor protein, for example) will stop immediately when the motor disengages, leaving the complex to be randomly buffeted by thermal motion. There is no “gliding” inside the cell.
A Living Cell Can Exist with 500 Genes
We have seen how genomes carry the information for all the proteins and RNA molecules of a cell, and how, through catalysis, all the other building blocks of the cell are made. But how complex are real living cells? In particular, what are the minimum requirements of a living cell? One measure of complexity is based on the total number of genes in an organism’s genome. A species that has one of the smallest known genomes is the bacterium Mycoplasma genitalium, which causes a common, sexually transmitted, human disease (Figure 1–8). This organism lives as a parasite in mammals, where the environment provides it with many of the small molecules it needs ready-made. Nevertheless, it still has to make all the large molecules—DNA, RNAs, and proteins. It has 525 genes, most of which are essential. Its genome of 580,070 nucleotide pairs represents 145,018 bytes of information—about as much as it takes to record the text of one chapter of this book. Cell biology may be complicated, but it is not unimaginably so.
Summary
The individual cell is the minimal self-reproducing unit of life. A cell consists of a self-replicating collection of catalysts, enclosed in a plasma membrane. All cells operate as biochemical factories, driven by the free energy released in a complicated network of chemical reactions. Central to a cell’s ability to reproduce is the transmission of its genetic information to its progeny cells when it divides. All cells store their genetic information in double-strand DNA, and the complete sequence of DNA nucleotides for each organism is known as its genome. The cell replicates this information by separating the paired DNA strands and using each as a template for polymerization to make a new DNA strand with a complementary sequence of nucleotide subunits. The same strategy of templated polymerization is used in the transcription of portions of the DNA into molecules of the closely related polynucleotide polymer, RNA. Most of these RNA molecules are mRNAs that in turn guide the synthesis of protein molecules by the process of translation. Proteins are polymers of amino acid subunits and are the catalysts for almost all the cell’s chemical reactions. They are also responsible for the selective import and export of molecules across the plasma membrane that surrounds each cell. The specific shape and function of each protein depend on its amino acid sequence, which is specified by the nucleotide sequence of a corresponding segment of the DNA—the gene that codes for that protein. In this way, the DNA of the cell determines the cell’s chemistry, which is fundamentally similar in all cells, reflecting their ultimate origin from a common ancestor cell that existed on Earth more than 3.5 billion years ago.
Glossary
- genome
- The totality of genetic information belonging to a cell or an organism; in particular, the DNA that carries this information.
- nucleotide
- Nucleoside with a phosphate group joined in ester linkage to the sugar moiety. DNA and RNA are polymers of nucleotides.
- DNA replication
- Process by which a copy of a DNA molecule is made.
- DNA transcription
- Copying of one strand of DNA into a complementary RNA sequence by the enzyme RNA polymerase.
- ribonucleic acid
- Polymer formed from covalently linked ribonucleotide monomers. See also messenger RNA, ribosomal RNA, transfer RNA.
- translation (RNA translation)
- Process by which the sequence of nucleotides in an mRNA molecule directs the incorporation of amino acids into protein. Occurs on a ribosome.
- Wnt protein
- The major macromolecular constituent of cells. A linear polymer of amino acids linked together by peptide bonds in a specific sequence.
- amino acid
- Organic molecule containing both an amino group and a carboxyl group. Those that serve as building blocks of proteins are alpha amino acids, having both the amino and carboxyl groups linked to the same carbon atom.
- catalyst
- Substance that can lower the activation energy of a reaction (thus increasing its rate), without itself being consumed by the reaction.
- gene
- Region of DNA that is transcribed as a single unit and carries information for a discrete hereditary characteristic, usually corresponding to (1) a single protein (or set of related proteins generated by variant post-transcriptional processing) or (2) a single RNA (or set of closely related RNAs).
- plasma membrane
- The membrane that surrounds a living cell.
- Brownian motion
- The random movement of particles or molecules suspended in a liquid or gas, caused by molecular collisions.