❯❯
For more on the contrast between empiricism and intuition, experience, and authority, see Chapter 2, pp. 24–38.
Psychological scientists are identified not by advanced degrees or white lab coats but by what they do, what they value, and how they think. The rest of this chapter will explain the fundamental ways psychologists approach their work. First, they act as empiricists in their investigations. Second, they test theories through research and, in turn, revise their theories based on the resulting data. Third, they follow norms in the scientific community that prioritize objectivity and fairness. Fourth, they take an empirical approach to both applied research and basic research. Fifth, psychologists make their work public: They submit their results to journals for review and respond to the work of other scientists. Another aspect of making work public involves sharing findings of psychological research with the popular media, who may or may not get the story right.
❯❯
For more on the contrast between empiricism and intuition, experience, and authority, see Chapter 2, pp. 24–38.
Empiricists do not base conclusions on intuition, on casual observations of their own experience, or on what other people—even people with Ph.D.s—say. Empiricism, also referred to as the empirical method or empirical research, involves using evidence from the senses (sight, hearing, touch) or from instruments that assist the senses (such as thermometers, timers, photographs, weight scales, and questionnaires) as the basis for conclusions. Empiricists aim to be systematic and rigorous and to make their work independently verifiable by other observers. In Chapter 2, you will learn more about why empiricism is considered the most reliable basis for conclusions compared with other forms of reasoning, such as experience or intuition. For now, we’ll focus on some of the practices in which empiricists engage.
In the theory-data cycle, scientists collect data to test, change, or update their theories. Even if you haven’t yet conducted formal research, you have probably tested ideas and hunches of your own by asking specific questions that are grounded in theory, making predictions, and reflecting on data.
For example, say you go to check the weather app on your phone but it opens to a blank screen (Figure 1.3). What could be wrong? Maybe it’s only that one app that isn’t working. Does something else, such as Instagram, work? If not, you might ask your roommates, sitting nearby, “Are you having wifi problems?” If their wifi is working fine, you might try resetting your own wireless connection.
Notice the series of steps you took. First, you asked a particular set of questions (Is it only one app? Is it our apartment’s wifi?) that reflected your theory that the weather app requires a wireless connection. Because you were operating under this theory, you chose not to ask other kinds of questions (Has a warlock cursed my phone? Does my device have a bacterial infection?). Your theory set you up to ask certain questions and not others. Next, you made specific predictions, which you tested by collecting data. You tested your first idea (It’s only the weather app) by making a specific prediction (If I test another app, it will work). You tested your prediction (Does Instagram work?). The data (It doesn’t work) told you your initial prediction was wrong. You used that outcome to change your idea about the problem (It’s the wireless). And so on. Your process was similar to what scientists do in the theory-data cycle.

Figure 1.3
Troubleshooting a phone.
Troubleshooting an electronic device is a form of engaging in the theory-data cycle.
A classic example from the psychological study of attachment can illustrate the way researchers use data to test their theories. You’ve probably observed that animals form strong attachments—emotional bonds—to their caregivers. If you have a dog, you know it’s extremely happy to see you when you come home, wagging its tail and jumping all over you. Human babies, once they are able to crawl, may follow their parents or caregivers around, keeping close to them. Baby monkeys exhibit similar behavior, spending hours clinging tightly to the mother’s fur. Why do animals form such strong attachments?
One theory, referred to as the cupboard theory of mother-infant attachment, is that a mother is valuable to a baby mammal because she is a source of food. The baby animal gets hungry, gets food from the mother by nursing, and experiences a pleasant feeling (reduced hunger). Over time, the sight of the mother acquires positive value because she is the “cupboard” from which food comes. If you’ve ever assumed your dog loves you only because you feed it, your beliefs are consistent with the cupboard theory.
An alternative theory, proposed by psychologist Harry Harlow (1958), is that babies are attached to their mothers because of the comfort of their warm, fuzzy fur. This is the contact comfort theory. (In addition, it provides a less cynical view of why your dog is happy to see you!) Which theory is right?
In the natural world, a mother provides both food and contact comfort at once, so when the baby clings to her, it is impossible to tell why. To test the alternative theories, Harlow had to separate the two influences—food and contact comfort. The only way he could do so was to create “mothers” of his own. He built two monkey foster “mothers”—the only mothers his lab-reared baby monkeys ever had. One of the mothers was made of bare wire mesh with a bottle of milk built in. This wire mother offered food, but not comfort. The other was covered with fuzzy terrycloth and was warmed by a lightbulb suspended inside, but she had no milk. This cloth mother offered comfort, but not food.

Figure 1.4
The contact comfort theory.
As the theory led Harlow to hypothesize, the baby monkeys spent most of their time on the warm, cozy cloth mother, even though she did not provide any food.
This experiment sets up three possible outcomes. The contact comfort theory would be supported if the babies spent most of their time clinging to the cloth mother. The cupboard theory would be supported if the babies spent most of their time clinging to the wire mother. Neither theory would be supported if monkeys divided their time equally between the two mothers. In setting up this experiment, Harlow purposely created a situation that might prove his theory wrong.
When Harlow put the baby monkeys in cages with the two mothers, the evidence in favor of the contact comfort theory was overwhelming. Harlow’s data showed that the little monkeys would cling to the cloth mother for 12–18 hours a day (Figure 1.4). When they were hungry, they would climb down, nurse from the wire mother, and then go right back to the warm, cozy cloth mother. In short, Harlow used the two theories to make specific predictions about how the monkeys would interact with each mother. The data he recorded (how much time the monkeys spent on each mother) supported only one of the theories. The theory-data cycle in action!
A theory is a set of statements—as simple as possible—that describes general principles about how variables relate to one another. For example, Harlow’s theory was that contact comfort, not food, was the primary basis for a baby’s attachment to its mother. This theory led Harlow to investigate particular kinds of questions—he chose to pit contact comfort against food in his research. The theory meant that Harlow also chose not to study unrelated questions, such as the babies’ food preferences or sleeping habits.
The theory not only led to the questions but also to specific hypotheses about the answers. A hypothesis, or prediction, is stated in terms of the study design. It’s the specific outcome the researcher will observe in a study if the theory is accurate. Harlow’s hypothesis stated that the babies would spend more time on the cozy mother than on the wire mother. Notably, one theory can lead to a large number of hypotheses because a single study is not sufficient to test the entire theory—it is intended to test only part of it. Most researchers test theories with a series of empirical studies, each designed to test an individual hypothesis.
Data are a set of observations. (Harlow’s data were the amount of time the baby monkeys stayed on each mother.) Depending on whether the data are consistent with hypotheses based on a theory, the data may either support or challenge the theory. Data that match the theory’s hypotheses strengthen the researcher’s confidence in the theory. When the data do not match the theory’s hypotheses, however, those results indicate that the theory needs to be revised or the research design needs to be improved.
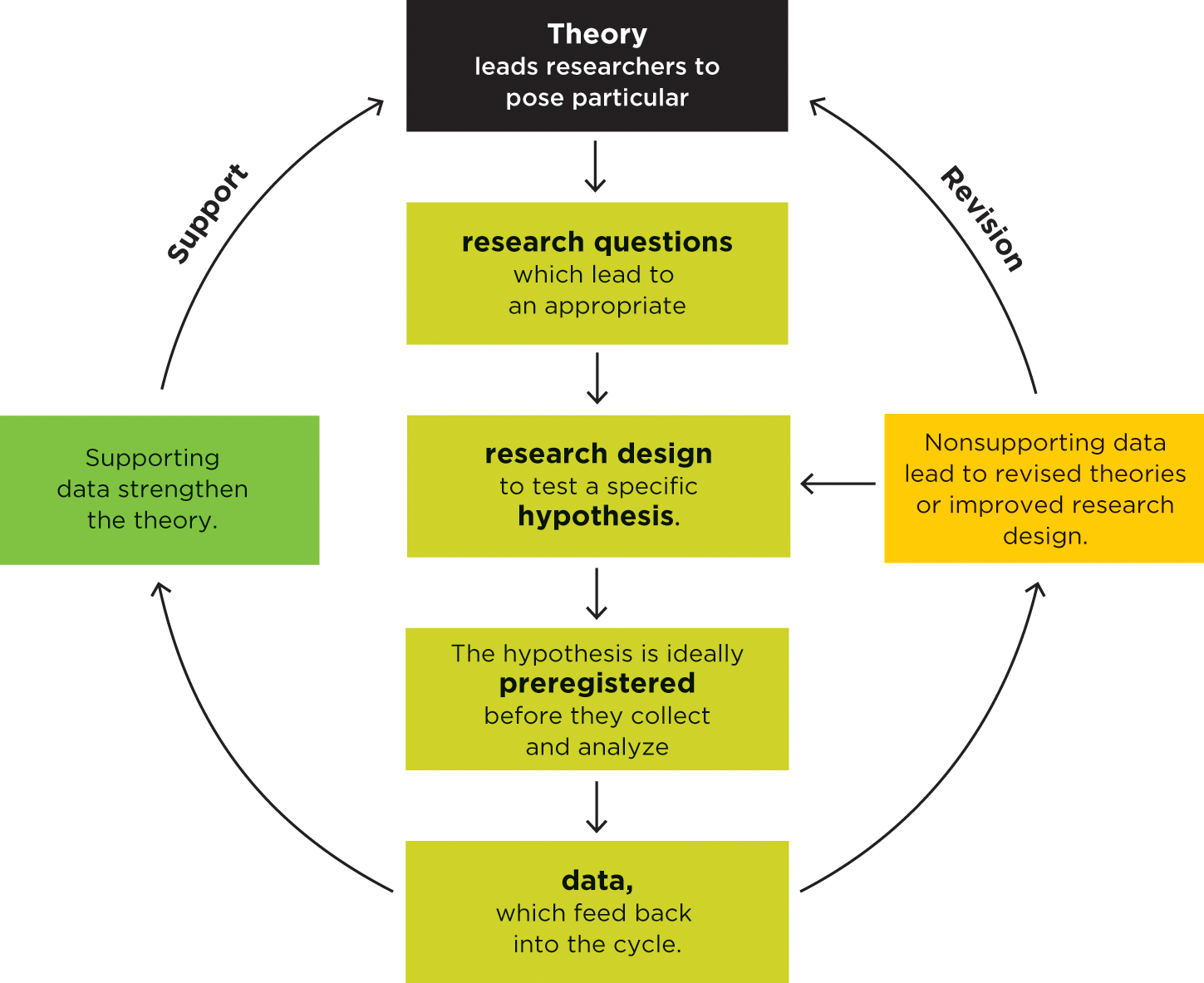
Figure 1.5
The theory-data cycle.
Ideally, hypotheses are preregistered. That is, after the study is designed but before collecting any data, the researcher states publicly what the study’s outcome is expected to be (perhaps using a time-stamped Internet tool). It’s unconvincing if a researcher collects the data first and then claims, “I knew that would happen all along.” Instead, the theory-data cycle is like a gamble: Researchers place a public bet in advance that the study will come out in favor of the theory. They are willing to risk being wrong every time they collect data. Figure 1.5 shows how these steps work as a cycle.
The word prove is not used in science. Researchers never say they have proved their theories. Why not? As empiricists, scientists avoid inferences they cannot support with direct observation. Consider this set of observations:
Are we therefore justified in concluding that All ravens are black?
Not if we are empiricists. We have not observed all possible ravens, so it is possible that a nonblack raven exists. If scientists take their role as empiricists seriously, they are not justified in making generalizations about phenomena they have not observed (Hume, 1888). The possible existence of one unobserved nonblack raven prevents us from saying we’ve proved that all ravens are black.

Figure 1.6
Scientists don’t say “prove.”
When you see the word prove in a headline, be skeptical. No single study can prove a theory once and for all. A more scientifically accurate headline would be: “Study Supports the Hypothesis That Hiking Improves Mental Health.” (Source: Netburn, LATimes.com, 2015.)
Similarly, when a psychologist such as Harlow completes a single study supporting a theory, we do not say the study proves the theory. Instead of saying “prove,” scientists say that a study’s data support or are consistent with a theory. A single confirming finding cannot prove a theory (Figure 1.6). Similarly, a single disconfirming finding does not lead researchers to scrap a theory. If a hypothesis is not supported, they might say that data are inconsistent with a theory. Scientists may troubleshoot the study instead of rejecting the theory. In practice, scientists require a diverse and convincing set of observations before they completely abandon a viable theory (Kuhn, 1962).
❯❯
For more on replication, see Chapter 14, pp. 437–444.
Science progresses over the long run, via a series of inferences based on observations of data. Scientists conduct multiple investigations, replicating the original study. A replication means the study is conducted again to test whether the result is consistent. Scientists therefore evaluate their theories based on the weight of the evidence—the collection of studies, including replications, of the same theory . Therefore, Harlow’s theory of attachment was not “proved” by one single study involving wire and cloth mothers. However, his theory was strongly supported by dozens of individual studies that ruled out alternative explanations and tested the theory’s limits.

Figure 1.7
An example of a theory that is not falsifiable.
Certain people might wear a tinfoil hat, operating under the idea that the hat wards off government mental surveillance. But like most conspiracy theories, this notion of remote government mindreading is not falsifiable. If the government has been shown to read people’s minds, the theory is supported. But if there is no physical evidence, that also supports the theory because if the government does engage in such surveillance, it wouldn’t leave a detectable trace of its secret operations.
Strong scientific theories set up gambles. A theory should lead to hypotheses that, when tested, could fail to support the theory—in other words, falsifiability is a characteristic of good theories (Popper, 1963). Harlow gambled with his study: If the monkeys had spent more time on the wire mother than the cloth mother, the study would not have supported the contact comfort theory. Similarly, Mrazek’s mindfulness study could have falsified the researchers’ theory: If students in the mindfulness training group had shown lower GRE scores than those in the nutrition group, the theory of mindfulness and attention would not have been supported.
In contrast, some pseudoscientific techniques have been based on theories that are not falsifiable. Here’s an example. Some therapists practice facilitated communication (FC), believing they can help people with developmental disorders communicate by gently guiding their clients’ hands over a special keyboard. In simple but rigorous empirical tests, the facilitated messages have been shown to come from the therapist, not the client (Twachtman-Cullen, 1997). All such studies have falsified the theory behind FC. However, FC’s supporters don’t accept these results. The skepticism inherent in the empirical method, FC supporters say, breaks down trust between the therapist and client and shows a lack of faith in people with disabilities. Therefore, these supporters hold a belief about FC that is not falsifiable. According to its supporters, we can never test the efficacy of FC because it only works as long as it’s not scrutinized. To be truly scientific, researchers must take risks, including being prepared to accept data that do not support their theory. Practitioners must be open to such risk as well so they can use techniques that actually work. For another example of an unfalsifiable claim, see Figure 1.7.
Scientists are members of a community, and as such, they follow a set of norms—shared expectations about how they should act. Sociologist Robert Merton (1942) identified four norms that scientists attempt to follow, summarized in Table 1.1. Following the theory-data cycle and the norms and practices of the scientific community means science can progress. By being open to falsification and skeptically testing every assumption, science can become self-correcting; that is, it discovers its own mistaken theories and corrects them.
Merton’s Scientific Norms
|
Name |
Definition |
Interpretation and application |
|
Scientific claims are evaluated according to their merit, independent of the researcher’s credentials or reputation. The same preestablished criteria apply to all scientists and all research. |
Even a student can do science—you don’t need an advanced degree or research position. |
|
|
Scientific knowledge is created by a community and its findings belong to the community. |
Scientists should transparently and freely share the results of their work with other scientists and the public. |
|
|
Scientists strive to discover the truth, whatever it is; they are not swayed by conviction, idealism, politics, or profit. |
Scientists should not be personally invested in whether their hypotheses are supported by the data. Scientists do not spin the story; instead, they accept what the data tell them. In addition, a scientist’s own beliefs, income, or prestige should not bias their interpretation or reporting of results. |
|
|
Scientists question everything, including their own theories, widely accepted ideas, and “ancient wisdom.” |
Scientists accept almost nothing at face value. Nothing is sacred—they always ask to see the evidence. |
The empirical method can be used for both applied and basic research questions. Applied research is done with a practical problem in mind and the researchers conduct their work in a local, real-world context. An applied research study might ask, for example, if a school district’s new method of teaching language arts is working better than the former one. It might test the efficacy of a treatment for depression in a sample of trauma survivors. Applied researchers might be looking for better ways to identify those who are likely to do well at a particular job, and so on.
The goal of basic research, in contrast, is to enhance the general body of knowledge rather than to address a specific, practical problem. Basic researchers might want to understand the structure of the visual system, the capacity of human memory, the motivations of a depressed person, or the limitations of the infant attachment system. However, the knowledge basic researchers generate may be applied to real-world issues later on.
Translational research is the use of lessons from basic research to develop and test applications to health care, psychotherapy, or other forms of treatment and intervention. Translational research represents a dynamic bridge from basic to applied research. For example, basic research on the biochemistry of cell membranes might be translated into a new drug for schizophrenia. Or basic research on how mindfulness changes people’s patterns of attention might be translated into a study skills intervention. Figure 1.8 shows the interrelationship of the three types of research.

Figure 1.8
Basic, applied, and translational research.
Basic researchers may not have an applied context in mind, and applied researchers may be less familiar with basic theories and principles. Translational researchers attempt to translate the findings of basic research into applied areas.
When scientists want to tell the scientific world about the results of their research, they write a paper and submit it to a scientific journal. In so doing, they practice the communality norm . Scientific journals usually come out every month and contain articles written by various researchers. Unlike popular newsstand magazines, the articles in a scientific journal are peer-reviewed. The journal editor sends the paper to three or four experts on the subject. The experts tell the editor about the work’s virtues and flaws and the editor, considering these reviews, decides whether the paper deserves to be published in the journal.
The peer-review process in the field of psychology is intended to be rigorous. Peer reviewers are kept anonymous, so even if they know the author of the article professionally or personally, they can feel free to give an honest assessment of the research. They comment on how important the work is, how it fits with the existing body of knowledge, how competently the research was done, and how convincing the results are. Ultimately, peer reviewers are supposed to ensure that the articles published in scientific journals contain important, well-done studies. When the peer-review process works, research with major flaws does not get published. (Some journals reject more than 90% of submissions after peer review.) The process continues even after a study is published. Other scientists can cite an article and do further work on the same subject. Moreover, scientists who find flaws in the research (perhaps overlooked by the peer reviewers) can publish letters, commentaries, or competing studies. Publication thus helps make science self-correcting.
One goal of this textbook is to teach you how to interrogate information about psychological science that you find not only in scientific journals but also in more mainstream sources. Psychology’s scientific journals are read primarily by other scientists and by psychology students, but rarely by the general public. Journalism, in contrast, is a secondhand report about the research, written by journalists or laypeople. A journalist might become interested in a psychology study through a press release written by the scientist’s university or by hearing scientists talk about their work at a conference. The journalist turns the research into a news story by summarizing it for a popular audience, giving it an interesting headline and using nontechnical terms.
Science journalism fulfills the communality norm of science by allowing scientists to share potentially valuable work with the general public. Science journalism is easy to access, and understanding it does not require specialized education. However, in their effort to tell an engaging, clickable story, journalists might overstate the research or get the details wrong (Figure 1.9).

Figure 1.9
Getting it right.
Cartoonist Jorge Cham parodies what can happen when journalists report on scientific research. Here, an original study reported a relationship between two variables. Although the University Public Relations Office relates the story accurately, the strength of the relationship and its implications become distorted with subsequent retellings, much like a game of “telephone.”
Media coverage of a phenomenon called the “Mozart effect” provides an example of how journalists might misrepresent science when they write for a popular audience (Spiegel, 2010). In 1993, researcher Frances Rauscher found that when students heard Mozart music played for 10 minutes, they performed better on a subsequent spatial intelligence test when compared with students who had listened to silence or to a monotone speaking voice (Rauscher et al., 1993). Rauscher said in a radio interview, “What we found was that the students who had listened to the Mozart sonata scored significantly higher on the spatial temporal task.” However, Rauscher added, “It’s very important to note that we did not find effects for general intelligence . . . just for this one aspect of intelligence. It’s a small gain and it doesn’t last very long” (Spiegel, 2010). But despite the careful way the scientists described their results, the media that reported on the story exaggerated its importance:
The headlines in the papers were less subtle than her findings: “Mozart makes you smart” was the general idea. . . . But worse, says Rauscher, was that her very modest finding started to be wildly distorted. “Generalizing these results to children is one of the first things that went wrong. Somehow or another the myth started exploding that children that listen to classical music from a young age will do better on the SAT, they’ll score better on intelligence tests in general, and so forth.” (Spiegel, 2010)

Figure 1.10
The Mozart effect.
Journalists sometimes misrepresent research findings. Exaggerated reports of the Mozart effect even inspired a line of consumer products for children.
Perhaps because the media distorted the effects of that first study, a small industry sprang up, recording child-friendly sonatas for parents and teachers (Figure 1.10). However, according to research conducted since the first study was published, the effect of listening to Mozart on people’s intelligence test scores is not very strong, and it applies to most music, not just Mozart (Pietschnig et al., 2010).
How can you prevent being misled by a journalist’s coverage of science? One way is to find the original source, which you’ll learn to do in Chapter 2. Reading the original scientific journal article is the best way to get the full story. Another approach is to maintain a skeptical mindset when it comes to popular sources. Chapter 3 explains how to ask the right questions before you allow yourself to accept a writer’s claim.

1. See the discussion of Harlow’s monkey experiment on pp. 12-13. 2. See p. 15. 3. See p. 16. 4. See p. 17. 5. See pp. 17-19. 6. By overstating results of studies or by getting the details wrong.