THE INITIATION AND COMPLETION OF DNA REPLICATION IN CHROMOSOMES
We have seen how a set of replication proteins rapidly and accurately generates two daughter DNA double helices behind a replication fork. But how is this replication machinery assembled in the first place, and how are replication forks created on an intact, double-strand DNA molecule? In this part of the chapter, we discuss how cells initiate DNA replication and how they carefully regulate this process to ensure that it takes place only at the proper time and chromosomal sites. We also discuss special problems that the replication machinery in eukaryotic cells must overcome including the need to replicate the enormously long DNA molecules found in eukaryotic chromosomes, as well as the need to copy DNA molecules that are tightly complexed with nucleosomes.
DNA Synthesis Begins at Replication Origins
As discussed previously, the DNA double helix is normally very stable: the two DNA strands are locked together firmly by the hydrogen bonds formed between the bases on each strand. To begin DNA replication, the double helix must first be opened up and the two strands separated to expose unpaired bases. As we shall see, the process of DNA replication is begun by special initiator proteins that bind to double-stranded DNA and pry the two strands apart, breaking the hydrogen bonds between the bases.
The positions at which the DNA helix is first opened are called replication origins (Figure 5–24). In simple cells like those of bacteria or budding yeast, origins are specified by DNA sequences several hundred nucleotide pairs in length. This DNA contains both short sequences that attract initiator proteins and stretches of DNA that are especially easy to open. We saw in Figure 4–5A that an A-T base pair is held together by fewer hydrogen bonds than is a G-C base pair. Therefore, DNA rich in A-T base pairs is relatively easy to pull apart, and regions of DNA enriched in A-T base pairs are typically found at replication origins.
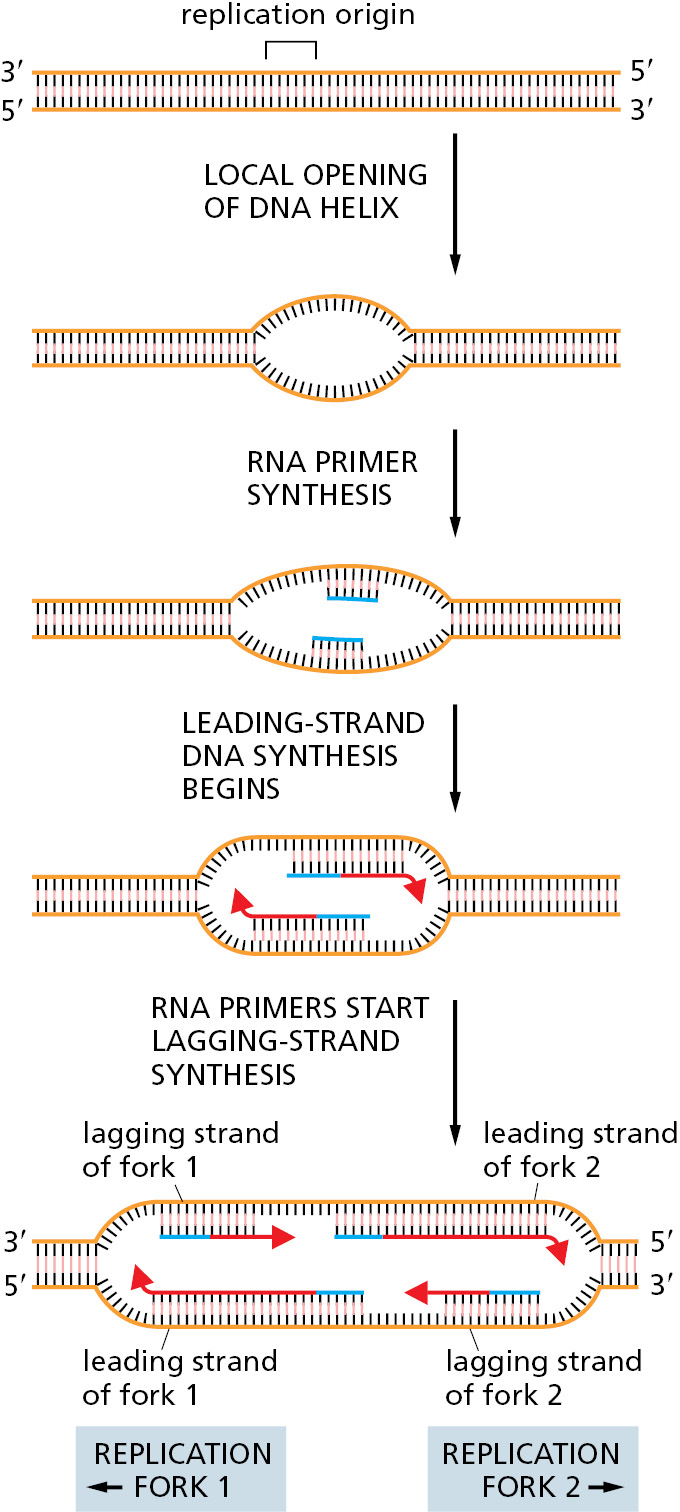
Although the basic process of replication-fork initiation depicted in Figure 5–24 is fundamentally the same for bacteria and eukaryotes, the detailed way in which this process is performed and regulated differs considerably between these two groups of organisms. We first consider the case in bacteria and then turn to the more complex situation found in yeasts, mammals, and other eukaryotes.
Bacterial Chromosomes Typically Have a Single Origin of DNA Replication
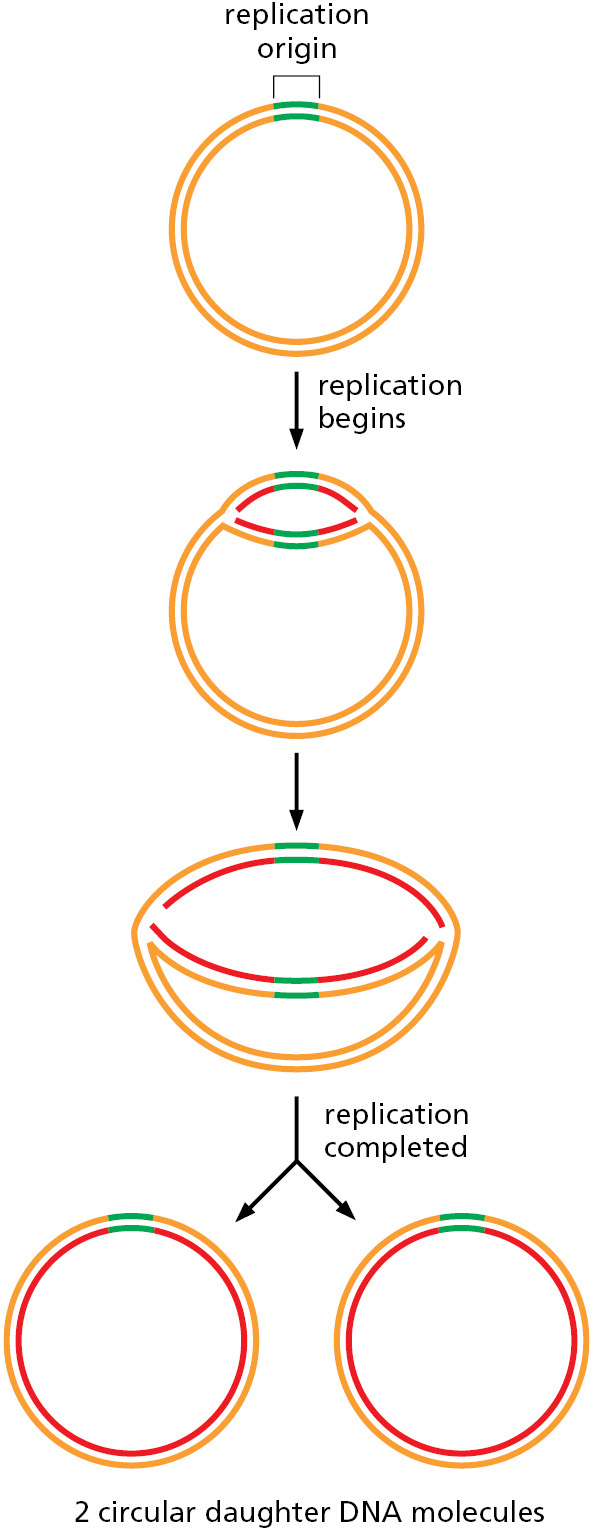
The genome of E. coli is contained in a single circular DNA molecule of 4.6 × 106 nucleotide pairs. DNA replication begins at a single origin of replication, and the two replication forks assembled there proceed (at approximately 1000 nucleotides per second) in opposite directions until they meet up roughly halfway around the chromosome (Figure 5–25). The only point at which E. coli can control DNA replication is initiation: once the forks have been assembled at the origin, they synthesize DNA at a relatively constant speed until replication is finished. Therefore, it is not surprising that the initiation step of DNA replication is tightly regulated. The process begins when specialized initiator proteins (in their ATP-bound state) bind in multiple copies to specific DNA sites located at the replication origin, wrapping the DNA around the proteins to form a large protein–DNA filament that introduces torsional stress on the DNA double helix (Figure 5–26). This stress is partially relieved by melting of the adjacent AT-rich sequences. The protein–DNA complex then attracts two DNA helicases, each bound to a helicase loader, and these are placed—facing in opposite directions—around adjacent DNA single strands whose bases have been exposed by the assembly of the initiator protein–DNA complex. The helicase loader is analogous to the clamp loader we encountered earlier; it has the additional job of keeping the helicase in an inactive form until it is properly loaded. Once the helicases are properly positioned on DNA, the loaders dissociate and the helicases begin to unwind DNA, exposing enough single-stranded DNA for DNA primases to synthesize the first RNA primers. This quickly leads to the assembly of the remaining replication proteins to create two replication forks that move in opposite directions away from the replication origin, each synthesizing new DNA as they travel.
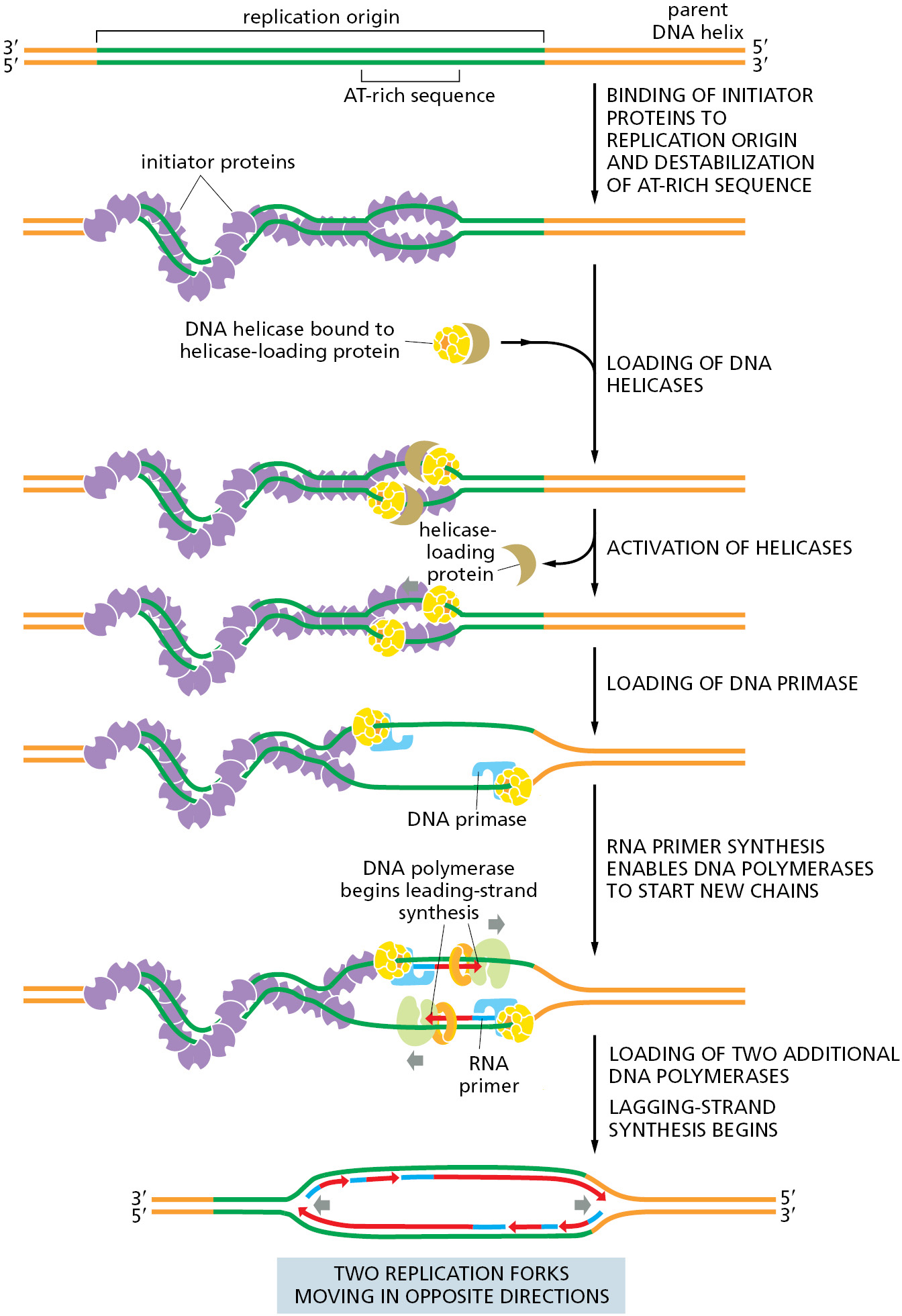
In E. coli, the interaction of the initiator proteins with the replication origin is carefully regulated, with initiation occurring only when sufficient nutrients are available for the bacterium to complete an entire round of replication. Initiation is also controlled to ensure that only one round of DNA replication occurs for each cell division. After replication is initiated, the initiator protein is inactivated by hydrolysis of its bound ATP molecule, and the origin of replication experiences a refractory period. The refractory period is caused by a delay in the methylation of newly incorporated A nucleotides in the origin (Figure 5–27). Initiation cannot occur again until the A’s are methylated and the initiator protein is restored to its ATP-bound state, conditions that are met only when the cell is capable of carrying out a new round of DNA replication.
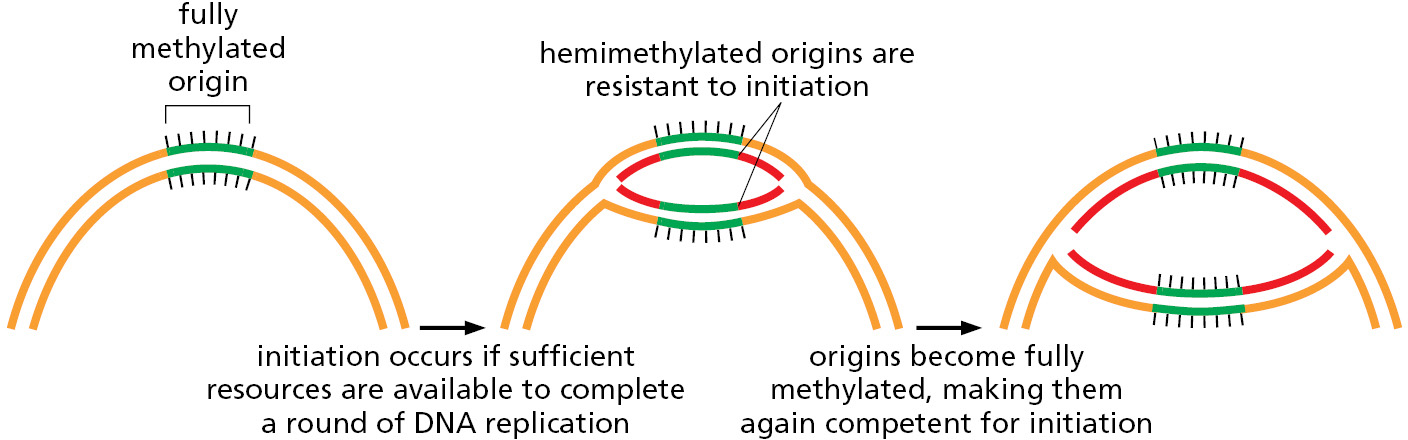
A single enzyme, the Dam methylase, is responsible for methylating all E. coli GATC sequences. As discussed earlier in the chapter, a lag in methylation after the replication of GATC sequences is also used by the E. coli mismatch proofreading system to distinguish the newly synthesized DNA strand from the parent DNA strand; in that case, the relevant GATC sequences are scattered throughout the chromosome, and they are not bound by Seq A.
Eukaryotic Chromosomes Contain Multiple Origins of Replication
We have seen how two replication forks begin at a single replication origin in bacteria and proceed in opposite directions, moving away from the origin until all of the DNA in the single circular chromosome is replicated. The bacterial genome is sufficiently small for these two replication forks to duplicate the genome in about 30 minutes. Because of the much greater size of most eukaryotic chromosomes, a different strategy is required to allow their replication in a timely manner.
A method for determining the general pattern of eukaryotic chromosome replication was developed in the early 1960s that is similar to the strategy we saw earlier for visualizing bacterial replication (see Figure 5–6). Human cells growing in culture are labeled for a short time with 3H-thymidine so that the DNA synthesized during this period becomes highly radioactive. The cells are then gently lysed, and the DNA is stretched on the surface of a glass slide coated with a photographic emulsion. Development of the emulsion in the dark reveals the pattern of labeled DNA through a technique known as autoradiography. The time allotted for radioactive labeling is chosen to allow each replication fork to move several micrometers along the DNA, so that the replicated DNA can be detected in the light microscope as lines of silver grains (radioactivity exposes photographic emulsion much as light does), even though the DNA molecule itself is too thin to be visible. In this way, both the rate and the direction of replication-fork movement can be determined (Figure 5–28). From the rate at which tracks of replicated DNA increase in length with increasing labeling time, the eukaryotic replication forks are estimated to travel at about 50 nucleotides per second. This is approximately twentyfold slower than the rate at which bacterial replication forks move, possibly reflecting the increased difficulty of replicating DNA that is packaged in chromatin.
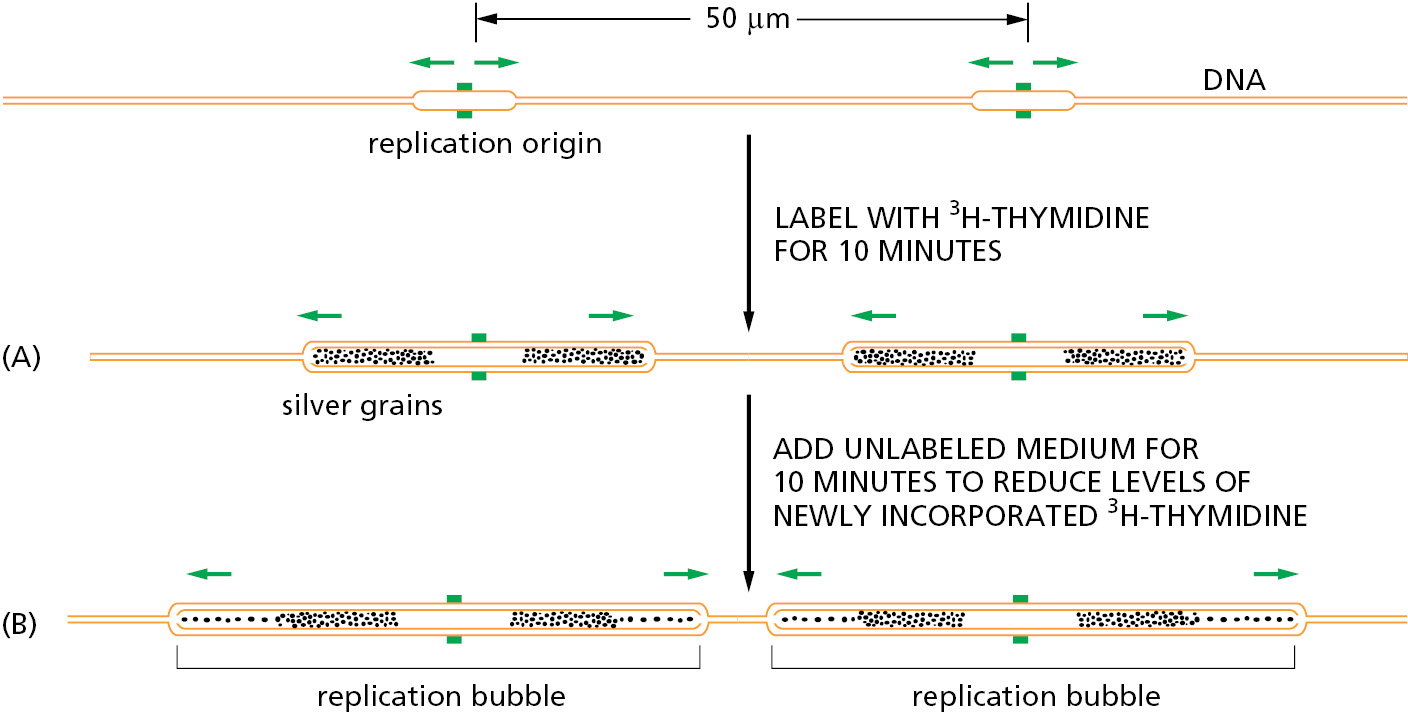
An average-size human chromosome contains a single linear DNA molecule of about 150 million nucleotide pairs. It would take 0.02 seconds/nucleotide × 150 × 106 nucleotides = 3.0 × 106 seconds (about 35 days) to replicate such a DNA molecule from end to end with a single replication fork moving at a rate of 50 nucleotides per second. As expected, therefore, the autoradiographic experiments just described reveal that many forks, belonging to separate replication bubbles, are moving simultaneously on each eukaryotic chromosome.
Much more sophisticated methods now exist for monitoring DNA replication initiation and tracking the movement of DNA replication forks across whole genomes. If a population of cells can be synchronized so they all begin DNA replication at the same time, the amount of each segment of DNA in the genome can be determined at specific time points using one of the DNA sequencing methods described in Chapter 8. Because a segment of a genome that has been replicated will contain twice as much DNA as an unreplicated segment, replication-fork initiation and fork movement can be accurately monitored across an entire genome.
Experiments of this type have shown the following: (1) Approximately 30,000–50,000 origins of replication are used each time a human cell divides. (2) The human genome has many more (perhaps tenfold more) potential origins than this, and different cell types use different sets of origins. This excess of origins may allow a cell to coordinate its active origins with other features of its chromosomes such as which genes are being expressed. The excess origins also provide “backups” in case a primary origin fails. (3) Origins of replication do not all “fire” simultaneously; rather, they often are activated in a prescribed order in a given cell type. (4) Regardless of when a given origin fires or where on the chromosome it is located, the replication forks all move at approximately the same speed. (5) As in bacteria, replication forks are formed in pairs and create an expanding replication bubble as they move in opposite directions away from a common point of origin, stopping only when they meet a replication fork moving in the opposite direction or when they reach a chromosome end. In this way, many replication forks operate independently on each chromosome and yet form two complete daughter DNA helices.
In Eukaryotes, DNA Replication Takes Place During Only One Part of the Cell Cycle
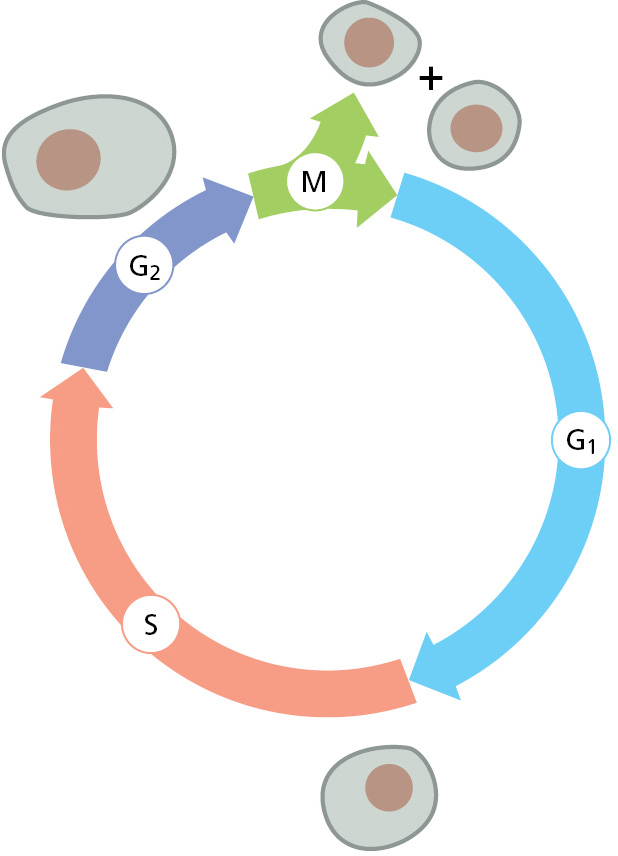
When growing rapidly, bacteria replicate their DNA nearly continually. In contrast, DNA replication in most eukaryotic cells occurs only during a specific part of the cell-division cycle, called the DNA synthesis phase, or S phase (Figure 5–29). In a mammalian cell, the S phase typically lasts for about 8 hours; in simpler eukaryotic cells such as yeasts, the S phase can be as short as 40 minutes. By its end, each chromosome has been replicated to produce two complete copies, which remain joined together at their centromeres until the M phase (M for mitosis), which soon follows. Although different origins of replication fire at different times, all DNA replication is begun and completed during S phase. In Chapter 17, we describe the control system that runs the cell cycle, and we explain how entry into each phase of the cycle requires the cell to have successfully completed the previous phase.
In the following sections, we explore how DNA replication begins on eukaryotic chromosomes and how this event is coordinated with the cell cycle.
Eukaryotic Origins of Replication Are “Licensed” for Replication by the Assembly of an Origin Recognition Complex
Having seen that a eukaryotic chromosome is replicated using many origins of replication, each of which fires at a characteristic time in S phase of the cell cycle, we turn to the nature of these origins of replication. We saw earlier in this chapter that replication origins have been precisely defined in bacteria as specific DNA sequences that attract initiator proteins, which then assemble the DNA replication machinery. We shall see that this is also the case for the single-cell budding yeast S. cerevisiae, but it appears not to be strictly true for many other eukaryotes.
For budding yeast, the location of every origin of replication on each chromosome has been determined. The particular chromosome shown in Figure 5–30—chromosome III from S. cerevisiae—is one of the smallest chromosomes known, with a length less than 1/100 that of a typical human chromosome. Its major origins are spaced an average of 30,000 nucleotide pairs apart, but only a subset of these origins is used by a given cell. Nonetheless, this chromosome can be replicated in about 15 minutes.

The minimal DNA sequence required for directing DNA replication initiation in S. cerevisiae has been determined by taking a segment of DNA that spans an origin of replication and testing smaller and smaller DNA fragments for their ability to function as origins. These DNA sequences that can serve as an origin of replication are found to contain (1) a binding site for a large, multisubunit initiator protein called ORC, for origin recognition complex; (2) a stretch of DNA that is rich in A’s and T’s and therefore easy to pull apart; and (3) at least one binding site for proteins that facilitate ORC binding, probably by adjusting the local chromatin structure.
Features of the Human Genome That Specify Origins of Replication Remain to Be Fully Understood
Compared with the situation in budding yeast, the determinants of replication origins in humans have been difficult to discover. It has been possible to identify specific human DNA sequences, each several thousand nucleotide pairs in length, that are sufficient to serve as replication origins. These origins continue to function when moved to a different chromosomal region by recombinant DNA methods, as long as they are placed in a region where the chromatin is relatively uncondensed. However, comparisons of such DNA sequences have not revealed DNA sequences in common as in the origins of bacteria and yeasts.
Despite this, a human ORC that is very similar to the yeast ORC binds to origins of replication and initiates DNA replication in humans. Many of the other proteins that function in the initiation process in yeast likewise have central roles in humans. The yeast and human initiation mechanisms are thus similar, although some property of the genome other than a specific DNA sequence has the central role in attracting an ORC to a mammalian origin of replication. Origins of replication are often nucleosome-free, and it has been proposed that DNA that is difficult to fold onto a histone core may help define origins of replication. Nearby transcriptional activity on the genome may also play a role in activating certain origins, by altering the local chromatin structures, as we discuss in Chapter 7. This idea helps to explain why different cell types—which express different sets of genes—often use different origins. Consistent with this idea, origins that fire the earliest in S phase tend to be located near highly transcribed regions of the genome.
Finally, origins located in proximity to each other tend to fire together, and it seems likely that the three-dimensional structure of chromosomes organizes origins of replication into domains, such that all the origins in a given domain fire simultaneously. All of these influences probably work together to determine how mammalian origins of replication are selected by the cell, thereby explaining the difficulty scientists have had in precisely defining their salient features.
Properties of the ORC Ensure That Each Region of the DNA Is Replicated Once and Only Once in Each S Phase
In bacteria, once the initiator protein is properly bound to the single origin of replication, the assembly of the replication forks seems to follow more or less automatically. In eukaryotes, the situation is significantly different because of a profound problem eukaryotes have in replicating chromosomes: with so many places to begin replication, how is the process regulated to ensure that all the DNA is copied once and only once?
The answer lies in how the assembly of the replication-fork protein at the origins of replication is regulated. We discuss this process in more detail in Chapter 17, where we consider the machinery that underlies the cell-division cycle. In brief, during G1 phase, a symmetrical complex of two incomplete helicases is loaded onto DNA by the bound ORC. Then, upon passage from G1 phase to S phase, specialized protein kinases come into play and direct the final assembly of the two replicative helicases, positioning one on each of the two complementary DNA single strands, where they move in opposite directions to begin opening the DNA double helix. At this point, the additional replication proteins are brought to the DNA, and two complete replication forks move in opposite directions away from the origin of replication (Figure 5–31).
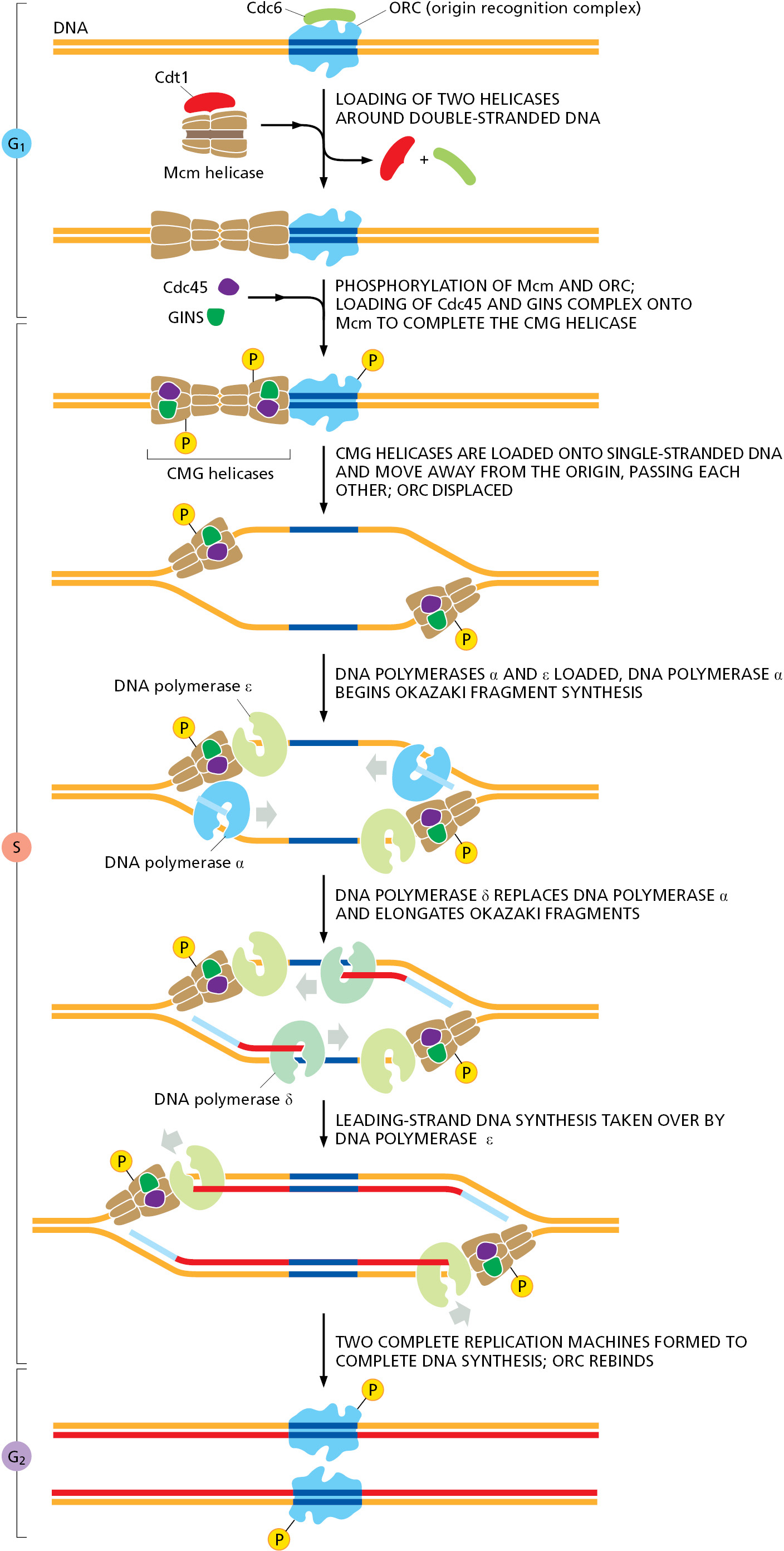
The same protein kinases that trigger the final assembly of the helicases prevent the binding of new helicases to that origin until the next M phase resets the entire cycle (for details, see pp. 1043–1045). They do this, in part, by phosphorylating ORC, rendering it unable to accept new helicases. Thus, the kinases specify a single window of opportunity for precursor helicases to be loaded at origins of replication (G1 phase, when kinase activity is low) and a second window for them to be assembled into their active form (S phase, when kinase activity is high). Because these two phases of the cell cycle are mutually exclusive and occur in a prescribed order, each origin of replication can fire only once during each cell cycle.
Because there are many more potential replication origins on a eukaryotic chromosome than are actually used in any one cell cycle (see Figure 5-30), the DNA at many ORC-bound replication origins will be replicated by forks formed at a neighboring region of the chromosome. Thus, preventing any single origin from firing more than once during an S phase is not enough to avoid the re-replication of DNA in eukaryotes. In addition, any ORC–DNA complex that is passed by a replication fork must be inactivated, and it is the combination of the two mechanisms that guarantees that each region of the DNA is replicated once and only once in each S phase.
New Nucleosomes Are Assembled Behind the Replication Fork
Several additional aspects of DNA replication are specific to eukaryotes compared with bacteria. As discussed in Chapter 4, eukaryotic chromosomes are composed of roughly equal mixtures of DNA and protein. Chromosome duplication therefore requires not only the replication of DNA but also the synthesis of new chromosomal proteins and their assembly onto the DNA behind each replication fork. Although we are far from understanding this process in detail, we are beginning to learn how the fundamental unit of chromatin packaging, the nucleosome, is duplicated. The cell requires a large amount of new histone protein, approximately equal in mass to the newly synthesized DNA, each time it divides. For this reason, most eukaryotic organisms possess multiple copies of the gene for each histone. Vertebrate cells, for example, have about 20 repeated gene sets, most containing the genes that encode all five histones (H1, H2A, H2B, H3, and H4).
Unlike most proteins, which are made continually, histones are synthesized mainly in S phase, when the level of histone mRNA increases about fiftyfold as a result of both increased transcription and decreased mRNA degradation. The major histone mRNAs are degraded within minutes when DNA synthesis stops at the end of S phase. The mechanism depends on special properties of the 3′ ends of these mRNAs, as discussed in Chapter 7. In contrast to their mRNAs, the histone proteins themselves are remarkably stable and may survive for many generations. The tight linkage between DNA synthesis and histone synthesis appears to reflect a feedback mechanism that monitors the level of free histone to ensure that the amount of histone made exactly matches the amount of new DNA synthesized.
As a replication fork advances it must pass through the parent nucleosomes. In the cell, efficient replication requires chromatin remodeling complexes (discussed in Chapter 4) and histone chaperone proteins (discussed below) to destabilize the DNA–histone interfaces. Aided by such specialized proteins, replication forks can transit even highly condensed chromatin. As a replication fork passes through chromatin, the histones are transiently displaced leaving about 600 nucleotide pairs of “free” DNA in its wake. The reestablishment of nucleosomes behind a moving fork occurs in an intriguing way. When a nucleosome is traversed by a replication fork, the histone octamer is broken into an H3–H4 tetramer and two H2A–H2B dimers (discussed in Chapter 4), all of which are released from DNA. The H3–H4 tetramers remain in the vicinity of the fork by loosely binding to several of the proteins at the replication fork (primarily the CMG helicase) and are distributed at random to one or the other daughter duplexes as the fork moves forward. In contrast, the H2A–H2B dimers are released completely from the fork and may diffuse to entirely different chromosomes. Freshly made H3–H4 tetramers are added to the newly synthesized DNA to fill in the “spaces,” and H2A–H2B dimers—half of which are old and half new—are then added at random to complete the nucleosomes behind the fork (Figure 5–32). The formation of new nucleosomes behind a replication fork has an important consequence for the process of DNA replication itself. As DNA polymerase δ discontinuously synthesizes the lagging strand (see Figure 5–19), the length of each Okazaki fragment is determined by the point at which DNA polymerase δ is blocked by a newly formed nucleosome. This tight coupling between nucleosome duplication and DNA replication probably explains why the length of Okazaki fragments in eukaryotes (∼200 nucleotides) is approximately the same as the nucleosome repeat length.
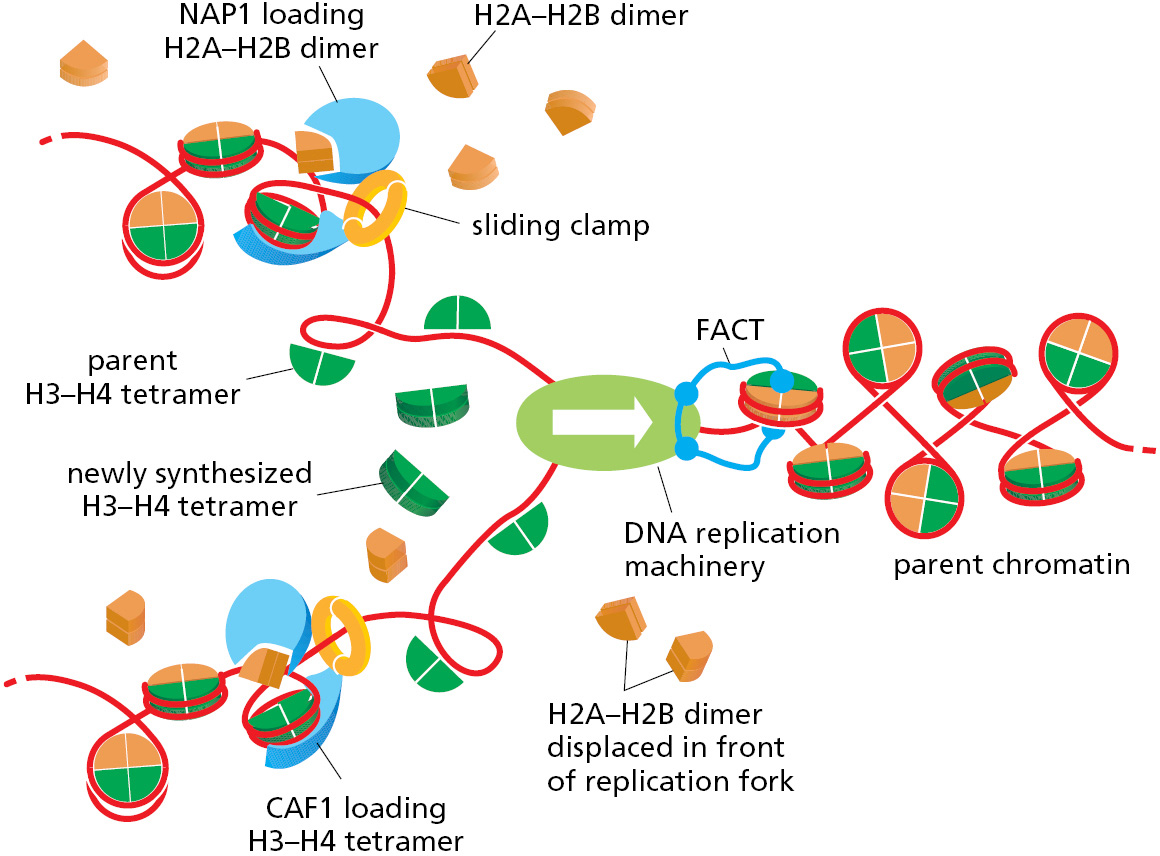
The orderly and rapid addition of new H3–H4 tetramers and H2A–H2B dimers behind a replication fork requires histone chaperones (also called chromatin assembly factors). These multisubunit complexes bind the highly basic histones and release them on DNA only in the appropriate context. For example, some of the histone chaperones, along with their histone cargoes, are directed to newly replicated DNA through a specific interaction with the sliding clamp (see Figure 5–32). As we have seen, these clamps remain on the DNA behind replication forks, and some appear to linger just long enough for the histone chaperones to complete their tasks. Because they bind so well to histones, some histone chaperones also help to disassemble nucleosomes. Of particular importance to DNA replication is the FACT chaperone, which moves at the front of the replication machinery, disassembling nucleosomes as it moves forward (see Figure 5–32).
Termination of DNA Replication Occurs Through the Ordered Disassembly of the Replication Fork
We saw earlier in this chapter that E. coli DNA replication begins at a single origin, and two replication forks proceed bidirectionally around the circular genome, meeting at a spot opposite to the origin of replication. Here, the two forks do not simply collide with each other running at full speed; rather, this spot on the E. coli genome has a special DNA sequence that slows down and stalls the movement of each fork, causing them to disassemble. The remaining gaps in the daughter DNA molecules are filled in and sealed by repair DNA polymerases and DNA ligase (see Figures 5–11 and 5–12), and the two completed bacterial genomes are separated using topoisomerases (see Figure 5–23).
As might be expected, the situation in eukaryotes is more complicated. First, each round of replication requires many termination events, roughly as many as there are initiation events at origins of replication. Thus, in mammalian cells, approximately 30,000–50,000 termination events occur in every S phase. Second, the termination of replication forks in eukaryotes is largely independent of any underlying DNA sequence in the genome. Rather, the principal termination signal is a head-on encounter with a fork moving in the opposite direction. When two forks meet, the CMG helicase at each fork is covalently modified by addition of ubiquitin (see Figure 3–65), which causes its disassembly and removal from DNA. Without the helicase, the other replication proteins rapidly dissociate from the fork. Repair DNA polymerase and DNA ligase subsequently fill in and seal any remaining gaps. Eukaryotic replication forks must also contend with the ends of chromosomes. Here, it is believed that the CMG helicase simply slides off the end of the DNA molecule, leading to the dissociation of the other fork proteins. However, replicating DNA to the very end of a chromosome presents a special challenge to the eukaryotic cell, as we describe next.
Telomerase Replicates the Ends of Chromosomes
We saw earlier in the chapter that synthesis of the lagging strand at a replication fork must occur discontinuously through a backstitching mechanism that produces short DNA fragments attached to RNA primers. The final RNA primer synthesized on the lagging-strand template cannot be replaced by DNA because there is no primer ahead of it to provide a 3′-OH end for the repair polymerase. Without a mechanism to deal with this problem, DNA would be lost from the ends of all chromosomes each time a cell divides.
Bacteria avoid this “end-replication” problem by having circular DNA molecules as chromosomes, as we have seen. Eukaryotes solve it in a different way: they have specialized nucleotide sequences at the ends of their chromosomes that are incorporated into structures called telomeres (discussed in Chapter 4). Telomeres contain many tandem repeats of a short sequence that is similar in organisms as diverse as protozoa, fungi, plants, and mammals. In humans, the sequence of the repeat unit is GGGTTA, and it is repeated roughly a thousand times at each telomere.
Telomere DNA sequences are recognized by sequence-specific DNA-binding proteins that attract an enzyme, called telomerase, that replenishes these sequences each time a cell divides. Telomerase recognizes the tip of an existing telomere DNA repeat sequence and elongates it in the 5′-to-3′ direction, using an RNA template that is a component of the enzyme itself to synthesize new DNA copies of the repeat (Figure 5–33). The enzymatic portion of telomerase resembles other reverse transcriptases, proteins that synthesize DNA using an RNA template, although, in this case, the telomerase RNA also contributes to the active site and is essential for efficient catalysis. After extension of the parent DNA strand by telomerase, replication of the lagging strand at the chromosome end can be completed by the conventional DNA polymerases, using these extensions as a template to synthesize the complementary strand (Figure 5–34).
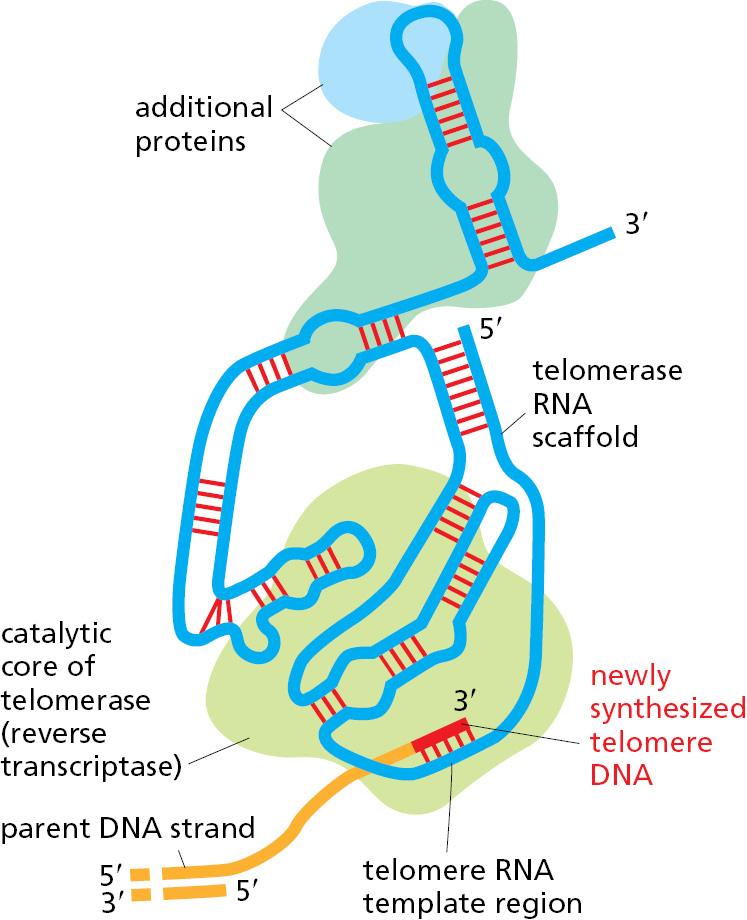
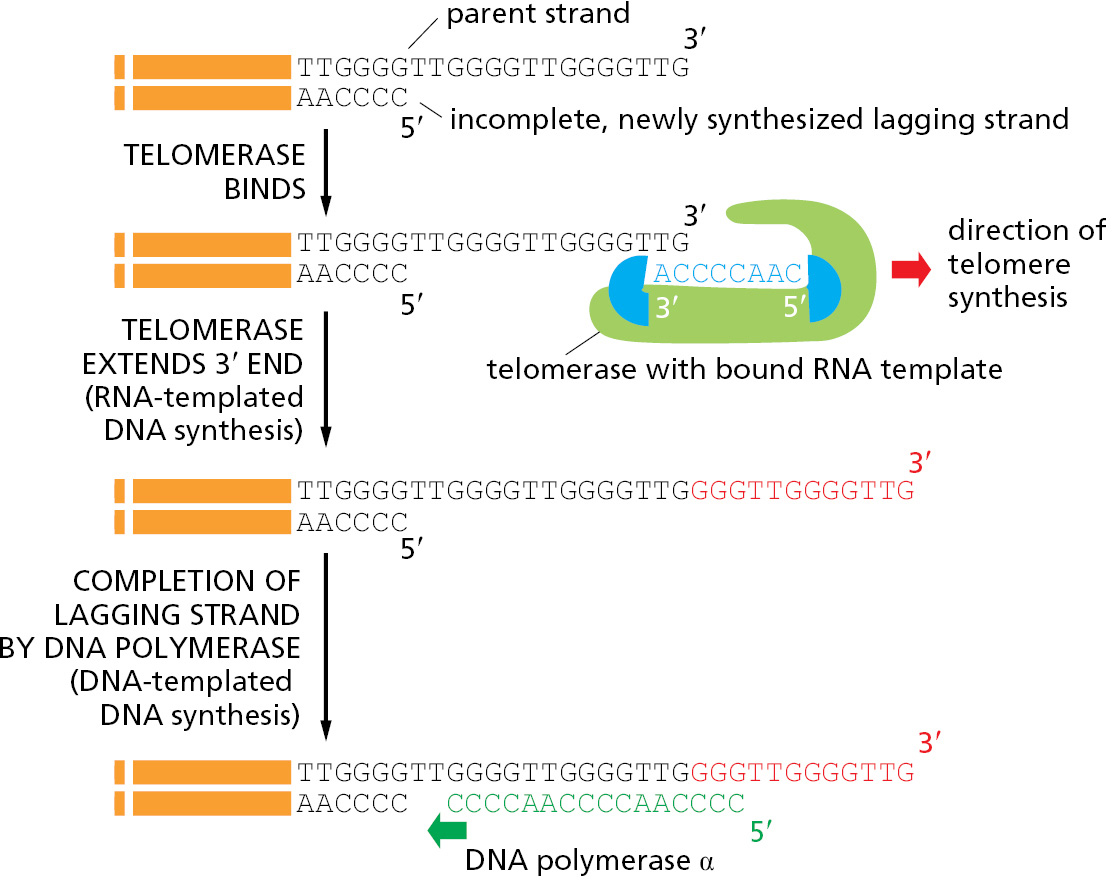
{kind=link}
Telomeres Are Packaged into Specialized Structures That Protect the Ends of Chromosomes
The ends of chromosomes present cells with an additional problem. As we will see in the next part of this chapter, when a chromosome is accidently broken into two pieces, the break is rapidly repaired. Telomeres must clearly be distinguished from these accidental breaks; otherwise, the cell will attempt to “repair” telomeres, generating chromosome fusions and other genetic abnormalities. Telomeres have several features to prevent this from happening.
A specialized nuclease chews back the 5′ end of a telomere leaving a protruding, single-strand 3′ end. This protruding end—in combination with the GGGTTA repeats in telomeres—attracts a group of proteins that form a protective chromosome cap known as shelterin. In particular, shelterin protects telomeres from being treated as damaged DNA. Another feature of telomeres may offer additional protection. When human telomeres are artificially cross-linked and viewed by electron microscopy, structures known as “t-loops” can be observed in which the protruding single-strand end of the telomere loops back and tucks itself into the duplex DNA of the telomere repeat sequence (Figure 5–35). An attractive idea is that t-loops are orchestrated by shelterin to help “hide” the very ends of chromosomes.
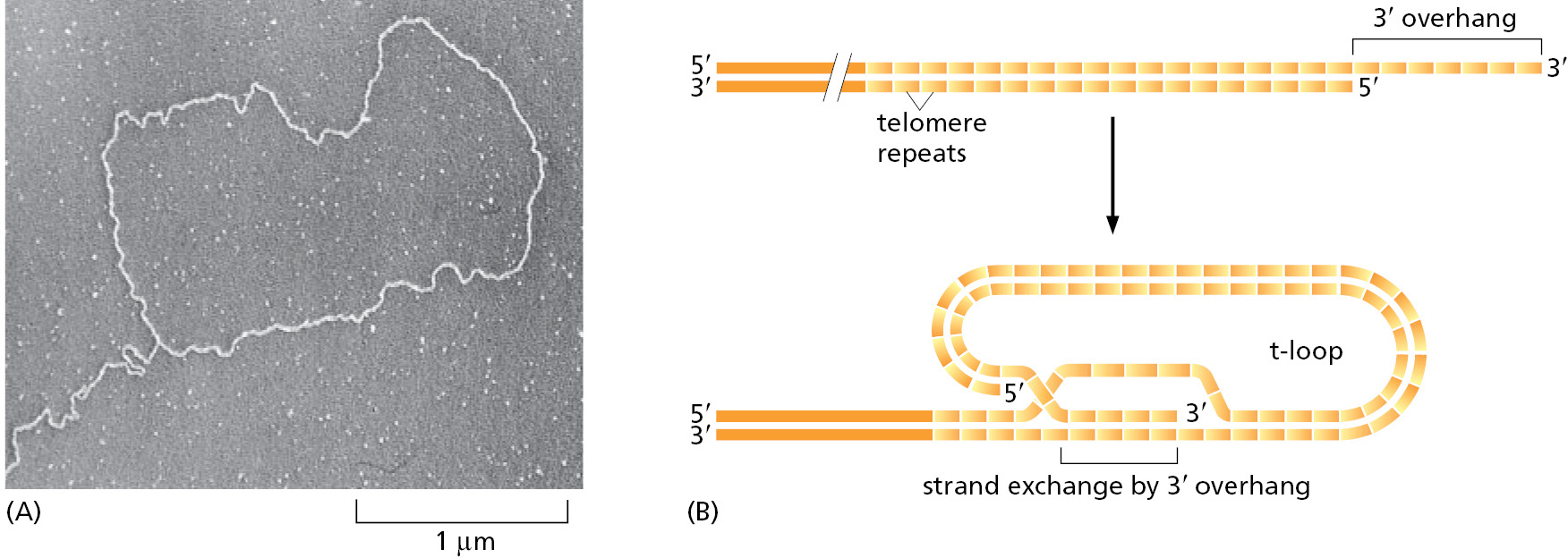
Telomere Length Is Regulated by Cells and Organisms
Because the processes that grow and shrink each telomere sequence are only approximately balanced, chromosome ends contain variable numbers of telomeric repeats. Not surprisingly, many cells, including stem cells and germ cells, have homeostatic mechanisms that maintain the number of these repeats within a limited range (Figure 5–36).
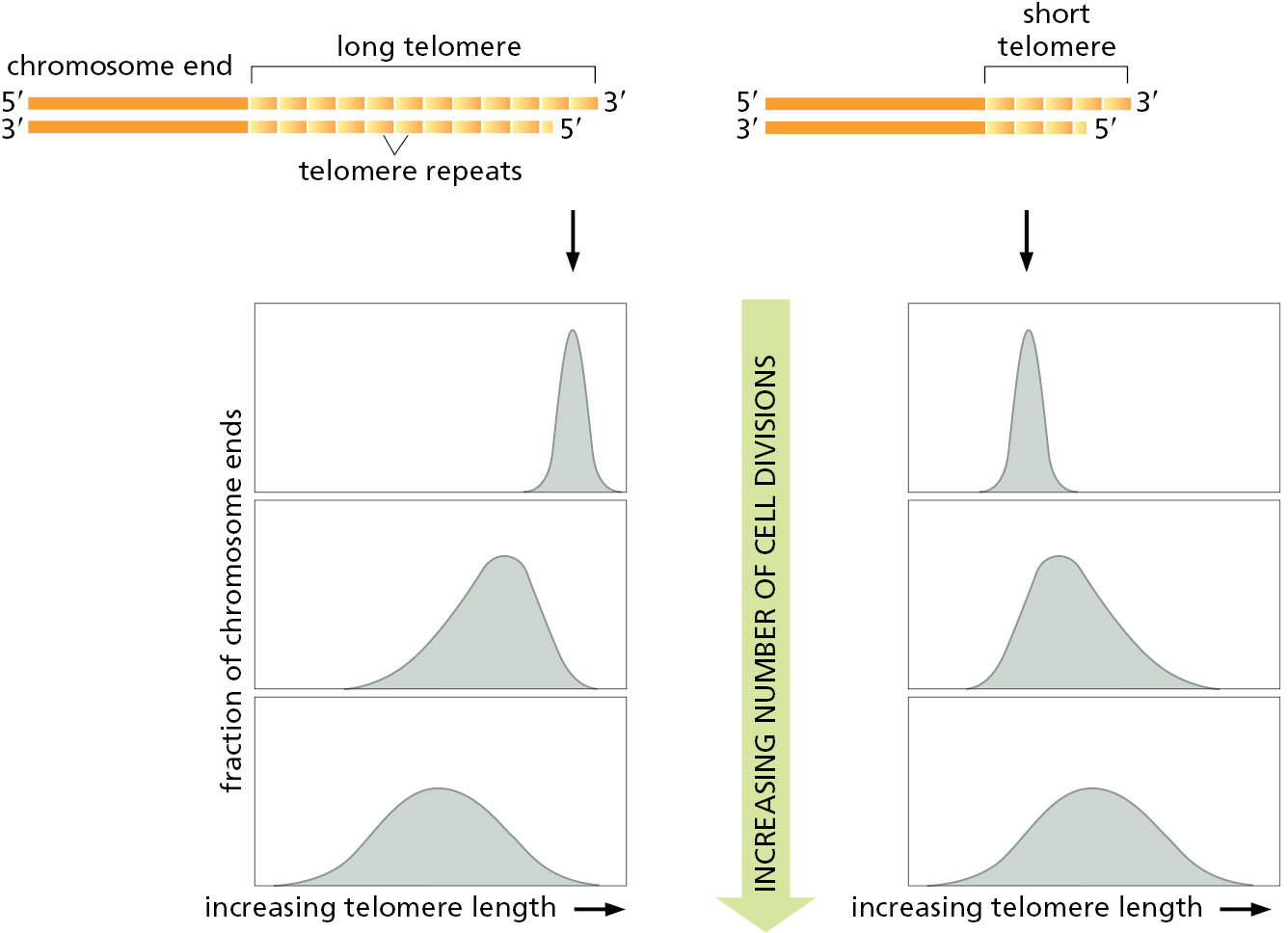
In most of the dividing somatic cells of humans, however, telomeres gradually shorten, and it has been proposed that this provides a counting mechanism that helps prevent the unlimited proliferation of wayward cells in adult tissues. In its simplest form, this idea holds that our somatic cells start off in the embryo with a full complement of telomeric repeats. These are then eroded to different extents in different cell types. Some stem cells, notably those in tissues that must be replenished at a high rate throughout life—bone marrow or gut lining, for example—retain full telomerase activity. However, in many other types of cells, the level of telomerase is reduced so that the enzyme cannot quite keep up with chromosome duplication. Such cells lose 100–200 nucleotides from each telomere every time they divide. After many cell generations, the descendant cells will inherit chromosomes that lack functioning telomeres, and, as a result of this defect, activate a DNA-damage response causing them to withdraw permanently from the cell cycle and cease dividing—a process called replicative cell senescence (discussed in Chapters 17 and 20). In theory, such a mechanism could provide a safeguard against the uncontrolled cell proliferation of abnormal cells in somatic tissues, thereby helping to protect us from cancer.
The idea that telomere length acts as a “measuring stick” to count cell divisions and thereby regulate the lifetime of the cell lineage has been tested in several ways. For certain types of human cells grown in tissue culture, the experimental results support such a theory. Human fibroblasts normally proliferate for about 60 cell divisions in culture before undergoing replicative cell senescence. Like most other somatic cells in humans, fibroblasts produce only low levels of telomerase, and their telomeres gradually shorten each time they divide. When telomerase is provided to the fibroblasts by inserting a fully active telomerase gene, telomere length is maintained and many of the cells now continue to proliferate indefinitely. Also consistent with these ideas is the observation that, in approximately 90% of cancer cells, the telomerase gene has become reactivated, thereby circumventing the normal safety mechanism (see pp. 1073–1074).
It has been proposed that this type of control on cell proliferation may contribute to the aging of animals like ourselves. These ideas have been tested by producing transgenic mice that lack telomerase entirely. The telomeres in mouse chromosomes are about five times longer than human telomeres, and the mice must therefore be bred through three or more generations before their telomeres have shrunk to the normal human length. It is therefore perhaps not surprising that the first generations of mice develop normally. However, the mice in later generations develop progressively more defects in some of their highly proliferative tissues. In addition, these mice show signs of premature aging and have a pronounced tendency to develop tumors. In these and other respects, these mice resemble humans with the genetic disease dyskeratosis congenita. Individuals afflicted with this disease carry one functional and one nonfunctional copy of the telomerase RNA gene; they have prematurely shortened telomeres and typically die of progressive bone marrow failure. These individuals also develop lung scarring and liver cirrhosis and show abnormalities in various epidermal structures including skin, hair follicles, and nails.
The above observations demonstrate that controlling cell proliferation by telomere shortening poses a risk to an organism, because not all of the cells that begin losing the ends of their chromosomes will stop dividing. Some apparently become genetically unstable, but continue to divide, giving rise to variant cells that can lead to cancer. As discussed above, many of these variant cells ultimately produce high levels of telomerase, thereby ensuring their continued survival. Clearly, the use of telomere shortening as a regulating mechanism is not foolproof and, like many mechanisms in the cell, it must strike a balance between benefit and risk.
Summary
The proteins that initiate DNA replication bind to DNA sequences at a replication origin to catalyze the formation of a replication bubble with two outward-moving replication forks. The process begins when an initiator protein–DNA complex is formed that subsequently loads a DNA helicase onto the DNA template. Other proteins are then added to form the multienzyme “replication machine” that catalyzes DNA synthesis at each replication fork.
In bacteria and some simple eukaryotes, replication origins are defined by specific DNA sequences that are several hundred nucleotide pairs long. In other eukaryotes, such as humans, features that specify an origin of DNA replication are less well defined, and probably depend more on structural features of chromosomes than on specific DNA sequences.
Bacteria typically have a single origin of replication in a circular chromosome. With fork speeds of up to 1000 nucleotides per second, they can replicate their genome in less than an hour. Eukaryotic DNA replication takes place in only one part of the cell cycle, the S phase. The replication fork in eukaryotes moves about 20 times more slowly than the bacterial replication fork, and the much longer eukaryotic chromosomes each require many replication origins to complete their replication in an S phase, which typically lasts for 8 hours in human cells. The different replication origins in these eukaryotic chromosomes are activated in a sequence, determined in part by which genes are currently being transcribed and the structure of chromatin across each chromosome. After the replication fork has passed, chromatin structure is re-formed by the addition of new histones to the old histones that are directly inherited by each daughter DNA molecule.
Eukaryotes solve the problem of replicating the ends of their linear chromosomes with a specialized end structure, the telomere, maintained by a special nucleotide-polymerizing enzyme called telomerase. Telomerase extends one of the DNA strands at the end of a chromosome by using an RNA template that is an integral part of the enzyme itself, producing a highly repeated DNA sequence that typically extends for thousands of nucleotide pairs at each chromosome end. Telomeres have specialized structures that distinguish them from broken ends of chromosomes, ensuring that they are not treated as damaged DNA.
Glossary
- replication origin
- A location on a DNA molecule at which duplication of the DNA begins by the formation of replication forks.
- S phase
- The period of a eukaryotic cell cycle in which DNA is synthesized.
- histone chaperone (chromatin assembly factor)
- Protein that binds free histones, releasing them as they are incorporated into newly replicated chromatin.
- telomerase
- Enzyme that elongates the telomere sequences in DNA, which occur at the ends of eukaryotic chromosomes.