MODEL ORGANISMS
Because all cells appear to have descended from a common ancestor, whose fundamental properties have been conserved through evolution, the knowledge gained from the study of one organism contributes to our understanding of all others, including ourselves. It turns out that certain organisms are much more accessible than others for study in the laboratory. Some reproduce rapidly and are easily manipulated using powerful genetic techniques. Others are transparent and readily develop in the laboratory from a fertilized egg to a multicellular organism, so that one can readily trace how their cells behave to produce internal tissues and organs.
Over time, different groups of biologists have focused on studying a few chosen species, which allows their knowledge and research tools to be pooled to gain a deeper understanding than could be achieved if their efforts were spread over many different organisms. Although the list of these representative, model organisms is continually expanding, a few stand out in terms of the breadth and depth of information that has been accumulated about them over the years—knowledge that has been essential for our understanding of how all cells work. In this section, we examine some of these organisms and review the benefits that each offers to the study of cell biology and, in many cases, to the promotion of human health. We begin with a discussion of some especially powerful strategies that scientists have developed to understand the cell, and we shall see how these approaches dictated the choice of model organisms.
Mutations Reveal the Functions of Genes
Without additional information, no amount of gazing at genome sequences will reveal the functions of genes. We may recognize that gene B is like gene A, but how do we discover the function of gene A in the first place? And even if we know the function of gene A, how do we test whether the function of gene B is truly the same as the sequence similarity suggests? How do we connect the world of abstract genetic information that was introduced in the previous sections with the world of living cells and organisms?
The analysis of gene functions depends on two highly complementary approaches: biochemistry and genetics. Biochemistry directly examines the functions of purified molecules, such as the protein and RNA produced from a specific gene: first we obtain that molecule from an organism and then study its chemical activities in detail. In contrast, genetics starts with the study of mutants: we either find or make an organism in which the specific gene is altered, and we then examine the effects on the mutant organism’s structure and performance (Figure 1–36). When combined with biochemistry, careful studies of an organism (and its isolated cells) mutated for a particular protein or RNA molecule can reveal the biological role of that molecule.
Biochemistry and genetics, used in combination with cell biology, provide a powerful way to connect genes and molecules directly to cell and organism structure and function. In recent years, DNA sequence information and the powerful tools of molecular biology have greatly accelerated progress in this endeavor. From sequence comparisons, we can often identify particular subregions within a gene that have been conserved nearly unchanged over the course of evolution. These subregions are often the most important parts of the gene in terms of function. We can test their individual contributions to the gene’s function by creating in the laboratory mutations of specific sites within the subregion or by constructing artificial hybrid genes that combine part of one gene with parts of another. Organisms can be engineered to make either the RNA or protein specified by the gene in large quantities to facilitate biochemical analysis. Specialists in molecular structure can determine the three-dimensional conformation of the gene product, revealing the exact position of every atom in it. Biochemists can determine how each of the parts of the genetically specified molecule contributes to its chemical behavior and function in a test tube. Cell biologists determine the many other molecules that interact with the molecule of interest and where all these molecules are located within a cell. And they also analyze the behavior of cells that are engineered to express a mutant version of the gene.
There is, however, no one simple universal recipe for discovering a gene’s function. We may discover, for example, that the product of a given gene is an enzyme that catalyzes a certain chemical reaction, and yet have no idea how or why that reaction is important to the organism. The functional characterization of each new gene product or family of gene products, unlike the description of the gene sequences, presents a fresh challenge to the biologist’s ingenuity. Moreover, we will never fully understand the function of a gene until we learn its role in the life of the organism, which means studying whole organisms, not just isolated molecules or cells.
Molecular Biology Began with a Spotlight on One Bacterium and Its Viruses
Because living organisms are so complex, the more we learn about any particular species, the more attractive it becomes as an object for further study. Each discovery in such a chosen organism raises new questions and provides new tools with which to tackle general biological questions. For this reason, large communities of biologists have become dedicated to studying different aspects of the same model organism.
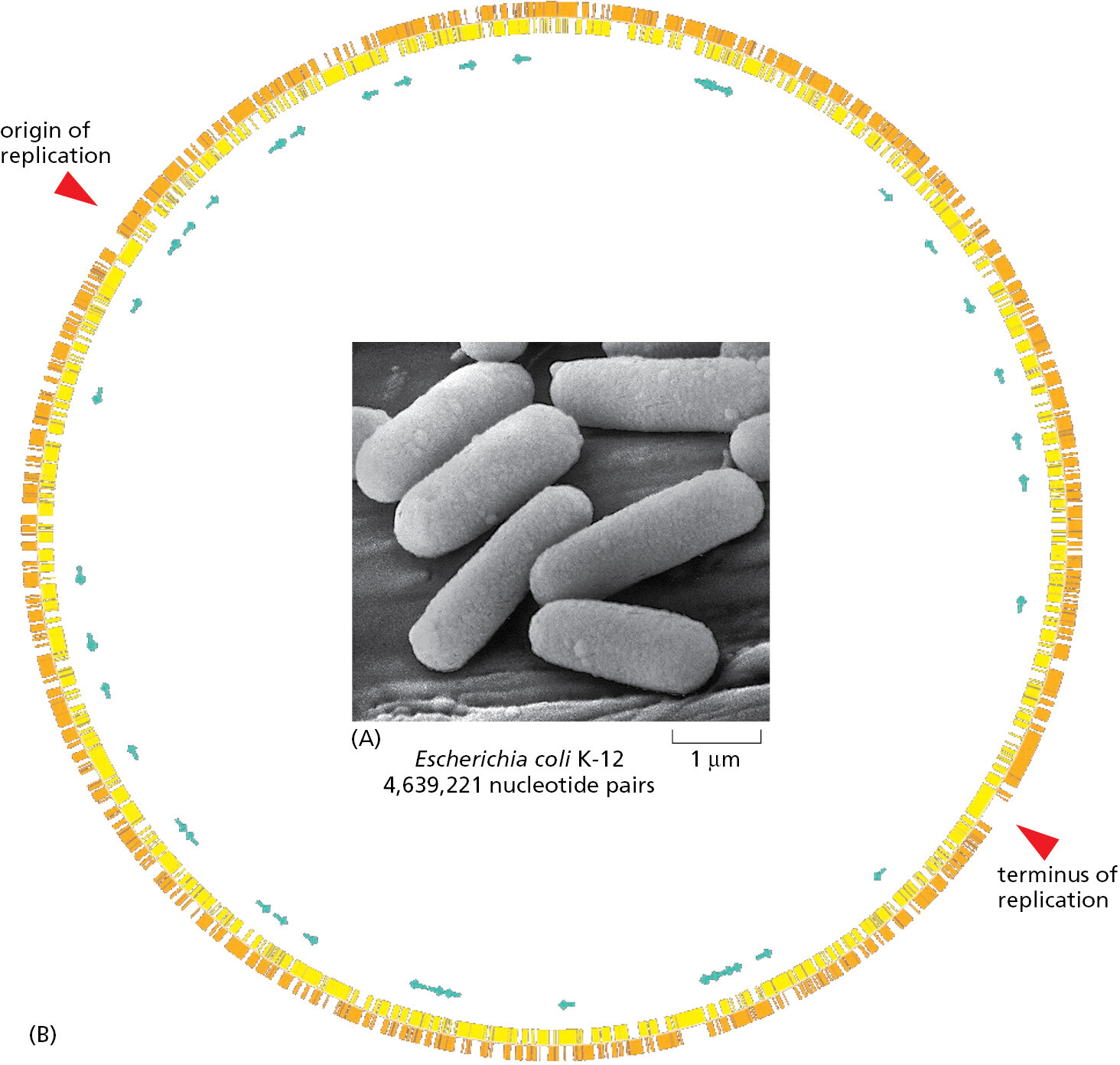
In the early days of molecular biology, the chosen model was the bacterium Escherichia coli (E. coli—see Figure 1–11B). This small, rod-shaped cell normally lives in the gut of humans and other vertebrates, but it can be grown easily in a simple nutrient broth in a culture bottle or dish, where under favorable conditions, it can reproduce every 20 minutes or so. It adapts to variable chemical conditions and can evolve by mutation and selection at a remarkable speed. Also of special early interest were a few of the viruses that infect this bacterium—inasmuch as their much smaller genomes made them even easier to analyze in detail.
Viruses are small packets of genetic material that have evolved as parasites that depend on the reproductive and biosynthetic machinery of the host cells they infect. Viruses are not strictly alive, because they depend on the machinery of their host cells for their reproduction. Although we now know that viruses are the most abundant—in terms of sheer numbers—of all the biological entities on this planet, they are too small to be seen in the light microscope. For this reason, they were completely missed until the end of the nineteenth century, when a few viruses were identified as infectious agents that pass through filters that trap bacteria, but are retained by the even-finer filters that allow large molecules to pass. Only with the invention of the electron microscope could viruses finally be visualized as tiny particles with defined shapes and sizes. We now know that viruses consist of many families, with different families having distinct structures and modes of replication (discussed in Chapters 6 and 23).
Those viruses that infect bacteria are called bacteriophages, and two that infect E. coli have played critical roles as model organisms that advanced our understanding of molecular cell biology. Detailed genetic analyses of these two viruses, bacteriophage lambda and bacteriophage T4, came first, followed by biochemistry that used the analysis of mutant genes to identify and characterize specific proteins of interest. Geneticists, for example, generated and then characterized more than a hundred different mutant genes in bacteriophage T4, a large virus with a double-strand DNA genome (Figure 1–37). Sets of T4 genes that encode components of the head and the tail of the bacteriophage were identified, allowing biochemical studies to reveal important principles of biological assembly processes. Similarly, a set of T4 genes that geneticists showed were essential for T4 DNA replication allowed those proteins to be purified, so that biochemists could decipher the central mechanisms of DNA replication in a test tube. In the same way, it was extensive studies of bacteriophage lambda that led to our early understanding of transcription regulators and gene regulatory networks (see Panel 7–1 on pp. 404–405 and Figure 7–43).
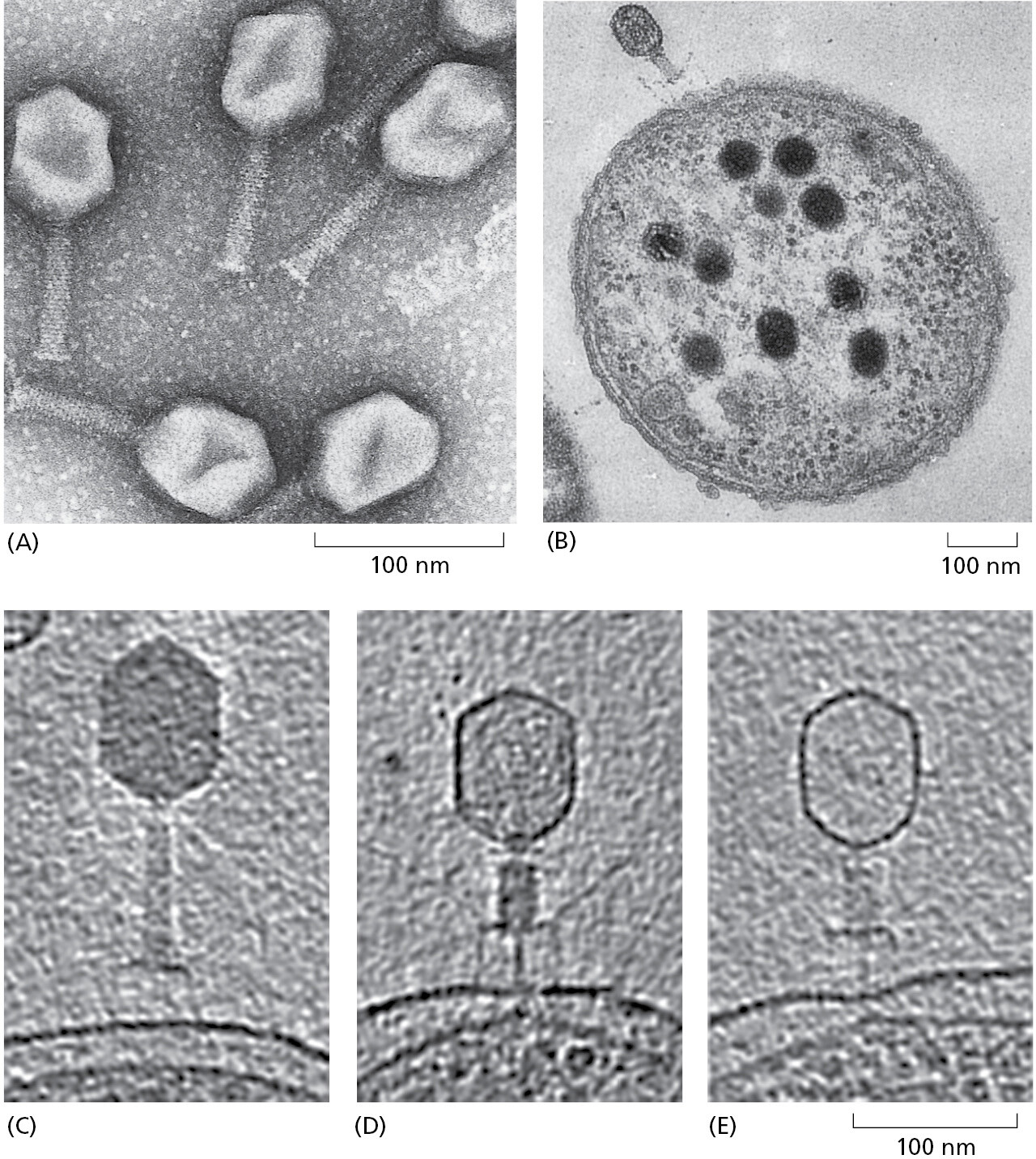
We now know that these two bacteriophages have many close relatives distributed throughout the biosphere. Relatives of bacteriophage T4, for example, are abundant in the ocean, where they infect the ubiquitous marine cyanobacteria. As a whole, ocean viruses are present in enormous numbers, estimated at 1030. If lined up end to end, they would extend beyond our nearest galaxies; they kill approximately 20% of the total ocean microbial biomass per day. Because these viruses have such a huge role in nutrient recycling, they profoundly affect Earth’s ecology.
Although not themselves living cells, viruses often serve as vectors for gene transfer between cells. A virus will replicate in one cell, emerge from it with a protective wrapping, and then enter and infect another cell, which may be of the same or different species. Often, the infected host cell is killed by the massive proliferation of virus particles inside it, but sometimes the viral DNA, instead of directly generating new virus particles, may persist in its host for many cell generations as a relatively innocuous passenger—either as a separate intracellular fragment of DNA, known as a plasmid, or as a DNA sequence inserted into the cell’s own genome. In their travels, viruses can accidentally pick up fragments of DNA from the genome of one host cell and ferry them into another cell. Such transfers of genetic material are very common in prokaryotes.
Many bacterial and archaeal species have a remarkable capacity to take up even nonviral DNA molecules from their surroundings and thereby capture the genetic information these molecules carry. By this route or by virus-mediated gene transfer, bacteria and archaea in the wild can acquire genes from neighboring cells relatively easily. Genes that confer resistance to an antibiotic or an ability to produce a toxin, for example, can be transferred from species to species and provide the recipient bacterium with a selective advantage, greatly enhancing its rate of spread. In this way, new and sometimes dangerous strains of antibiotic-resistant bacteria have been observed to evolve in the bacterial ecosystems that inhabit hospitals or various niches in the human body. On a longer time scale, the results can be even more profound; it has been estimated that at least 18% of all the genes in the present-day genome of E. coli have been acquired by horizontal transfer from another species within the past 100 million years.
The Focus on E. coli as a Model Organism Has Accelerated Many Subsequent Discoveries
The standard laboratory strain E. coli K-12 has a genome of approximately 4.6 million nucleotide pairs contained in a single circular molecule of DNA that codes for about 4300 different kinds of proteins (Figure 1–38). In molecular terms, we probably have a more complete understanding of E. coli than of any other living organism. Most of our understanding of the fundamental mechanisms of life—for example, how cells replicate their DNA or how they decode the instructions represented in the DNA to direct the synthesis of specific RNAs and proteins—initially came from studies of E. coli and its viruses. This is because the basic genetic mechanisms have turned out to be highly conserved throughout evolution and are essentially the same in our own cells as in E. coli.
It should be noted that, as with other bacteria, different strains of E. coli, though classified as members of a single species, differ genetically to a much greater degree than do different varieties of an organism such as a plant or animal. One E. coli strain may possess many hundreds of genes that are absent from another, and the two strains could have as little as 50% of their genes in common. These differences are largely the result of rampant horizontal gene transfer, characteristic of this and many other bacterial and archaeal species.
A Yeast Serves as a Minimal Model Eukaryote
The molecular and genetic complexity of eukaryotes is daunting, and biologists need to concentrate their limited resources on a small number of selected model organisms to unravel this complexity.
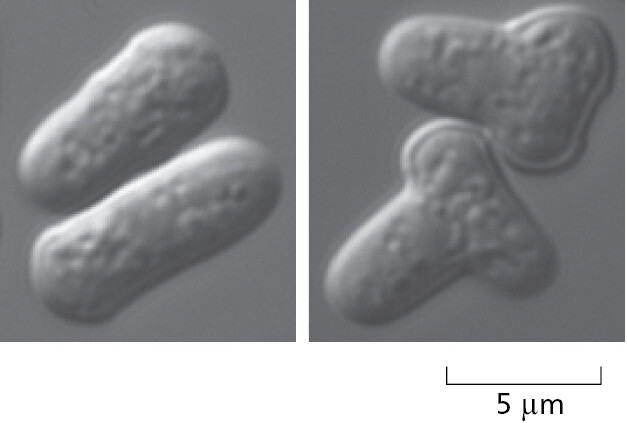
To analyze the internal workings of the eukaryotic cell without the additional problems of multicellular development, it makes sense to use a single-cell species that is as simple as possible. The popular choice for this role of minimal model eukaryote has been the yeast Saccharomyces cerevisiae (Figure 1–39)—the same species that is used by brewers of beer and bakers of bread.
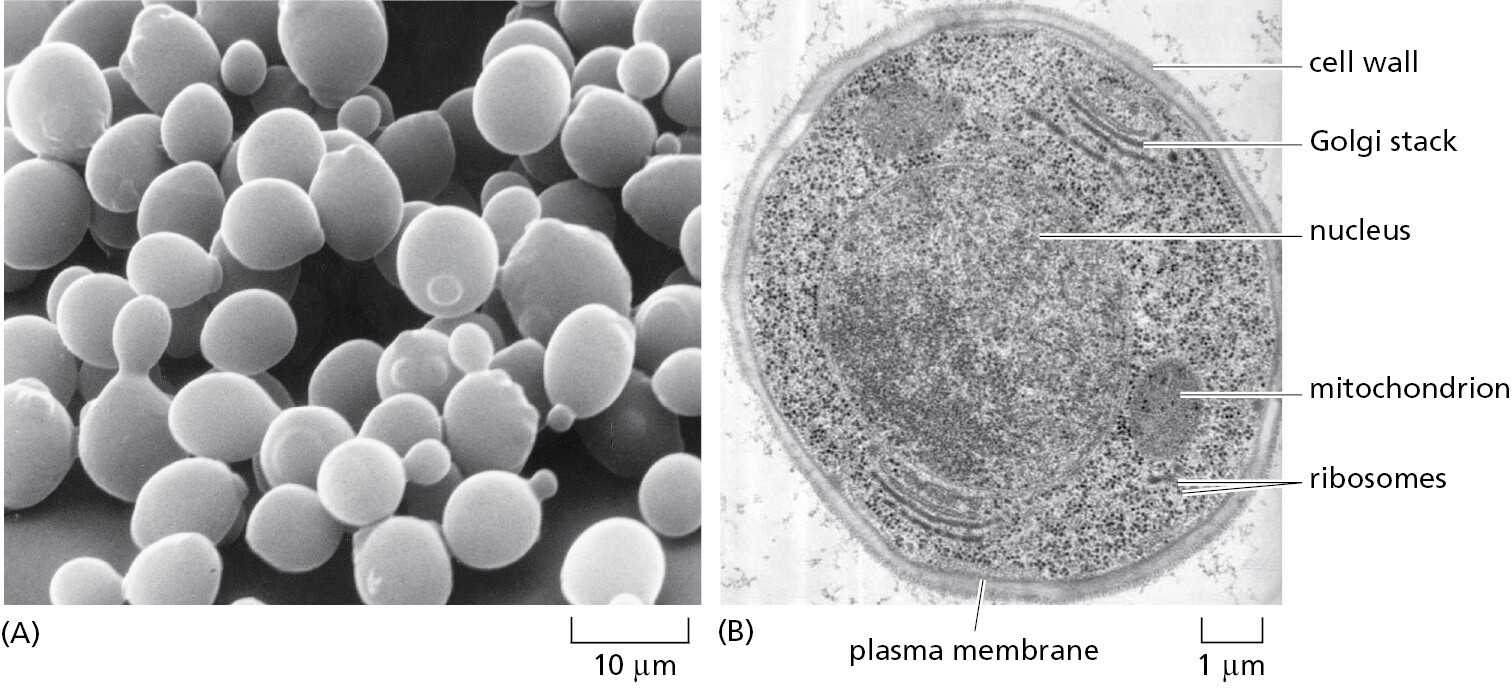
S. cerevisiae is a small, single-cell member of the kingdom of fungi and, in terms of its genome sequence, much more closely related to animals than to plants (see Figure 1–35). It is robust and easy to grow in a simple nutrient medium. Like other fungi, it has a tough cell wall, is relatively immobile, and possesses mitochondria but not chloroplasts. When nutrients are plentiful, it grows and divides about every hundred minutes. It can reproduce either vegetatively (that is, by ordinary cell division, or mitosis), or sexually: two yeast cells that are haploid (possessing a single copy of each chromosome, n = 1) can fuse to create a cell that is diploid (containing two copies of each chromosome, n = 2), and the diploid cell can undergo meiosis (a reduction division) to produce cells that are once again haploid (Figure 1–40). In contrast to most animals, this yeast can therefore proliferate either sexually or asexually, a choice that an experimenter can make simply by changing the growth conditions.
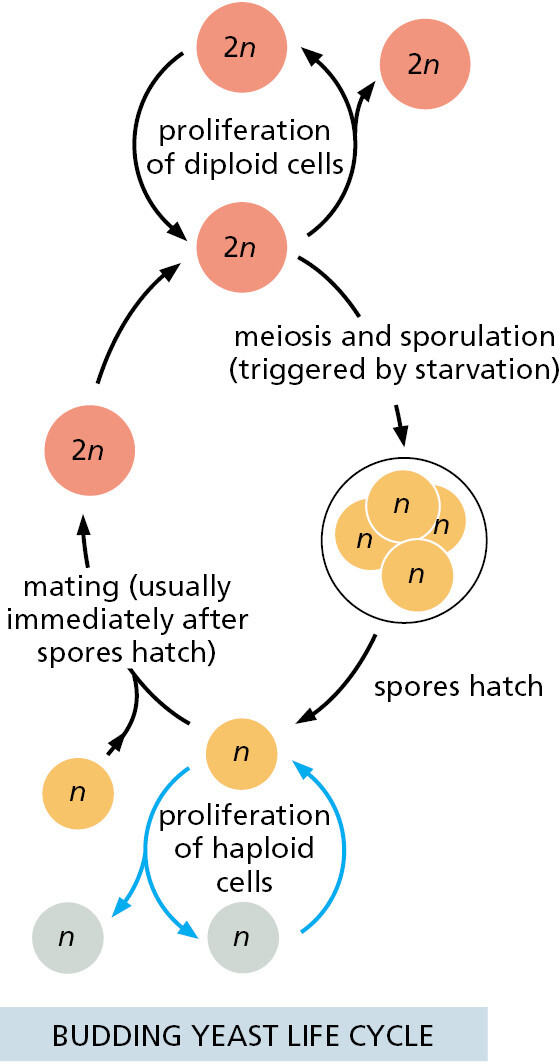
In addition to these features, the yeast has a further property that makes it a convenient organism for genetic studies: its genome, by eukaryotic standards, is exceptionally small (see Table 1–2), yet it suffices for all the basic tasks that every eukaryotic cell must perform. Mutants are available for every gene, and thus the consequence of missing each gene—one by one—can be observed under any environmental condition using the high-throughput procedures described in Chapter 8. Over the past 50 years, extensive studies of yeast cells carried out by many laboratories have provided keys to crucial “eukaryotic-only” processes. These include the cell-division cycle (the critical chain of events by which the nucleus and all the other components of a cell are duplicated and parceled out to create two daughter cells from one) and meiosis (the process through which an organism’s reproductive cells are formed). In addition, important insights into eukaryotic chromosome structure, the organization of the nucleus, the mechanisms of gene expression, the formation of organelles, and the ways that proteins are secreted from cells have come out of the work on yeasts. Many of these fundamental processes are so similar between yeasts and humans that a human homolog of a yeast protein will often faithfully carry out its functions when artificially expressed in yeast cells.
The Expression Levels of All the Genes of an Organism Can Be Determined
The complete genome sequence of S. cerevisiae consists of approximately 12,500,000 nucleotide pairs, including the small contribution (about 78,500 nucleotide pairs) of the mitochondrial DNA. This total is only about 2.7 times as much DNA as there is in E. coli, and it codes for only about 1.5 times as many distinct proteins (see Table 1–2). The way of life of S. cerevisiae is similar in many ways to that of a bacterium, and it seems that this yeast has likewise been subject to selection pressures (for rapid proliferation, for example) that have kept its genome compact.
Knowledge of the complete genome sequence of any organism—be it a yeast or a human—opens up new perspectives on the workings of the cell: many things that once seemed impossibly complex now seem to be within our grasp. Using techniques described in Chapter 8, it is possible, for example, to monitor simultaneously, the amount of mRNA produced from every gene in the yeast genome under any environmental condition. It is also possible to determine in real time how the pattern of gene activity changes when conditions change. This type of analysis can be repeated with mRNA prepared from mutant cells lacking any gene we care to test, and, in this way, the influence of that gene on the expression of all other genes can be observed. Although pioneered in yeast, this approach now provides a way to reveal the entire system of controls that govern gene expression in any organism, as long as its genome sequence is known and it can be manipulated genetically.
Arabidopsis Has Been Chosen as a Model Plant
The large multicellular organisms that we see around us—the plants and animals—seem fantastically varied, but, as we have seen, they are much closer to one another in their evolutionary origins, and more similar in their basic cell biology, than the great host of microscopic single-celled organisms we have been discussing. Thus, while bacteria and archaea are separated by perhaps 3.5 billion years of evolution, vertebrates and insects are separated by about 700 million years, fish and mammals by about 450 million years, and the different species of flowering plants by only about 150 million years (see Figure 1–35).
Because of the close evolutionary relationship between all flowering plants (see Figure 1–35), we can, once again, gain insight into the cell and molecular biology of this whole class of organisms by focusing on just one or a few species for detailed analysis. Out of the nearly 400,000 known species of flowering plants, molecular biologists have chosen to concentrate their efforts on a small weed in the cabbage family, the common wall cress Arabidopsis thaliana (Figure 1–41), which can be grown indoors in large numbers and produces thousands of offspring per plant after 8–10 weeks. Arabidopsis has a total genome size of approximately 135 million nucleotide pairs, about 10 times the size of the yeast genome (see Table 1–2).
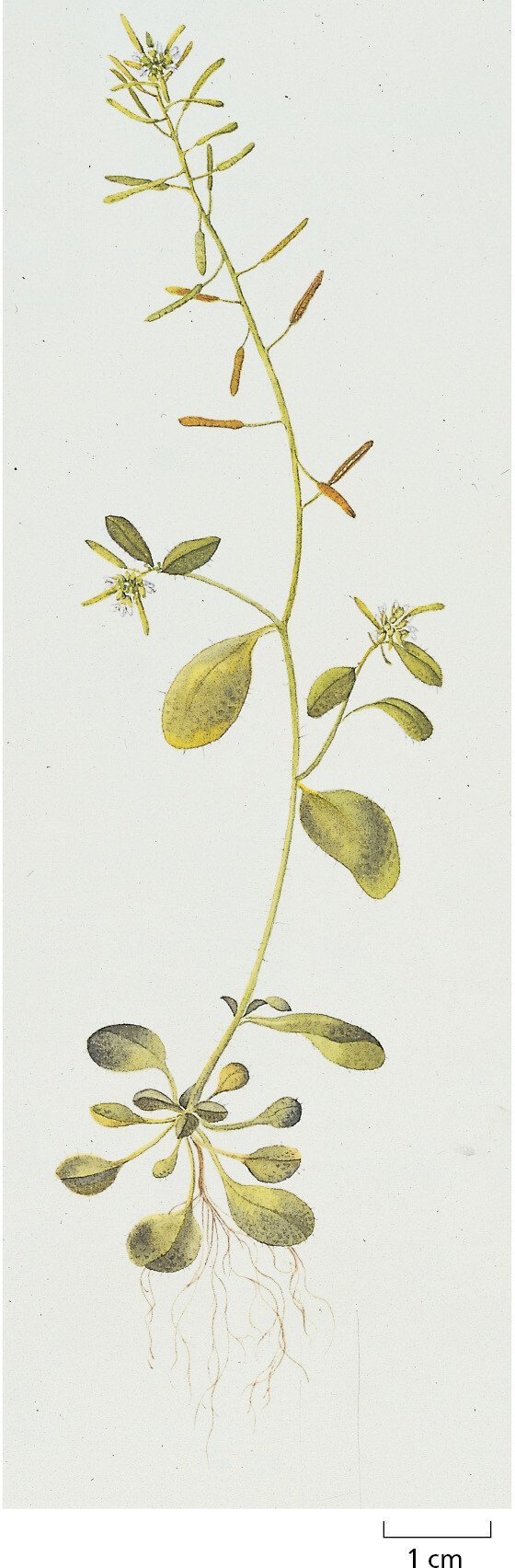
Work on Arabidopsis has provided a deep understanding of numerous key features of plants, including the mechanisms that cause flower development and its coordination with the seasons, the ability to grow toward sunlight, cell-to-cell signaling by hormones, and the special type of innate immune system that plants use to ward off pathogens. Comparison of the developmental programs between plants and animals has also highlighted some common principles, thereby allowing a glimpse into the basic logic through which large, highly differentiated, multicellular organisms evolved from single-cell ancestors.
The World of Animal Cells Is Mainly Represented by a Worm, a Fly, a Fish, a Mouse, and a Human
Although plants make up 80% of the biomass on Earth and animals make up less than 0.4% (see Figure 1–14), animals account for the majority of all named species of living organisms, and they are by far the most intensely studied. Five species have emerged as the foremost model organisms for molecular, cell, and developmental biological studies. In order of increasing body size, they are the nematode worm Caenorhabditis elegans, the fly Drosophila melanogaster, the zebrafish Danio rerio, the mouse Mus musculus, and the human, Homo sapiens. Genome sequences from many different individuals within each species have been determined.
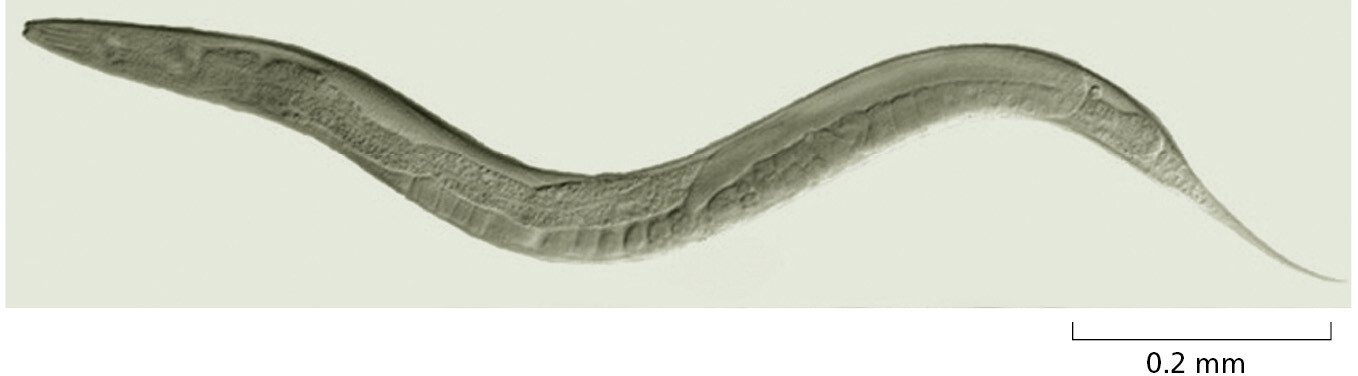
Caenorhabditis elegans (Figure 1–42) is a small, harmless relative of the eelworm that attacks crops. With a life cycle of only a few days, an ability to survive in a freezer indefinitely in a state of suspended animation, a simple body plan, and an unusual life cycle that is well suited for genetic studies, it is an attractive model animal. C. elegans develops with clockwork precision from a fertilized egg cell into an adult worm with exactly 959 body cells (plus a variable number of egg and sperm cells)—an unusual degree of regularity for animal development. We now have a minutely detailed description of the sequence of events by which this development occurs, as the cells divide, move, and change their character according to strict and predictable rules (see Figure 21–42). The genome of about 100 million nucleotide pairs codes for about 20,000 proteins, and many mutants and other tools are available for testing gene functions. Although the worm has a body plan very different from our own, the conservation of biological mechanisms has been sufficient for the worm to be a model for many of the developmental and cell-biological processes that occur in the human body. Thus, for example, studies of the worm have been critical for understanding the molecular mechanisms that mediate and regulate the many cell deaths that help control animal-cell numbers, both in normal development and during human cancer growth. This crucial process, called programmed cell death or apoptosis, is the subject of Chapter 18. In addition, studies in C. elegans first revealed many fascinating features of RNA interference (discussed in Chapters 7 and 8). They have also provided key insights into the ways neurons make their proper connections (discussed in Chapter 21) and informed many additional areas of cell biology.
Studies in the Fruit Fly Drosophila Provide a Key to Vertebrate Development
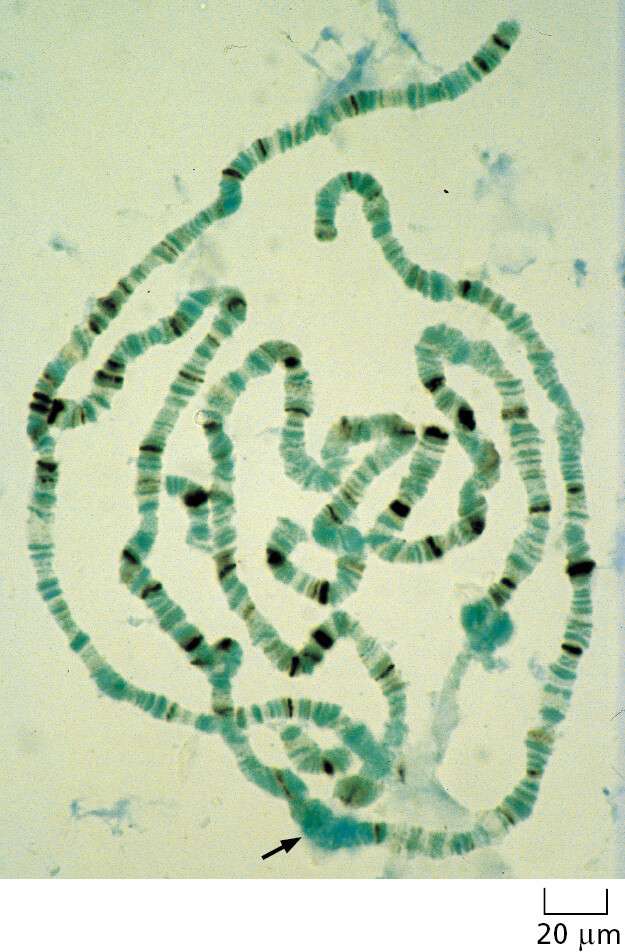
The fruit fly Drosophila melanogaster (Figure 1–43) has been used as a model for animal genetic studies for longer than any other organism; in fact, the foundations of classical genetics were built to a large extent on studies of this insect. Nearly 100 years ago, for example, the fly provided definitive proof that genes—the abstract units of hereditary information at the time—are carried on chromosomes, whose behavior had been closely followed with the light microscope during eukaryotic cell division but whose function was at first unknown. The proof depended on one of the many features that make Drosophila especially convenient for molecular genetic studies—the giant chromosomes, which have a characteristic banded appearance that is visible in some of its cells (Figure 1–44). Specific changes in the hereditary information, manifest in families of mutant flies, were found to correlate exactly with the loss or alteration of specific bands in the giant chromosomes.

In more recent times, Drosophila, more than any other organism, has shown us how to trace the chain of cause and effect from the genetic instructions encoded in the chromosomal DNA to the structure of the adult multicellular body. Drosophila mutants with body parts strangely misplaced (Figure 1–43) or mispatterned provided the key to the identification and characterization of the genes required to make a properly structured body, with gut, limbs, eyes, and all the other parts in their correct places. Once these Drosophila genes were identified, scientists could identify homologous genes in vertebrates, and then test their functions there by analyzing mice in which the genes had been mutated. The results have revealed an astonishing degree of similarity in the molecular mechanisms that govern insect and vertebrate development (discussed in Chapter 21).
The majority of all named species of living organisms are insects. Even if Drosophila had nothing in common with vertebrates, but only with insects, it would still be an important model organism. But, if understanding the molecular genetics of vertebrates is the goal, why not simply tackle the problem head-on in vertebrates, instead of sidling up to it obliquely through studies in Drosophila?
There are many reasons. Drosophila requires only 9 days to progress from a fertilized egg to an adult; it is vastly easier and cheaper to breed than any vertebrate, and its genome is much smaller—about 180 million nucleotide pairs, compared with about 3.1 billion for a human (see Table 1–2). Its genome codes for about 14,000 proteins, and mutants are now available for essentially any gene. In addition to its foundational contributions to animal development, research on Drosophila continues to uncover many other insights into biology, ranging from deeply conserved mechanisms that neutralize pathogens to ways that external stimuli from the environment are processed in the brain.
The Frog and the Zebrafish Provide Highly Accessible Vertebrate Models
Frogs have long been used to study the early steps of embryonic development in vertebrates. Because their eggs are big, easy to manipulate, and fertilized outside of the animal, the subsequent development of the early embryo can be easily followed (Figure 1–45). Xenopus laevis, the African clawed frog, continues to be an important model organism (Movie 1.6 and see Movie 21.1). Although the species is poorly suited for genetic analysis, cytoplasm isolated from unfertilized Xenopus eggs has the remarkable ability to recapitulate the formation of cellular structures and organelles in a test tube. These egg extracts allow powerful biochemical approaches to study such fundamental processes as the cell division cycle, described in Chapter 17.
{kind=link}
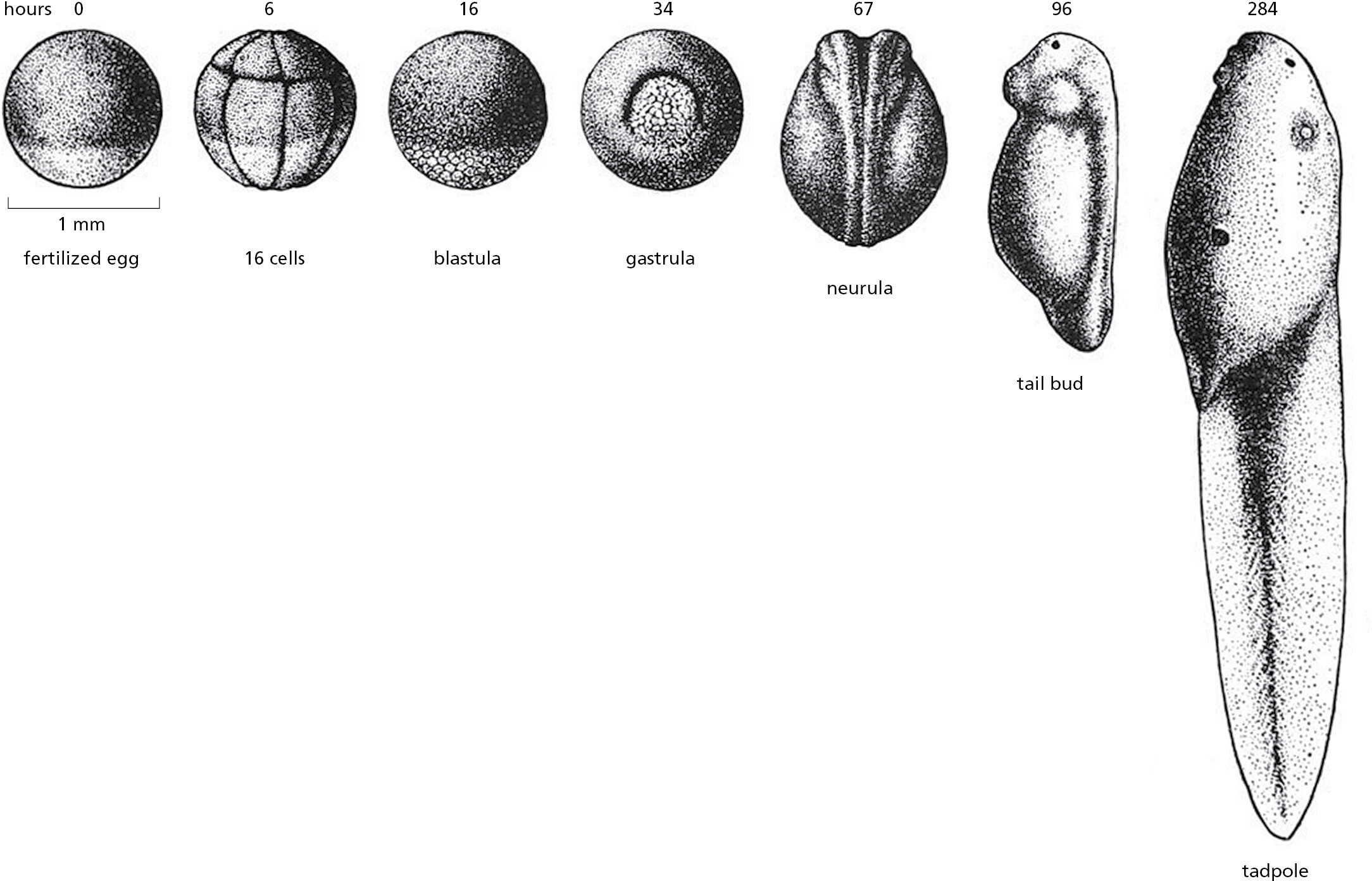

The zebrafish Danio rerio, in contrast, is well suited for genetic analysis. Its genome is compact—only half as big as that of a mouse or a human (see Table 1–2)—and it has a generation time of only about 3 months, which is much shorter than that of Xenopus laevis. Many mutants are available, and genetic manipulation is relatively simple. The zebrafish has the added virtue that it is transparent for the first 2 weeks of its life, so behavior of specific tissues and individual cells can easily be followed in the living organism as it develops (Figure 1–46; see Movie 21.2). All this has made it an increasingly important model vertebrate, one that has been especially crucial for understanding the development of the heart and the circulatory system, as discussed in Chapter 22.
The Mouse Is the Predominant Mammalian Model Organism
In terms of genome size and function, cell biology, and molecular mechanisms, mammals are a highly uniform group of organisms. Even anatomically, the differences among mammals are chiefly a matter of size and proportions; it is hard to think of a human body part that does not have a counterpart in elephants and mice, and vice versa. Evolution plays freely with quantitative features, but it does not readily change the logic of the basic structure.
Mammals have typically about 1.5 times as many protein-coding genes as Drosophila, a genome that is about 16 times larger, and an adult body made up of millions or billions of times as many cells. For an exact measure of how closely mammalian species resemble one another genetically, we can compare the nucleotide sequences of corresponding (orthologous) genes or the amino acid sequences of the proteins that these genes encode. The results for individual genes and proteins vary widely. But typically, if we line up the amino acid sequence of a human protein with that of the orthologous protein from, say, an elephant, more than 80% of the amino acids are identical. A similar comparison between human and bird shows an amino acid identity of about 70%—because the bird and mammalian lineages have had longer to diverge than those of the elephant and the human, they have accumulated more differences (Figure 1–47).

The figures on the right show the amino acid sequence divergence for one particular protein—the α chain of hemoglobin. Note that although there is a clear general trend of increasing divergence with increasing time for this protein, there are irregularities that are thought to reflect the action of natural selection causing especially rapid changes in hemoglobin sequence when the organisms experienced special physiological demands. Some proteins that are subject to stricter functional constraints evolve much more slowly than hemoglobin, whereas others evolve as much as five times faster. (Adapted from S. Kumar and S.B. Hedges, Nature 392:917–920, 1998.)
The mouse, being small, hardy, and a rapid breeder, has become the foremost model organism for experimental studies of mammalian molecular cell biology. Many naturally occurring mutations are known, often mimicking the effects of corresponding mutations in humans to a remarkable extent (Figure 1–48). Moreover, methods have been developed to test the function of any chosen mouse gene or of any noncoding portion of the mouse genome by artificially creating mutations in the relevant part of the gene or genome, as we explain in Chapter 8.
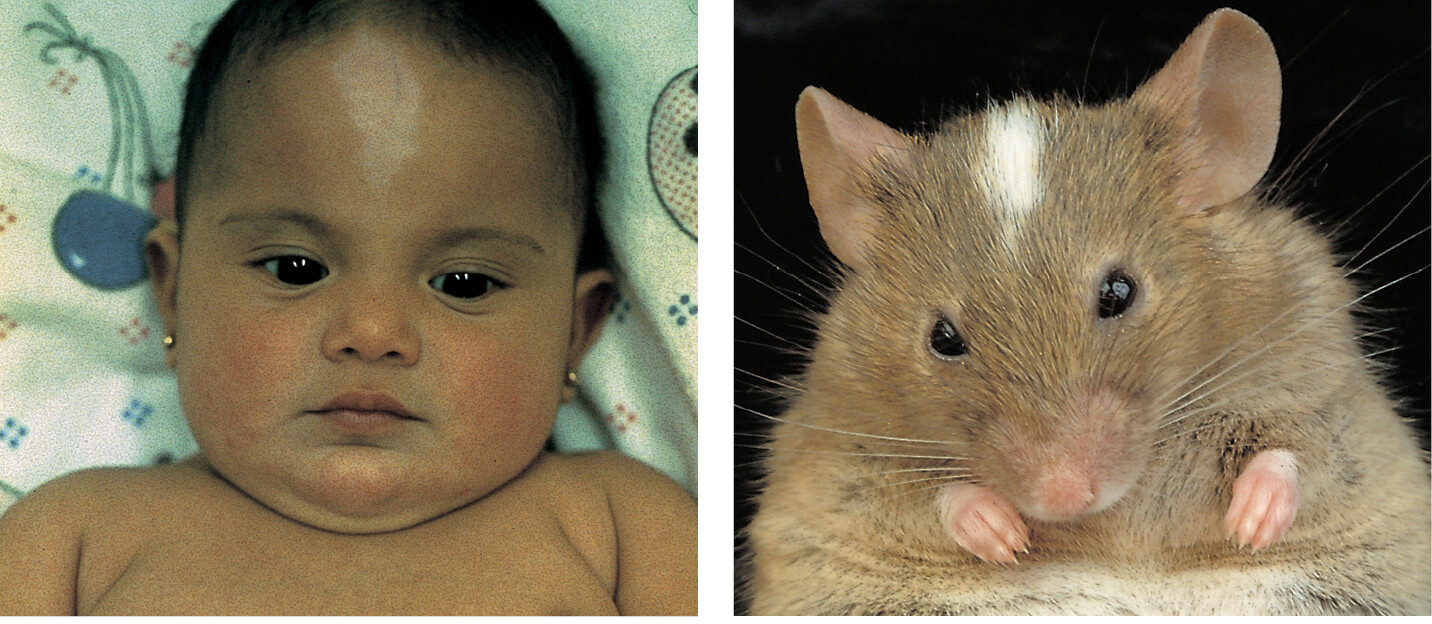
Just one made-to-order mutant mouse can provide a wealth of information for the cell biologist. It reveals the effects of the chosen mutation in various contexts, simultaneously testing the action of the gene in the many different types of cells in the body that could in principle be affected. Studies of the mouse are so fundamental to understanding mammalian biology that we will encounter them in nearly every chapter of this book.
The COVID-19 Pandemic Has Focused Scientists on the SARS-CoV-2 Coronavirus
Having discussed several of the most prominent and well-studied model organisms—which are based on the cell as their fundamental unit—we now turn to an intensively studied virus. Viruses, which in essence feed on cells, are prevalent in all three domains of life: bacteria, archaea, and eukaryotes. We introduced them earlier in this chapter when we discussed several E. coli viruses that served as critical experimental systems for the initial development of molecular biology. Here, we focus on one prominent virus, SARS-CoV-2, that infects our own cells and has, due to the widespread attention it has received from scientists, become a model system for understanding eukaryotic viruses. But before discussing this virus in detail, we consider how viruses—genomes packaged in protective shells—first came to be, and how they have evolved over time.
As described in Chapter 6, cells are believed to have first evolved in an “RNA world,” before there were proteins or DNA molecules. Scientists suspect that even at that time, parasitic genetic elements were present, in the form of small RNA molecules that took advantage of more advanced replicating entities to proliferate. These are believed to have been the ancestors of today’s smallest viruses, which contain single-strand RNA genomes composed of as few as 3000 nucleotides. Thus, virus-like entities have probably been a ubiquitous feature of life on Earth for more than 3 billion years.
At a minimum, a virus requires a genome that encodes two core functions: first, a nucleic acid replication process that produces multiple copies of its genome once inside its host cell, and second, a genome-packaging process that surrounds these new genomes with a protective protein coat, while allowing the viruses to exit the host cell and subsequently enter others. But the viruses present today have evolved through billions of infectious cycles, during which there has been a constant war between host organisms and the viruses—with host cells evolving multiple antivirus defenses and viruses evolving various ways to overcome these defenses. As a result, through cycles of random mutation followed by natural selection over long evolutionary times, most virus genomes have grown much larger than needed for their two core functions, with many of the additional genes encoding proteins that help the viruses to circumvent their host-cells’ defenses.
Coronavirus genomes are large, single-strand RNA molecules, about 30,000 nucleotides long. This RNA is packaged in a protein coat that is covered with a lipid bilayer envelope, from which protein spikes protrude (Figure 1–49A and B). Many coronavirus strains circulate in animal species, including pigs, birds, and bats. Some strains also circulate among humans; these so-called “endemic” strains cause only mild symptoms and are responsible for about one in four common colds. But on rare occasions, a bat coronavirus mutates in a way that allows it to infect humans, where it can cause very severe, even fatal, disease. It is thought that the COVID-19 pandemic of 2020 originated in this way.
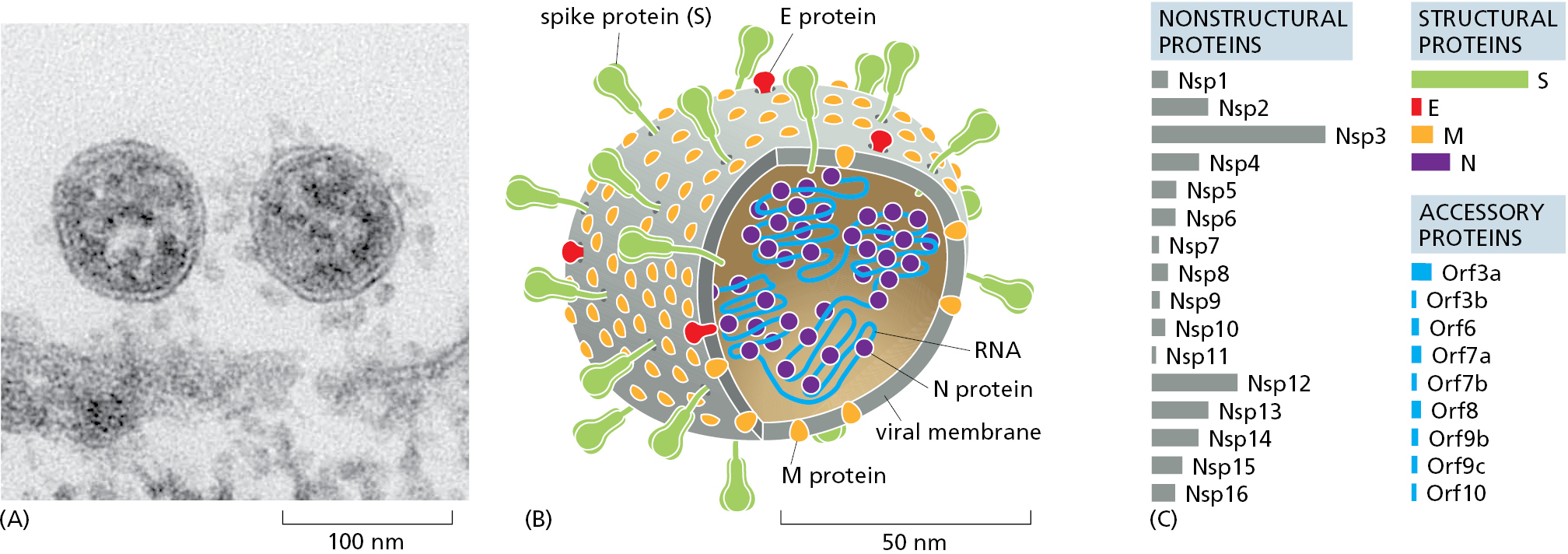
The virus that causes COVID-19, SARS-CoV-2, produces 29 proteins (Figure 1–49C). Some are structural proteins that package the virus’s RNA genome into the virus particle. The nonstructural proteins are critical for replicating the viral genome inside of the host cell, as well as for ensuring that the viral genes are appropriately translated into proteins, including the viral RNA polymerase complex. And, as one would expect, other proteins help the virus to avoid the host’s immune defenses, which are described in Chapter 24.
The SARS-CoV-2 virus is closely related to the coronaviruses that cause colds, as well as to the SARS-CoV virus that emerged from bats in 2002 and killed nearly 1 in 10 of the humans it infected. We still do not understand what makes SARS-CoV and SARS-CoV-2 infections so much more dangerous to humans than the infections caused by their close relatives that cause only a mild cold. But, given the thousands of research laboratories currently focused on understanding the cell biology of SARS-CoV-2 with the aim of ameliorating the COVID-19 pandemic, we should know the answers to these questions in the near future. These studies are certain to make us much better prepared to deal with the next virus that emerges to threaten us.
Humans Are Unique in Reporting on Their Own Peculiarities
As humans, we have a special interest in the human genome. We want to know how our genes and their products work. But, even if you were a mouse, preoccupied with how mouse genes and their products work, humans would be attractive as model genetic organisms because of one special property: through medical examinations and self-reporting, we catalog our own genetic (and other) disorders. The human population is enormous, consisting today of some 8 billion individuals, and this self-documenting property means that a huge database exists of human mutations and their effects. And the human genome sequence of more than 3 billion nucleotide pairs has been determined for hundreds of thousands of people, making it easier than ever before to identify at a molecular level the precise genetic change responsible for any given human mutant phenotype.
But what precisely do we mean when we speak of the human genome? Whose genome? On average, any two people taken at random will differ at roughly 4 million different sites in their DNA sequence (see Table 4–3, p. 247). Thus, the human genome is very complex, embracing the entire pool of variant genes found in the human population. As described in Chapter 4, knowledge of this variation is helping us to understand human biology; for example, why some people are prone to one disease, others to another, and why some respond well to a drug, but others badly. It is also providing clues to our history, including population movements, interbreeding among our ancestors, the infections they suffered, and the diets they ate. All these things have left traces in the variant forms of genes that survive today in the human communities that populate our planet, and by exploiting this fact, scientists have been discovering fascinating aspects of our past.
By drawing together the insights from humans, mice, fish, flies, worms, yeasts, plants, and bacteria—using DNA sequence similarities to map out the correspondences between one model organism and another—we are greatly enriching our understanding of them all.
To Understand Cells and Organisms Will Require Mathematics, Computers, and Quantitative Information
Empowered by knowledge of complete genome sequences, we can list the genes, proteins, and RNA molecules in a cell, and we have powerful methods to analyze the complex web of interactions between them. But how are we to use all this information to understand how cells work? Even for a single cell type belonging to a single species of organism, the current deluge of data seems overwhelming. The informal reasoning that biologists usually rely on seems increasingly inadequate in the face of such complexity.
The difficulty is more than just a matter of information overload. Biological systems are, for example, full of feedback loops, and the behavior of even the simplest of systems with feedback is remarkably difficult to predict by intuition alone (Figure 1–50); small changes in parameters can cause radical changes in outcome. To go from a circuit diagram to a prediction of the behavior of the system, we need detailed quantitative information, and to draw deductions from that information we need mathematics and computers.
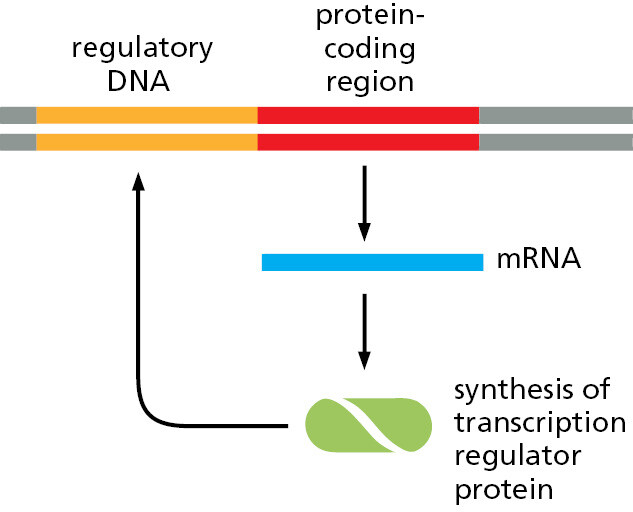
Such tools for quantitative reasoning are essential, but they are not all-powerful. You might think that, knowing how each protein in a cell influences each other protein, and how the expression of each gene is regulated by the products of other genes, we should soon be able to calculate how the cell as a whole will behave, just as an astronomer can calculate the orbits of the planets or a chemical engineer can calculate the flows through a chemical plant. But any attempt to perform this feat for anything close to an entire living cell rapidly reveals the limits of our present knowledge. The information we have, plentiful as it is, is full of gaps and uncertainties, and it is largely qualitative rather than quantitative. Most often, cell biologists studying a cell’s control systems sum up their knowledge in simple schematic diagrams—this book is full of them—rather than in numbers, graphs, and differential equations.
To progress from qualitative descriptions and intuitive reasoning to quantitative descriptions and mathematical deduction is one of the biggest challenges for contemporary cell biology. So far, the challenge has been met for only a few very simple fragments of the machinery of living cells—subsystems involving a handful of different proteins, or two or three genes that regulate one another, where theory and experiment go closely hand in hand. We discuss some of these examples later in the book and devote much of Chapter 8 to some new approaches designed to answer the increasingly complex questions that arise in biology.
Knowledge and understanding bring the power to intervene—with humans, to prevent and treat disease; with plants, to create better crops; with bacteria, archaea, and fungi, to control them for our own benefit. All these biological enterprises are linked, because the genetic information of all living organisms is written in the same language. The recent ability of molecular biologists to read and decipher this language has already begun to transform our relationship to the living world. The account of cell biology in the subsequent chapters will, we hope, equip the reader to understand, and possibly to contribute to, the great biosciences adventure that we can anticipate through the rest of this century.
Summary
Powerful new technologies, including rapid and cheap genome sequencing, are enabling rapid advances in our knowledge of human biology, with implications for understanding and treating human disease. But living systems are incredibly complex, and simpler model organisms have played a critical part in revealing universal genetic and molecular cell biological mechanisms. Thus, for example, early research on the bacterium E. coli and its viruses provided the foundations needed to decipher the fundamental genetic mechanisms in all cells. And research on the unicellular yeast Saccharomyces cerevisiae, which continues to serve as a simple model organism for eukaryotic cell biology, has revealed the molecular basis for many critical processes that have been strikingly conserved during more than a billion years of eukaryotic evolution. Biologists have also chosen a small number of multicellular organisms for intensive study: a worm, a fly, a fish, the mouse, and humans serve as model organisms for animals, and a small member of the cabbage family serves as a model for plant biology. Even today, research that focuses on these and other model organisms remains crucial for understanding ourselves, as well as for driving scientific and medical advances.
Glossary
- model organism
- A species that has been studied intensively over a long period and thus serves as a “model” for deriving fundamental biological principles.
- virus
- Particle consisting of nucleic acid (RNA or DNA) enclosed in a protein coat and capable of replicating within a host cell and spreading from cell to cell.