LEARNING OBJECTIVES
- Assess the soundness of social psychological research studies using specific measures of validity and reliability.
- Explain the importance of replication in science.
All research is not created equal. Just because someone has conducted a study doesn’t mean you should accept the results as fact. What sets a well-designed study apart from a flawed one? In an experiment, random assignment and a carefully designed control group can go a long way toward eliminating potential problems. But in designing any study, researchers also need to carefully consider certain types of validity and reliability as well as the statistical significance of their findings.
The previous section pointed out the weaknesses of correlational research, but experimental studies can have weaknesses, too. Sometimes experiments can be so removed from everyday life that it can be hard to know how to interpret them (Aronson et al., 1990). External validity is an indication of how well the results of a study pertain to contexts outside the conditions of the laboratory. When researchers are unable to generalize the results to real-life situations, there is poor external validity. When the purpose of the research is to be directly relevant to events in the outside world, external validity is critical. For example, if researchers are investigating whether watching violence on TV makes children more aggressive immediately after they watch the programs, the TV programs the children see in the study should resemble real TV shows, and the types of aggressive behavior examined should be behavior that children might actually engage in.
Poor external validity isn’t always a problem. Milgram’s study of obedience (discussed in Chapters 1 and 8) had poor external validity in the sense that few people in our society ever face a situation in which an authority figure commands them to harm another person. Nevertheless, Milgram’s study illuminates why such things have happened in the world and will likely happen again.
As in Milgram’s study, researchers sometimes deliberately strip down a situation to its bare essentials to make a theoretical point that would be hard to make in real-world circumstances. To find out how familiarity with a stimulus influences its attractiveness, Robert Zajonc (1968) and his colleagues showed fictitious Turkish words and fake Chinese characters to Americans, presenting some of them many times and some of them only a few times (Figure 2.3). The more times participants saw a given stimulus, the more they thought the stimulus referred to something good. The experiment had poor external validity because the experimental situation was unlike something anyone would ever encounter in real life. But the simplicity of the situation and the initial unfamiliarity of the foreign words and characters ensured that the sheer number of repetitions of the “words,” and not something else about the stimuli, affected their attractiveness. In research like Zajonc’s, in which the purpose is to clarify a general idea or theory, external validity is not essential.
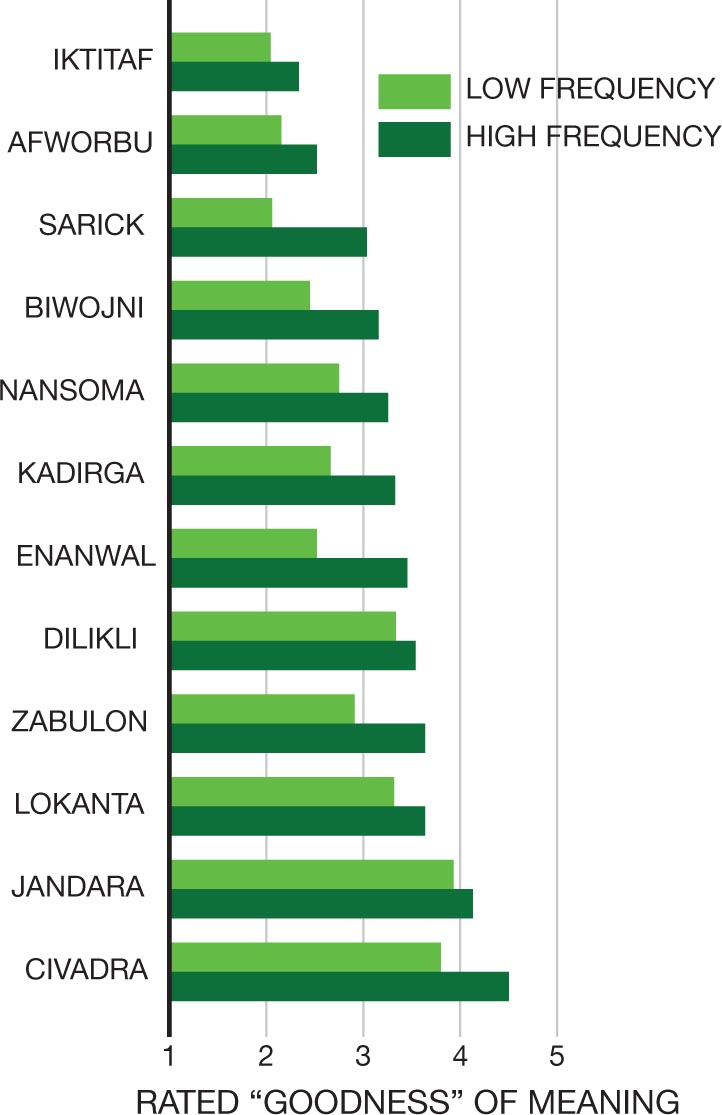
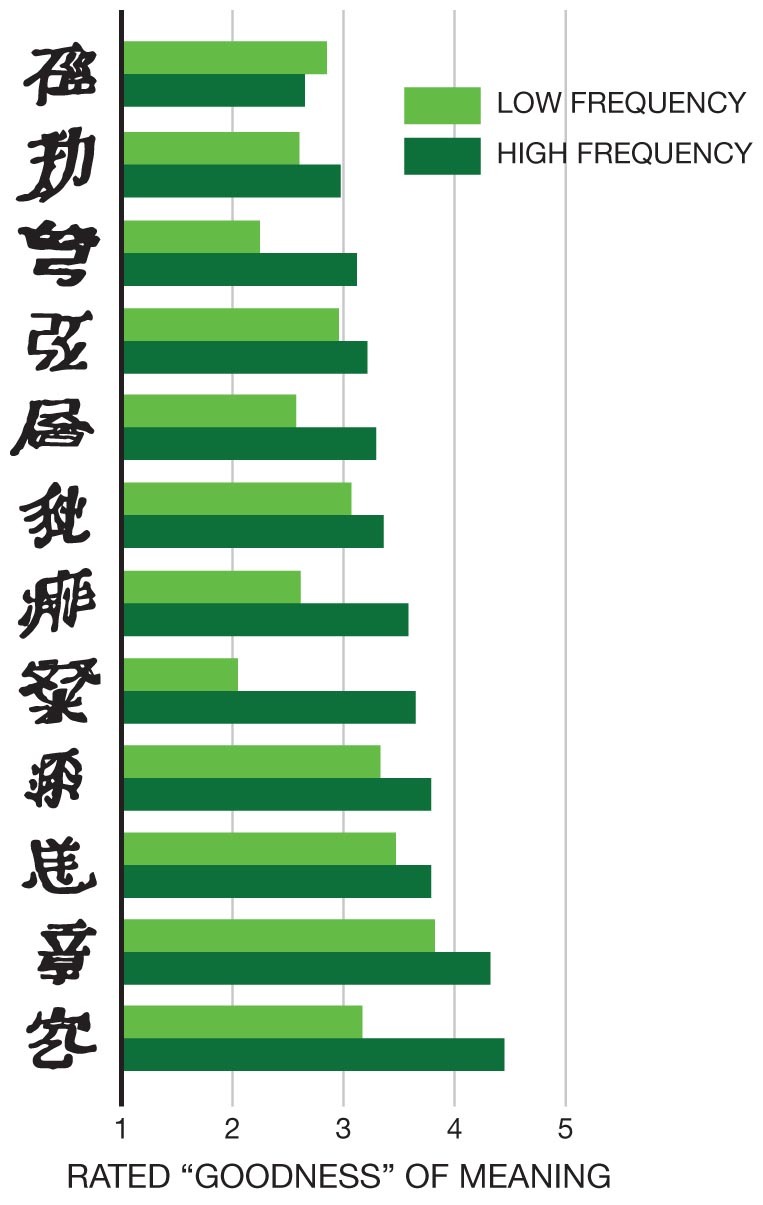
The horizontal bar graph on the left shows fictitious Turkish words on the vertical axis and rated goodness of meaning along the horizontal axis, ranging from 1 to 5 in increments of 1. Two bars, representing low and high frequency, are depicted for each fictitious Turkish word. The low and high frequencies in each Turkish word are as follows: IKTITAF: 2.1 and 2.3; AFWORBU: 2.2 and 2.5; SARICK: 2.1 and 3.1; BIWOJNI: 2.5 and 3.2; NANSOMA: 2.8 and 3.2; KADIRGA: 2.7 and 3.25; ENANWAL: 2.5 and 3.3; DILIKLI: 3.3 and 3.5; ZABULON: 2.9 and 3.6; LOKANTA: 3.2 and 3.6; JANDARA: 3.9 and 4.2; CIVADRA: 3.8 and 4.5. The horizontal bar graph on the right shows made-up Chinese characters on the vertical axis and rated goodness of meaning along the horizontal axis, ranging from 1 to 5 in increments of 1. Two bars, representing low and high frequency, are depicted for each made-up Chinese character. The low and high frequencies in each made-up Chinese character are as follows: First character: 2.9 and 2.7; second character: 2.6 and 2.9; third character: 2.3 and 3.2; fourth character: 2.95 and 3.2; fifth character: 2.6 and 3.3; sixth character: 3.1 and 3.3; seventh character: 2.6 and 3.6; eighth character: 2.01 and 3.6; ninth character: 3.3 and 3.8; tenth character: 3.4 and 3.8; eleventh character: 3.8 and 4.3; twelfth character: 3.2 and 4.5. All the values are approximate.
One of the best ways to ensure external validity is to conduct a field experiment. Similar conceptually to a laboratory experiment, a field experiment takes place in the real world, usually with participants who are unaware that they are involved in a research study at all. An example would be an experiment in which researchers study the reactions of people who are asked to give up their seats on an uncrowded bus or train.
In the field experiment described at the beginning of this chapter, Cohen and Nisbett (1997) examined business owners’ reactions to a letter allegedly written by a job applicant who had been convicted of a felony. The felony in question was either a motor vehicle theft or, in the version you read, a homicide in the context of a love triangle. The dependent variable was the business owner’s degree of responsiveness to the applicant’s letter, ranging from failing to respond at all to sending an encouraging letter and an application form. Southern retailers were much more encouraging than Northern retailers toward the man convicted of homicide. The experiment provides, in a field setting, evidence that Southern norms concerning violence in response to an insult are more accepting than Northern norms. Because there was no difference in the reactions of Southerners and Northerners to the letter that mentioned a theft, we know that Southerners are not simply more forgiving of crimes generally. Thus, the theft letter constitutes a control condition in this field experiment. And because the participants were potential employers who believed that they were responding to a real applicant, the experiment’s external validity is much higher than it would be if the participants had been asked to assess fictional job applicants in a laboratory setting.
Even when research results can be shown to apply to the real world, there is the related question of how broadly applicable they are. The best known social psychological research has been performed by researchers in the United States, Canada, and Western Europe. As noted in Chapter 1, there is reason to believe that some of the findings reported by researchers in these Western, educated, industrialized, rich, and democratic (or WEIRD) countries may not apply to people in other parts of the world (Henrich et al., 2010). Cross-cultural research has been an important part of social psychology for some time, but efforts to test psychological theories in less-studied parts of the world have intensified in recent years.
Even within the WEIRD world, the preponderance of research has been conducted by a narrow demographic slice of the population and has often involved a narrow range of research participants as well. Here, too, the call has gone out to broaden the pool of scientists who are conducting psychological research and to make sure that their theories and findings do not rest solely or largely on the responses of White, educated, relatively well-off participants (Roberts et al., 2020; Sue et al., 1999). Because people truly are part of one human family, many of the results produced by social psychological research will apply to people the world over. But as you’ll see throughout this book, context and culture often matter, and consequently many patterns and tendencies observed in one group or in one part of the world may be very different in another.
Whatever the goal of an experiment, internal validity is essential. Internal validity refers to the likelihood that only the manipulated variable—and no other external influence—could have produced the results. The experimental situation is held constant in all other respects, and participants in the various experimental conditions don’t differ at all, on average, before they come to the laboratory. You’ll remember the easy way to avoid the possibility that participants will differ from each other in some unanticipated way that might influence the results: by randomly assigning them to the various experimental conditions—for example, by flipping a coin to determine the condition for each participant. Random assignment ensures that the participants in one condition will not be different, on average, from those in the other conditions—and this is essential for establishing internal validity.
An experiment lacks internal validity when there is a third variable that could plausibly account for any observed difference between the different conditions. For example, if Darley and Batson had asked their hurried and unhurried participants to take different routes to where they were to deliver their talks on the Good Samaritan, it could have been something about the different routes they took, not whether they were in a hurry, that was responsible for their results.
Internal validity also requires that the experimental setup seem realistic and plausible to the participants. If participants don’t believe what the experimenter tells them or if they don’t understand something crucial about the instructions or the nature of the task they are asked to perform, then internal validity will be lacking, and the experimenter can have no confidence in the results. In such cases, participants aren’t responding to the independent variable as conceptualized by the experimenter but to something else entirely.
Researchers can help ensure that their experimental design meets the criteria for internal validity by interviewing participants who have served in pilot studies, or preliminary versions of the experiment. Pilot study participants are generally told the purpose of the experiment afterward and what the investigators expected to find. Pilot participants can often provide useful information about how well the experiment is designed when they are brought in as consultants, so to speak, after the fact.
Reliability refers to the degree to which a measure gives consistent results on repeated occasions or the degree to which two measuring instruments (such as human observers) yield the same or very similar results. If you take an IQ test twice, do you get roughly the same score (test-retest reliability)? Do two observers agree in how they rate the charisma of a world leader or the kindness of a classmate (interrater reliability)? Reliability is typically measured by correlations between 0 and 1. As a rule of thumb, ability tests such as IQ tests are expected to have test-retest reliability correlations of about .8 or higher. Personality tests, such as verbal measures of extraversion, are expected to have that level of reliability or somewhat lower. People’s degree of agreement about the kindness or charisma of another person would likely show a correlation of at least .5.
Measurement validity refers to the correlation between a measure and some outcome the measure is supposed to predict. For example, IQ test validity is measured by correlating IQ scores with grades in school and with performance in jobs. If IQ scores predict behavior that requires intelligence, we can safely infer that the test is a valid measure of intelligence. Validity coefficients, as they are called, typically do not exceed .5. Personality tests rarely correlate with behavior in a given situation more than about .3. This result is surprising to most people, who expect that a measure of extraversion should predict quite well a person’s behavior at a party, and a measure of aggression should predict quite well a person’s behavior in a hockey game.
An investigator wants to be sure, after a study is run, that any observed difference in the dependent variable was caused by the manipulated difference in the independent variable. That can only happen when the design of the experiment is such that the study has high internal validity. Various shortcomings of experimental design can threaten internal validity and thereby call into question whether any variation in the dependent variable is in fact due to variation in the independent variable—whether the conclusion the investigator would like to draw is valid.

FOR CRITICAL THINKING
When researchers obtain an empirical result—such as observing a correlation between two variables or finding that some independent variable affects a dependent variable in an experiment—they can test the relationship’s statistical significance. Statistical significance is a measure of the probability that a given result could have occurred by chance alone. By convention, a finding achieves statistical significance if the probability of obtaining that finding by chance is less than 1 in 20, or .05, though the required probability can vary. Statistical significance is primarily determined by two factors: (1) the size of the difference between results obtained from participants in the experimental condition and the control condition of an experiment or the strength of a relationship between variables in a correlational study and (2) the number of cases on which the finding is based. The larger the difference or the strength of the relationship and the larger the number of cases, the greater the statistical significance. Even very large differences may not be significant if they are based on a small number of cases. All the findings reported in this book are statistically significant (though not all are based on large effects). There are many nuances to determining whether a finding is statistically significant, nuances you can learn more about in a statistics course.
One of the ways in which science is different from other modes of inquiry is the importance placed on replication. Replication involves the reproduction of research results by the original investigator or by someone else. If a result is genuine or valid, it should be possible for scientists to replicate it.
Some results do not replicate: Attempts to rerun a study by duplicating the procedures don’t succeed in producing the same results, calling the results into question. Sometimes the original investigator can show that the replication attempt was not carried out correctly (the procedures were not truly duplicated), and the original result may again be found if the study is repeated properly. Sometimes, it’s just by chance that a replication attempt fails: Every result, including an attempted replication, has a certain probability of being in error. Other times, a replication attempt fails because the original result itself was a fluke or the methods that produced it were not precise or sound. And sometimes (thankfully, very rarely) a reported result is the product of outright fraud, when an investigator has simply made up samples of data to support a favored hypothesis.
Failures to replicate often generate controversy (sometimes accompanied by accusations of incompetence on the part of different investigators). Ideally, these debates result in consensus about whether a particular finding should be accepted or not. In this way, science is self-correcting. Errors are made and initial interpretations may be faulty, but over time the scientific community learns to distinguish the claims we can be confident about from those that are not as solid.
In recent years, there has been increasing concern that many scientific findings do not replicate—in fields ranging from cell biology to neuroscience to drug efficacy research (Ioannidis, 2005). In 2015, Brian Nosek and dozens of other psychologists published an article in the journal Science reporting on attempts to replicate 100 psychology studies (Open Science Collaboration, 2015). They found that only 36–47 percent of the original studies were successfully replicated. Other systematic efforts to reproduce the results of findings reported in behavioral science journals have yielded higher replication rates, on the order of 78–85 percent (Camerer et al., 2016; Klein et al., 2014).
An important and frequently misunderstood statistical regularity is known as “regression to the mean”: the tendency for extreme scores on one variable to be followed by, or to accompany, less extreme scores on another variable (or scores on the same variable examined at a different time). This is a completely universal phenomenon. Extreme scores on any variable are farther away from the mean of a distribution of scores, and scores close to the mean of most distributions are more common than extreme scores farther from the mean. This pattern is visible in Figure 2.4, which shows a normal distribution, sometimes called a bell curve. Many types of variables are distributed in this fashion: IQ, physical height, annual corn yield in Iowa, the number of mistakes per day in the manufacturing of glass jars. These variables are distributed in this way because every score has a chance component: the luck of the genetic draw, the particular weather conditions last year in Iowa. Scores come to be extreme because of particular patterns of chance events that are rare and unlikely to be repeated. Extremely tall fathers have sons who are typically closer to the mean, and extremely tall sons, in turn, tend to have fathers who are closer to the mean. The rookie of the year in baseball typically doesn’t do as well in his second year. Your unhappiest day is likely to be followed by one that’s not so unhappy. When you go to the doctor with a bad cold, you’ll likely get better even if all the doctor does is say “hello.” The reason is that you probably went when your symptoms were close to their peak intensity and therefore had no place to go except down—in other words, back toward the mean of your health distribution. (This isn’t true, of course, for progressive diseases such as arthritis or cardiovascular problems.)
An interesting application of the concept of regression to the mean was noted by Daniel Kahneman in his attempt to improve the training of Israeli pilots (Kahneman & Tversky, 1973b). Kahneman told the instructors that a general principle of learning is that people benefit more from positive feedback, which informs them about what they’re doing right, than they do from negative feedback, which tells them what they’re doing wrong. The instructors insisted that this principle, however valid in a psychology laboratory, did not apply to pilot training: When they praised an unusually good maneuver, the novice pilot typically performed worse the next time around. Moreover, if they shouted at the pilot for a particularly bad performance, the pilot nearly always performed better the next time around. But of course, the instructor could say nothing at all and get the same results simply due to regression to the mean: A particularly good performance would typically be followed by a worse one the next time a maneuver was tried, and a particularly bad performance would typically be followed by a better one the next time around. Once the instructors understood this idea, they got better results, and novice pilots had a more pleasant training experience.
Regression to the mean, at its core, is probabilistic. The reason the rookie of the year did so well is that the stars aligned just right: The athlete was in perfect health and had no injuries, there were no family or love life problems, and the team had just hired the best coach in the league. The odds are against such a confluence of favorable events the next year.
Regression to the mean is an extremely important concept to have in your critical thinking toolbox. Once you have it firmly in mind, you’ll see it crop up constantly as you observe and think about human behavior and about all kinds of other events that have a chance component. Before jumping to conclusions about a pattern that might seem meaningful, ask yourself, “Might this just be another example of regression to the mean?”
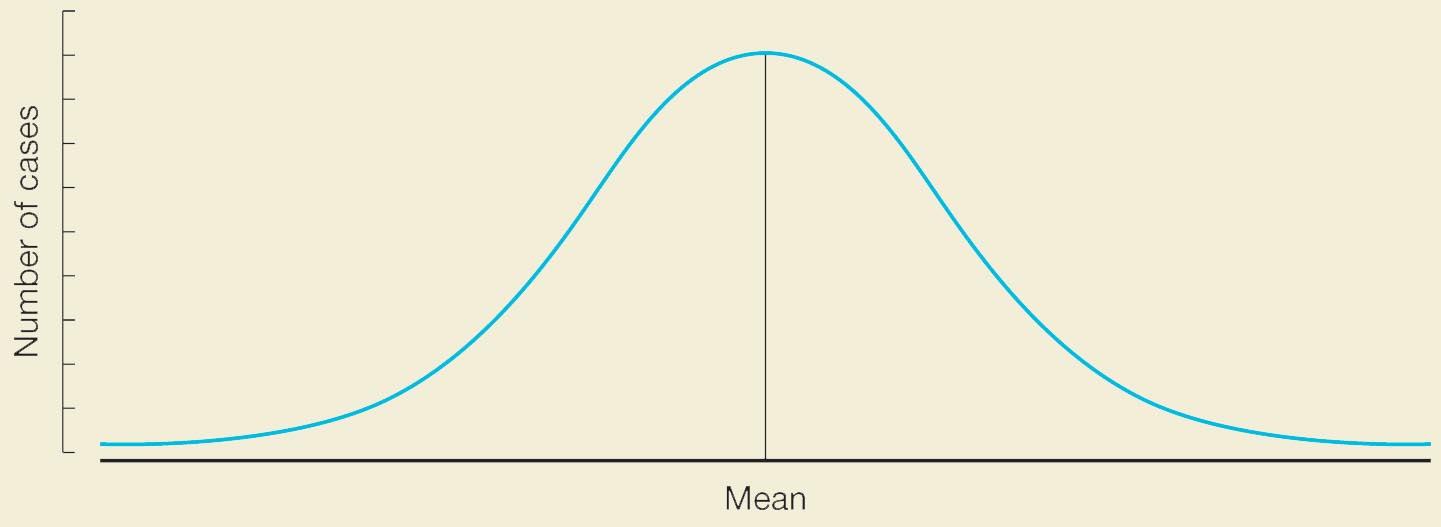
The graph depicts a bell-shaped curve above a horizontal axis, which tapers off at both ends, along either extremes of the horizontal axis. A vertical line, representing the mean, extends upward from the horizontal axis to the peak of the bell curve, such that the curve is symmetrical about this vertical line. The height of the vertical line denotes the number of cases.
But even the latter rates may not be high enough for comfort, and the issue of replication has generated a great deal of debate about how to ensure that readers of scientific journals can have confidence in the reported results (D. T. Gilbert et al., 2016; Lilienfeld & Strother, 2020; Maxwell, Lau, & Howard, 2015; Renkewitz & Heene, 2019). These debates have inspired a host of new research practices that, in combination, should improve the replicability of reported research (De Boeck & Jeon, 2018; Simons, Holcombe, & Spellman, 2014; Nelson, Simmons, & Simonsohn, 2018; Simmons, Nelson, & Simonsohn, 2011).
Note that in social psychology, some failures to replicate are nearly inevitable because of the very nature of the subject matter. For example, research conducted in the early part of this century found that exposing people to images of the American flag made them more politically conservative (T. Carter, Ferguson, & Hassin, 2011). Subsequent studies failed to find that “priming” people with the flag had any effect (Klein et al., 2014). When the initial studies were conducted, Republican George W. Bush was in the White House—a president and an administration marked by the tragic events of September 11, 2001, and an aggressive military response to those events. But the political atmosphere changed after Barack Obama was elected president in 2008, and this may have changed the associations many people had with the U.S. flag, altering the very psychology that led to the original reported effects.
Thus, context matters, and as the world itself changes, we should expect some research findings not to replicate even if the basic psychological principles underlying the original research are valid. That said, some failures to replicate are due to shoddy work on the part of the original investigators, which produced results that were never, in fact, true or valid. In those cases, investigators who report failed attempts to replicate do a great service to everyone by setting the record straight.
Among the changes that have been put in place to increase the replicability of research findings is a substantial increase in the sample sizes generally used in research. With small sample sizes, it’s easier to obtain apparently significant results that are, in reality, just flukes. Another remedy has been the insistence that investigators report the results of all measures collected and all experimental conditions run in their studies. If an investigator obtains statistically significant results on one measure—but not on several other measures that, theoretically, should yield similar results—there’s reason to worry that the one significant result may be a fluke (a “false positive” error). Reporting the results of all measures rather than highlighting a subset of measures serves as a safeguard against such errors. Still another proposed remedy has been the call for investigators to preregister and make public their methods, hypotheses, and data analysis procedures before they conduct their research. Preregistration prevents researchers from hypothesizing after the fact, and, as a result, from cherry-picking only those analyses and results that support their claims—including those claims that the investigators only thought to make after seeing the results of their studies.
Preregistration is only one part of open science: the broad approach to ensuring that scientific research is sound and that reported results are likely to replicate. Just as transparency is seen as the best remedy for combating corruption in government, publicizing all the steps taken and results obtained in a program of research serves as both a deterrent to and a check on shoddy research. When investigators share their methods and data with any interested party, it is easier to check whether reported findings stand up to scrutiny and to conduct replications that are truly informative.
In this textbook, we have tried to be scrupulous about noting when the evidence about a given point is mixed, usually because of replication failures or the existence of similar studies that produced a different result. There are no guarantees in any science. Social psychology is an ever-evolving field. It’s a safe bet that some of the findings reported in this textbook (not a large number, we suspect) will turn out to be mistaken or misleading. But we are confident that, over time, social psychologists will weed out those findings that are illusory and leave us with those that are genuine.
External validity refers to how well the results of a study generalize to contexts outside the laboratory. Internal validity refers to the extent to which investigators can know that only the manipulated variable could have produced the results of a study. Reliability refers to the degree to which different measuring instruments or the same instrument at different times produces the same values for a given variable. Measurement validity refers to the extent to which a measure predicts outcomes that it is supposed to measure. Statistical significance is a measure of the probability that a result could have occurred by chance. Replication of results increases our confidence in them, and it is important for reported results to be subject to attempts at replication. Doing so allows social psychologists to distinguish between those results that are truly solid from those that are illusory.