QUESTION 5–1
Which of the following statements are correct? Explain your answers.
- A DNA strand has polarity because its two ends contain different bases.
- G-C base pairs are more stable than A-T base pairs.
Long before biologists understood the structure of DNA, they had recognized that inherited traits and the genes that determine them were associated with chromosomes. Chromosomes (named from the Greek chroma, “color,” because of their staining properties) were discovered in the nineteenth century as threadlike structures in the nucleus of eukaryotic cells that become visible as the cells begin to divide (Figure 5–1). As biochemical analyses became possible, researchers learned that chromosomes contain both DNA and protein. But which of these components encoded the organism’s genetic information was not immediately clear.
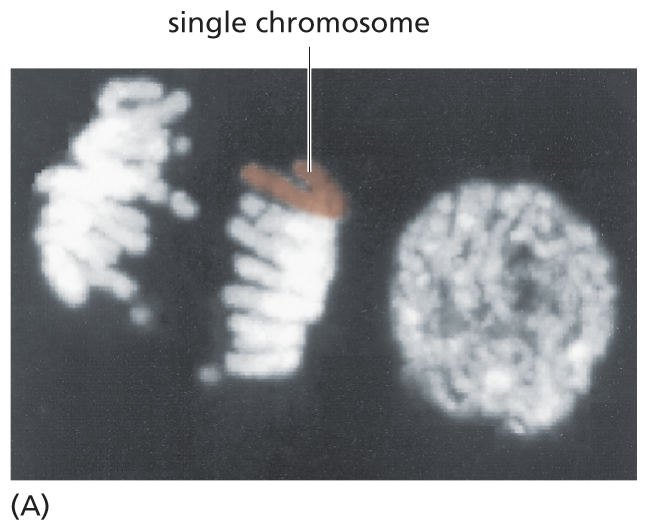
A micrograph depicts chromosomes during cell division. The micrograph features two cells. The dividing cell on the left has two distinct units made of multiple chromosomes separating with a single chromosome highlighted and labeled in one unit. The non-dividing cell has a rounded single unit that contains all the D N A.
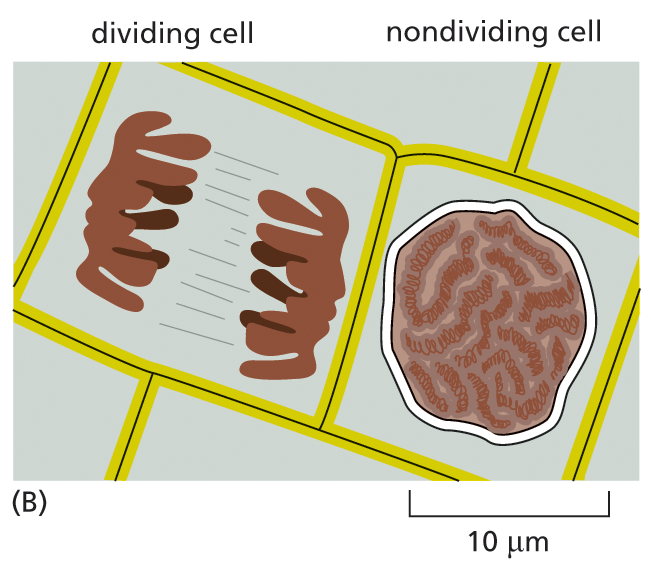
A schematic illustration features two cells. A dividing cell on the left has two distinct units, with a single chromosome highlighted and labeled in one unit. The non-dividing cell has a rounded single nucleus measuring about 10 micrometers in diameter.
We now know that the DNA carries the genetic information of the cell and that the protein components of chromosomes function largely to package and control the enormously long DNA molecules. But biologists in the 1940s had difficulty accepting DNA as the genetic material because of the apparent simplicity of its chemistry (see How We Know, pp. 203–205). DNA, after all, is simply a long polymer composed of only four types of nucleotide subunits that are chemically very similar to one another.
Then, early in the 1950s, Maurice Wilkins and Rosalind Franklin examined DNA using x-ray diffraction analysis, a technique for determining the three-dimensional atomic structure of a molecule (see Panel 4–6, pp. 174–175). Their results provided one of the crucial pieces of evidence that led, in 1953, to Watson and Crick’s model of the double-helical structure of DNA. This structure—in which two strands of DNA are wound around each other to form a helix—immediately suggested both how DNA could encode the instructions necessary for life, and how these instructions could be copied and passed along when cells divide. In this section, we examine the structure of DNA and explain in general terms how it is able to store hereditary information.
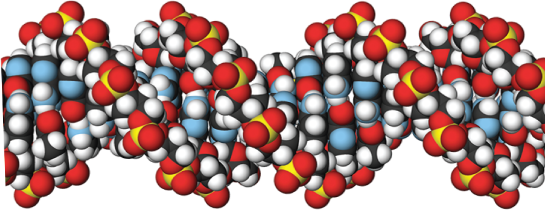
A molecule of deoxyribonucleic acid (DNA) consists of two long polynucleotide chains. Each chain, or strand, is composed of four types of nucleotide subunits, and the two strands are held together by hydrogen bonds between the base portions of the nucleotides (Figure 5–2).
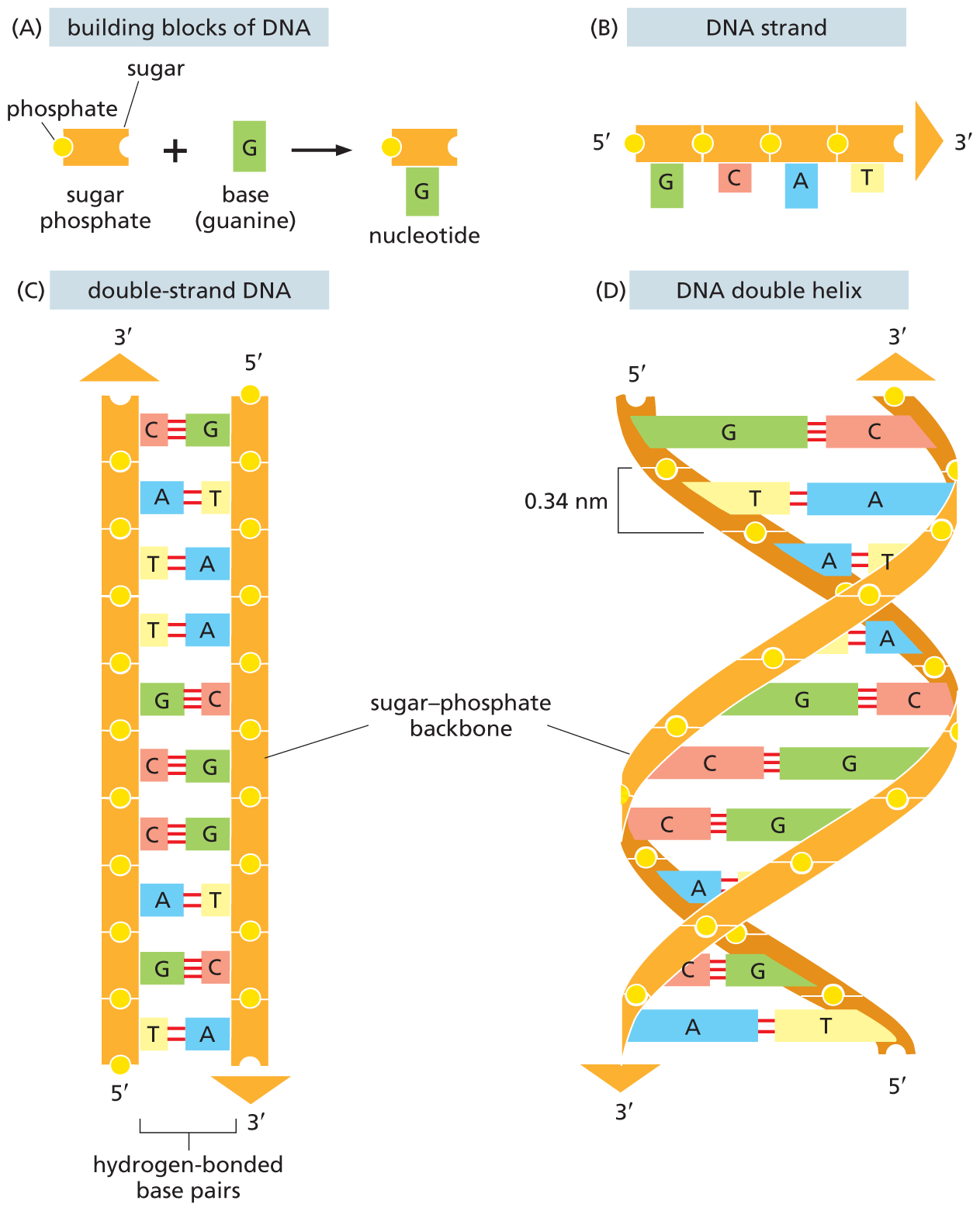
A four-part illustration shows the structural components of D N A. Section A shows the building blocks of D N A. It comprises a sugar phosphate unit made of a sugar and a phosphate plus a base G (guanine) which forms a nucleotide (sugar phosphate unit bound to base G).
Section B shows a 5-prime to 3-prime D N A strand. The strand shows a linear chain of four sugar phosphate units. The first sugar phosphate unit is attached to base guanine (G), the second sugar phosphate unit is attached to base cytosine (C), the third sugar phosphate unit is attached to adenine (A), and the fourth sugar phosphate unit is attached to thymine (T).
Section C shows a double-stranded D N A, with two sugar phosphate backbones, between which the bases are hydrogen bonded. C is paired with G; A with T. The strand on the left has the 3-prime end on top, which has an upward arrow pointer on top. The strand on the right has the 3-prime end at the bottom, below which is a downward arrow pointer.
Section D shows the double helical structure of D N A, with two sugar phosphate backbones, between which the bases are hydrogen bonded. The distance between two phosphate units in the sugar phosphate backbone is 0.34 nanometers. The strand on the right has the 3-prime end on top, which has an upward arrow pointer on top. The strand on the left has the 3-prime end at the bottom, below which is a downward arrow pointer.
Figure 5–2 DNA is made using four nucleotide building blocks. (A) Each nucleotide is composed of a sugar phosphate covalently linked to a base—guanine (G) in this figure. (B) The nucleotides are covalently linked together into polynucleotide chains, with a sugar–phosphate backbone from which extend the bases: adenine, cytosine, guanine, and thymine (A, C, G, and T). (C) A DNA molecule is composed of two polynucleotide chains (DNA strands) held together by hydrogen bonds between the paired bases. The arrows on the DNA strands indicate the polarities of the two strands, which run antiparallel to each other (with opposite chemical polarities) in the DNA molecule. (D) Although the DNA is shown straightened out in (C), in reality, it is wound into a double helix, as shown here.
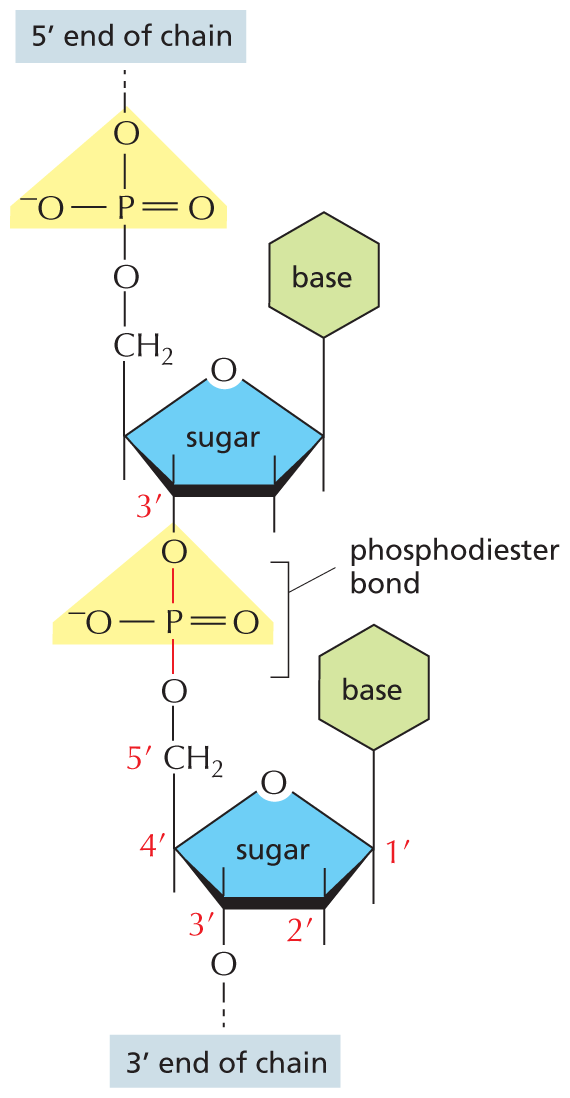
An illustration shows the phosphodiester bond in a D N A strand. In the two nucleotide units, a furanose sugar ring is the central group and the first ring from the top has the following substituents: C 1 prime is bonded to a base ring at the top, C 2 prime is bonded to a group at the top and the bottom, C 3 prime is bonded to an oxygen atom at the bottom that is further bonded to a phosphorus atom by a phosphodiester bond, and C 4 prime is bonded to a methylene group at the top that is further bonded to a phosphate group, which is the 5 prime end of the chain. The phosphorus atom is double bonded to an oxygen atom on the right, single bonded to an oxygen atom at the bottom that links the first and second ring, and single bonded to an oxygen anion on the left. The second ring at the bottom has a similar structure to that of the first ring. C 3 of the ring is bonded to an oxygen atom that is the 3 prime end of the chain.
Figure 5–3 The nucleotide subunits within a DNA strand are held together by phosphodiester bonds. These bonds connect one sugar to the next. The chemical differences in the ester linkages—between the 5′ carbon of one sugar and the 3′ carbon of the other—give rise to the polarity of the resulting DNA strand. For simplicity, only two nucleotides are shown here.
As we saw in Chapter 2 (see Panel 2–7, pp. 82–83), nucleotides are composed of a nitrogen-containing base and a five-carbon sugar, to which a phosphate group is attached. For the nucleotides in DNA, the sugar is deoxyribose (hence the name deoxyribonucleic acid) and the base can be either adenine (A), cytosine (C), guanine (G), or thymine (T). The nucleotides are covalently linked together in a chain through the sugars and phosphates, which form a backbone of alternating sugar–phosphate–sugar–phosphate (see Figure 5–2B). Because only the base differs in each of the four types of subunits, each polynucleotide chain resembles a necklace: a sugar–phosphate backbone strung with four types of tiny beads (the four bases A, C, G, and T). These same symbols (A, C, G, and T) are also commonly used to denote the four different nucleotides—that is, the bases with their attached sugar and phosphate groups.
The nucleotide subunits within a DNA strand are held together by phosphodiester bonds that link the 5ʹ end (pronounced “5 prime end”) of one sugar with the 3ʹ end of the next (Figure 5–3). Because the ester linkages to the sugar molecules on either side of the bond are different, each DNA strand has a chemical polarity. If we imagine that each nucleotide has a phosphate “knob” and a hydroxyl “hole” (see Figure 5–2A), each strand, formed by interlocking knobs with holes, will have all of its subunits lined up in the same orientation. Moreover, the two ends of the strand can be easily distinguished, as one will have a hole (the 3ʹ hydroxyl) and the other a knob (the 5ʹ phosphate). This polarity in a DNA strand is indicated by referring to one end as the 3ʹ end and the other as the 5ʹ end (see Figure 5–3).
The two polynucleotide chains in the DNA double helix are held together by hydrogen-bonding between the bases on the different strands. All the bases are therefore on the inside of the helix, with the sugar–phosphate backbones on the outside (see Figure 5–2D). The bases do not pair at random, however; A always pairs with T, and G always pairs with C (Figure 5–4). In each case, a bulkier two-ring base (a purine; see Panel 2–7, pp. 82–83) is paired with a single-ring base (a pyrimidine). Each purine–pyrimidine pair is called a base pair, and this complementary base-pairing enables the base pairs to be packed in the energetically most favorable arrangement along the interior of the double helix. In this arrangement, each base pair has the same width, thus holding the sugar–phosphate backbones an equal distance apart along the DNA molecule.
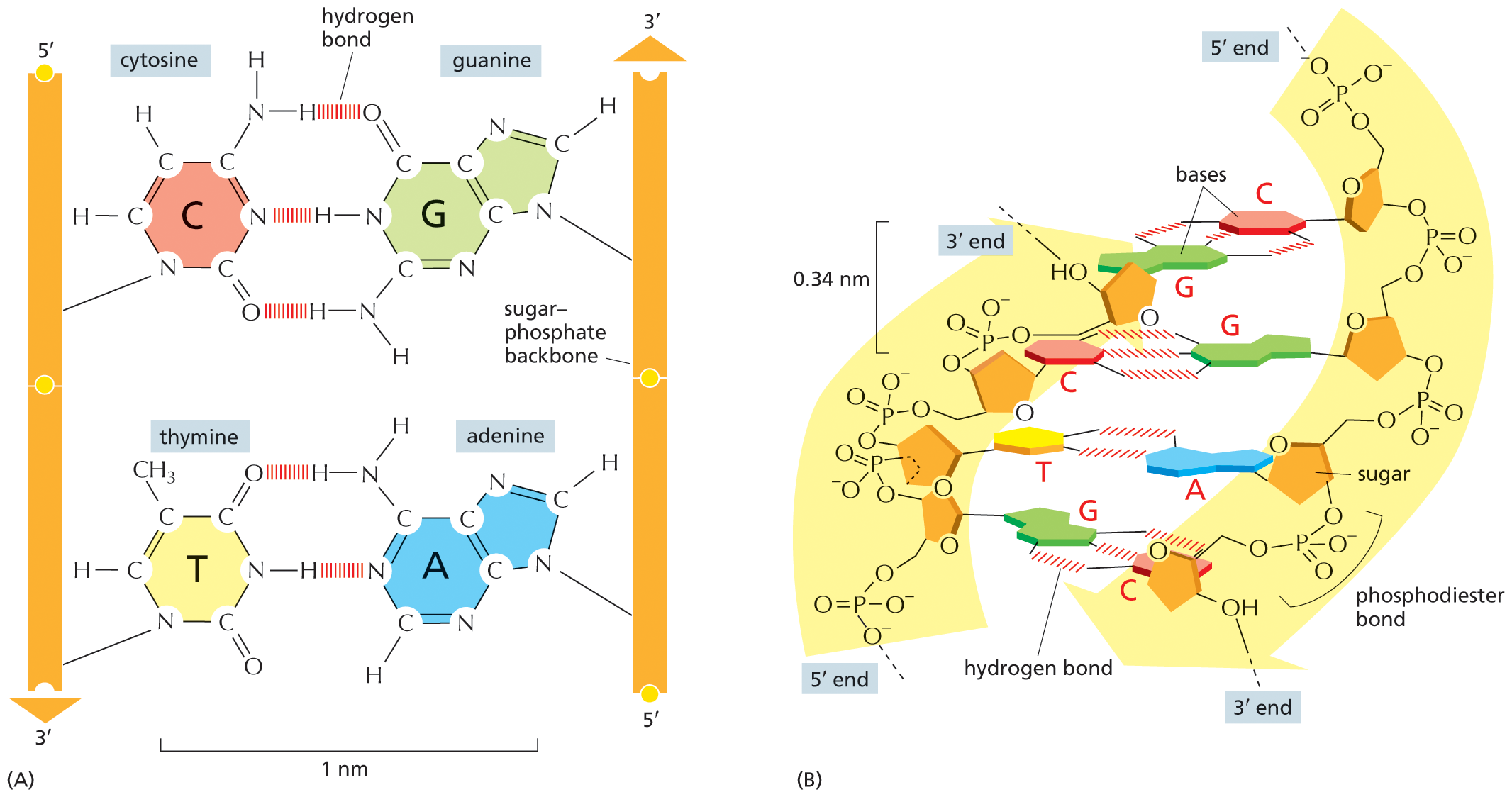
A two-part illustration shows hydrogen bonding in the D N A double helix. Section A: An illustration shows hydrogen bonding in the D N A double helix. Two parallel sugar backbones are shown, in which the sugar backbone on the left runs from 5 prime to 3 prime in a downward direction and the sugar backbone on the right runs from 5 prime to 3 prime in an upward direction. The molecular structure of each part is shown. Hydrogen bonds form between the bases connecting cytosine to guanine and thymine to adenine. The distance between the two bases on the sugar-phosphate backbone is labeled, 1 nanometer.
Section B: The double helix curve of D N A is shown, which has two curved portions; the left curve runs from 3 prime end to 5 prime end and the right curve runs from 5 prime end to 3 prime end. The left curve has four sugar rings, which are connected by phosphodiester bonds, and the right curve has four sugar rings, which are connected by phosphate groups. The first sugar ring on the left curve has guanine base, which forms three hydrogen bonds with cytosine base bonded to the first sugar ring on the right curve. The second sugar ring on the left curve has cytosine base, which forms three hydrogen bonds with guanine base bonded to the second sugar ring on the right curve. The third sugar ring on the left curve has thymine base, which forms two hydrogen bonds with adenine base bonded to the third sugar ring on the right curve. The fourth sugar ring on the left curve has guanine base, which forms three hydrogen bonds with cytosine base bonded to the fourth sugar ring on the right curve. The distance between two adjacent sugar ri
Figure 5–4 The two strands of the DNA double helix are held together by hydrogen bonds between complementary base pairs. (A) Schematic illustration showing how the shapes and chemical structures of the bases allow hydrogen bonds to form efficiently only between A and T and between G and C. The atoms that form the hydrogen bonds between these nucleotides (see Panel 2–3, pp. 74–75) can be brought close together without perturbing the double helix. As shown, two hydrogen bonds form between A and T, whereas three form between G and C. The bases can pair in this way only if the two polynucleotide chains that contain them are antiparallel—that is, oriented in opposite directions. (B) A short section of the double helix viewed from its side. Four base pairs are illustrated; note that they lie perpendicular to the axis of the helix, unlike the schematic shown in (A). As shown in Figure 5–3, the nucleotides are linked together covalently by phosphodiester bonds that connect the 3′-hydroxyl (–OH) group of one sugar and the 5′ phosphate (–PO3) attached to the next (see Panel 2–7, pp. 82–83, to review how the carbon atoms in the sugar ring are numbered). This linkage gives each polynucleotide strand a chemical polarity; that is, its two ends are chemically distinct. The 3′ end carries an unlinked –OH group attached to the 3′ position on the sugar ring; the 5′ end carries a free phosphate group attached to the 5′ position on the sugar ring.
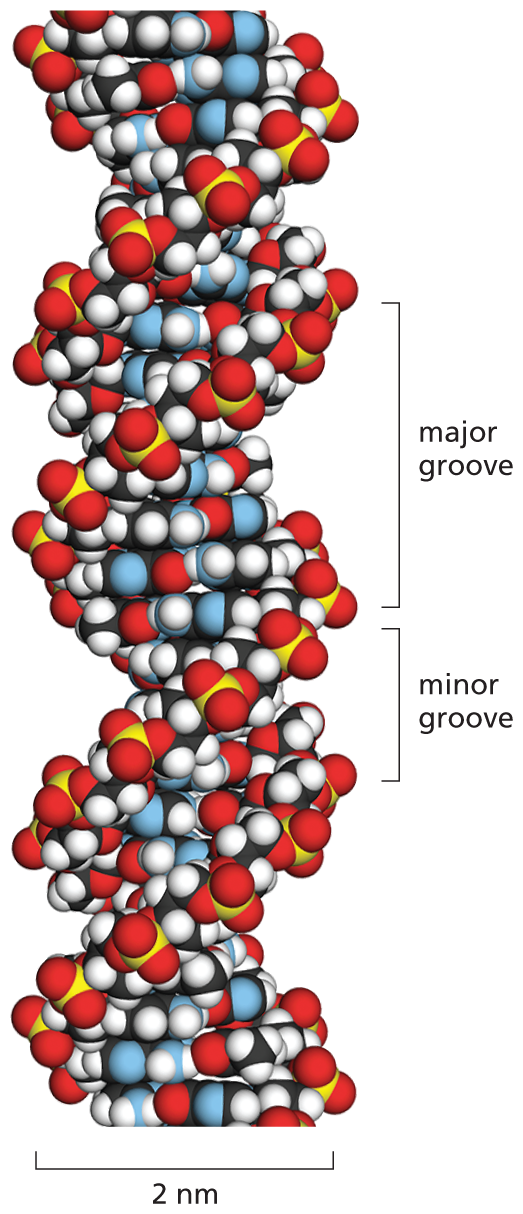
An illustration shows the space-filling model of a D N A double helix. In this model spheres portray the sugar backbone and the nucleotides that are twisted within themselves. The twist forms a helix with two groves; a major grove that measures about 2 nanometers and a minor grove that measures about 1 nanometers. The diameter of the helix measures approximately 2 nanometers.
Figure 5–5 A space-filling model shows the conformation of the DNA double helix. The two DNA strands wind around each other to form a right-handed helix (see Figure 4–14). Their coiling creates two grooves in the double helix. The wider groove is called the major groove and the smaller one the minor groove. Shown here are 1.5 turns of the DNA double helix, with 10 bases per turn (the spacing is easier to see in Figure 5–2D). Although the bases on the inside of the helix are hard to distinguish, their nitrogen atoms (blue) can be seen in the major and minor grooves; the colors of the remaining atoms are: O, red; P, yellow; H, white; and C, black. (See Movie 5.1.)
For the members of each base pair to fit together within the double helix, the two strands of the helix must run antiparallel to each other—that is, be oriented with opposite polarities (see Figure 5–2C and D). The antiparallel sugar–phosphate strands then twist around each other to form a double helix containing 10 base pairs per helical turn (Figure 5–5). The twisting takes place because it renders the conformation of DNA’s helical structure energetically favorable.
QUESTION 5–1
Which of the following statements are correct? Explain your answers.
As a consequence of the base-pairing arrangement shown in Figure 5–4, each strand of a DNA double helix contains a sequence of nucleotides that is exactly complementary to the nucleotide sequence of its partner strand—an A always matches a T on the opposite strand, and a C always matches a G. This complementarity is of crucial importance when it comes to both copying and maintaining the DNA structure, as we discuss in Chapter 6. An animated version of the DNA double helix can be seen in Movie 5.1.
The fact that genes encode information that must be copied and transmitted accurately when a cell divides raises two fundamental issues: how can the information for specifying an organism be carried in chemical form, and how can the information be accurately copied? The structure of DNA provides the answer to both questions.
Information is encoded in the order, or sequence, of the nucleotides along each DNA strand. Each base—A, C, T, or G—can be considered a letter in a four-letter alphabet that is used to spell out biological messages (Figure 5–6). Organisms differ from one another because their respective DNA molecules have different nucleotide sequences and, consequently, carry different biological messages. But how is the nucleotide alphabet used to make up messages, and what do they spell out?

Five illustrations depict different linear languages. The information presented in the different sections are as follows:
A. Text reads, molecular biology is…
B. A musical score with a series of notes.
C. A Morse code with a series of dots and dashes.
D. A Japanese script with a series of characters.
E. A nucleotide sequence of a D N A. It starts with T T C G A G C G and continues further.
Figure 5–6 Linear messages come in many forms. The languages shown are (A) English, (B) a musical score, (C) Morse code, (D) Japanese, and (E) DNA.
Before the structure of DNA was determined, investigators had established that genes contain the instructions for producing proteins. Thus, it was clear that DNA messages must somehow be able to encode proteins. Consideration of the chemical character of proteins makes the problem easier to define. As discussed in Chapter 4, the function of a protein is determined by its three-dimensional structure, which in turn is determined by the sequence of the amino acids in its polypeptide chain. The linear sequence of nucleotides in a gene, therefore, must somehow spell out the linear sequence of amino acids in a protein.
The exact correspondence between the 4-letter nucleotide alphabet of DNA and the 20-letter amino acid alphabet of proteins—the genetic code—is not at all obvious from the structure of the DNA molecule. It took more than a decade of clever experimentation after the discovery of the double helix to work this code out. In Chapter 7, we describe the genetic code in detail when we discuss gene expression—the process by which the nucleotide sequence of a gene is transcribed into the nucleotide sequence of an RNA molecule and then, in most cases, translated into the amino acid sequence of a protein (Figure 5–7).
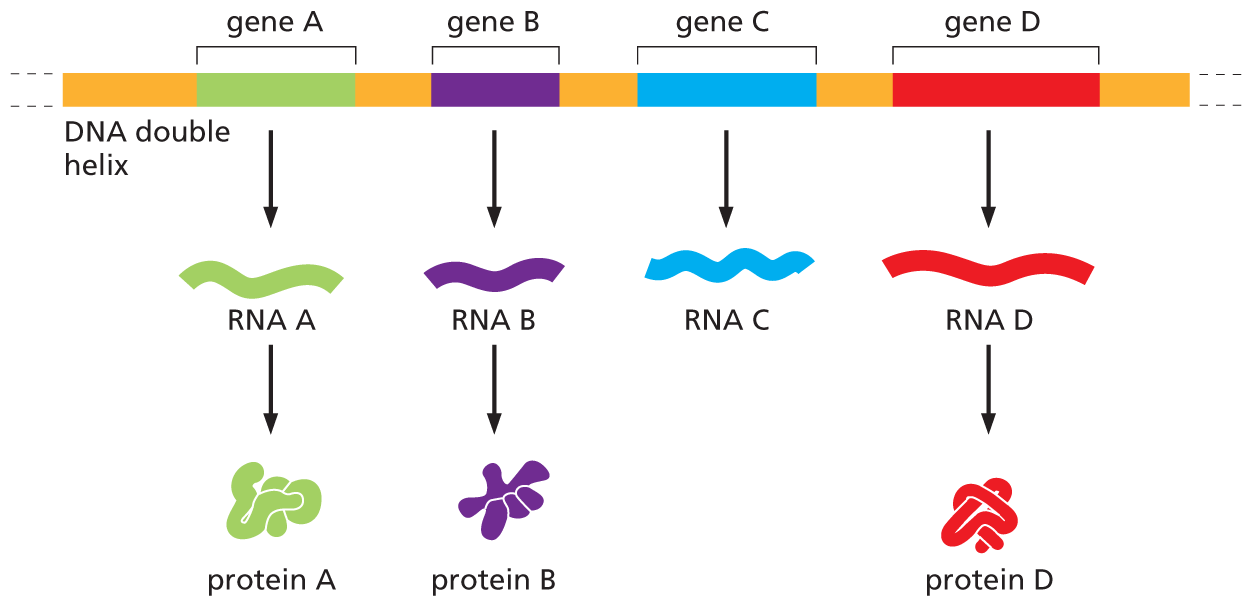
An illustration depicts the synthesis of R N A molecules and proteins from a D N A double helix. The illustration shows a D N A double helix. The strand has four genes labeled A through D positioned at regular intervals and separated by non coding regions. Gene A produces R N A A which synthesizes protein A. Gene B produces R N A B which synthesizes protein B. Gene C produces R N A C which does not lead to a protein. Gene D produces R N A D which synthesizes protein D.
Figure 5–7 Most genes contain information to make proteins. As we discuss in Chapter 7, protein-coding genes each produce a set of RNA molecules, which then direct the production of a specific protein molecule. Note that for a minority of genes, the final product is the RNA molecule itself, as shown here for gene C. In these cases, gene expression is complete once the nucleotide sequence of the DNA has been transcribed into the nucleotide sequence of its RNA.
The amount of information in an organism’s DNA is staggering: written out in the four-letter nucleotide alphabet, the nucleotide sequence of a very small protein-coding gene from humans occupies a quarter of a page of text, while the complete human DNA sequence would fill more than 1000 books the size of this one. Herein lies a problem that affects the architecture of all eukaryotic chromosomes: How can all this information be packed neatly into the cell nucleus? In the remainder of this chapter, we discuss the answer to this question.