There are two basic types of within-groups designs. When researchers expose participants to all levels of the independent variable, they might do so by repeated exposures to different levels over time, or they might do so concurrently.
Repeated-Measures Design
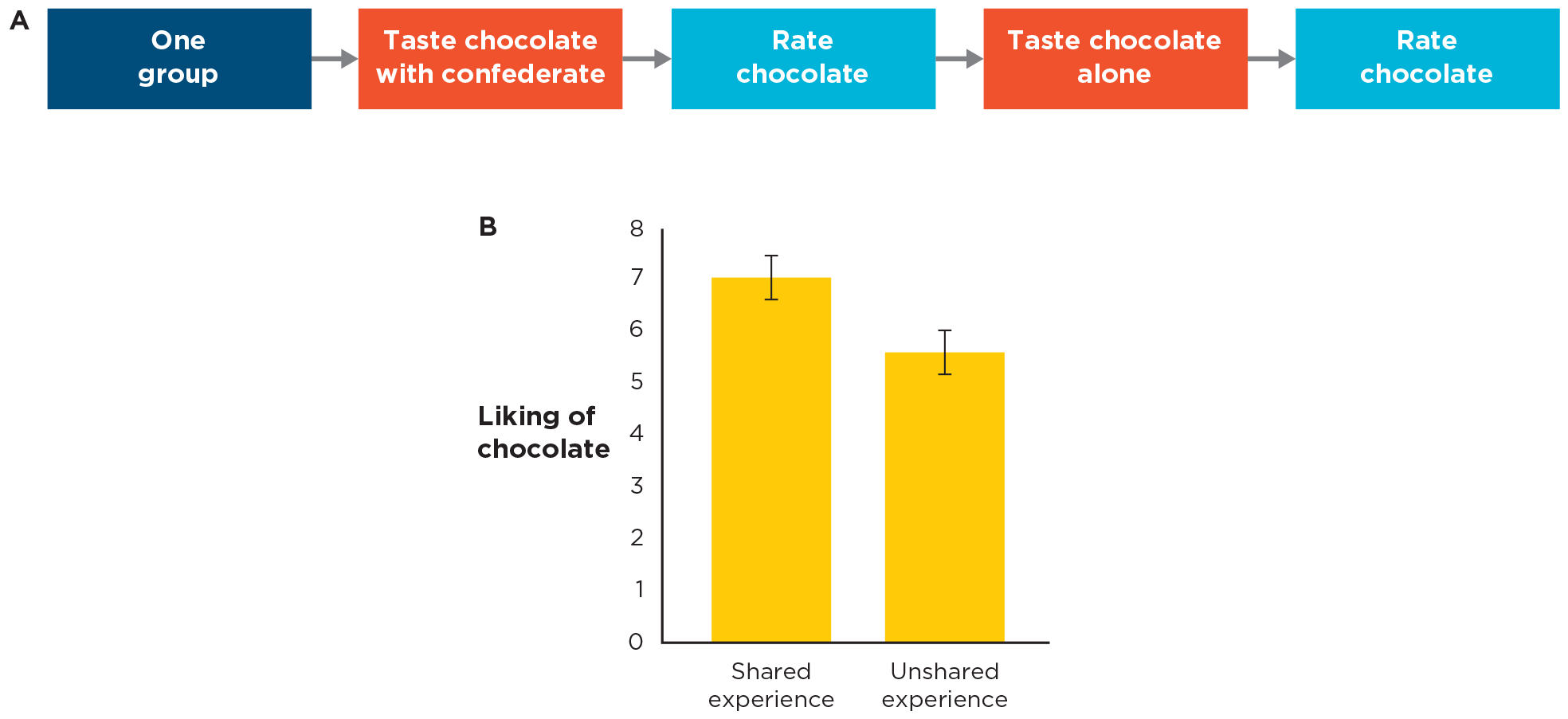
A repeated-measures design is a type of within-groups design in which participants are measured on a dependent variable more than once, after exposure to each level of the independent variable. Here’s an example. Humans are social animals, and we know that many of our thoughts and behaviors are influenced by the presence of other people. Happy times may be happier, and sad times sadder, when experienced with others. Researchers Erica Boothby and her colleagues used a repeated-measures design to investigate whether a shared experience would be intensified even when people do not interact with the other person (Boothby et al., 2014). They hypothesized that sharing a good experience with another person makes it even better than it would have been if experienced alone and that sharing a bad experience would make it even worse.
They recruited 23 college women to come to a laboratory. Each participant was joined by a female confederate (a research assistant pretending to be a participant). The two sat side-by-side, facing forward, and never spoke to each other. The experimenter explained that each person in the pair would do a variety of activities, including tasting some dark chocolates and viewing some paintings. During the experiment, the order of activities was determined by drawing cards, but the drawings were rigged so that the real participant’s first two activities were always tasting chocolates. In addition, the real participant tasted one chocolate at the same time the confederate was also tasting it, but she tasted the other chocolate while the confederate was viewing a painting. The participant was told that the two chocolates were different, but in fact they were exactly the same. After tasting each chocolate, participants rated how much they liked it. The results showed that participants liked the chocolate more when the confederate was also tasting it (Figure 10.14).
FIGURE 10.14
Testing the effect of sharing an experience using a repeated-measures design.
(A) The design of the study. (B) The results of the study. Error bars represent 95% CIs. (Source: Adapted from Boothby et al., 2014.)
In this study, the independent variable had two levels: sharing and not sharing an experience. Participants experienced both levels, making it a within-groups design. The dependent variable was participants’ rating of the chocolate. It was a repeated-measures design because each participant rated the chocolate twice (i.e., repeatedly).
Concurrent-Measures Design
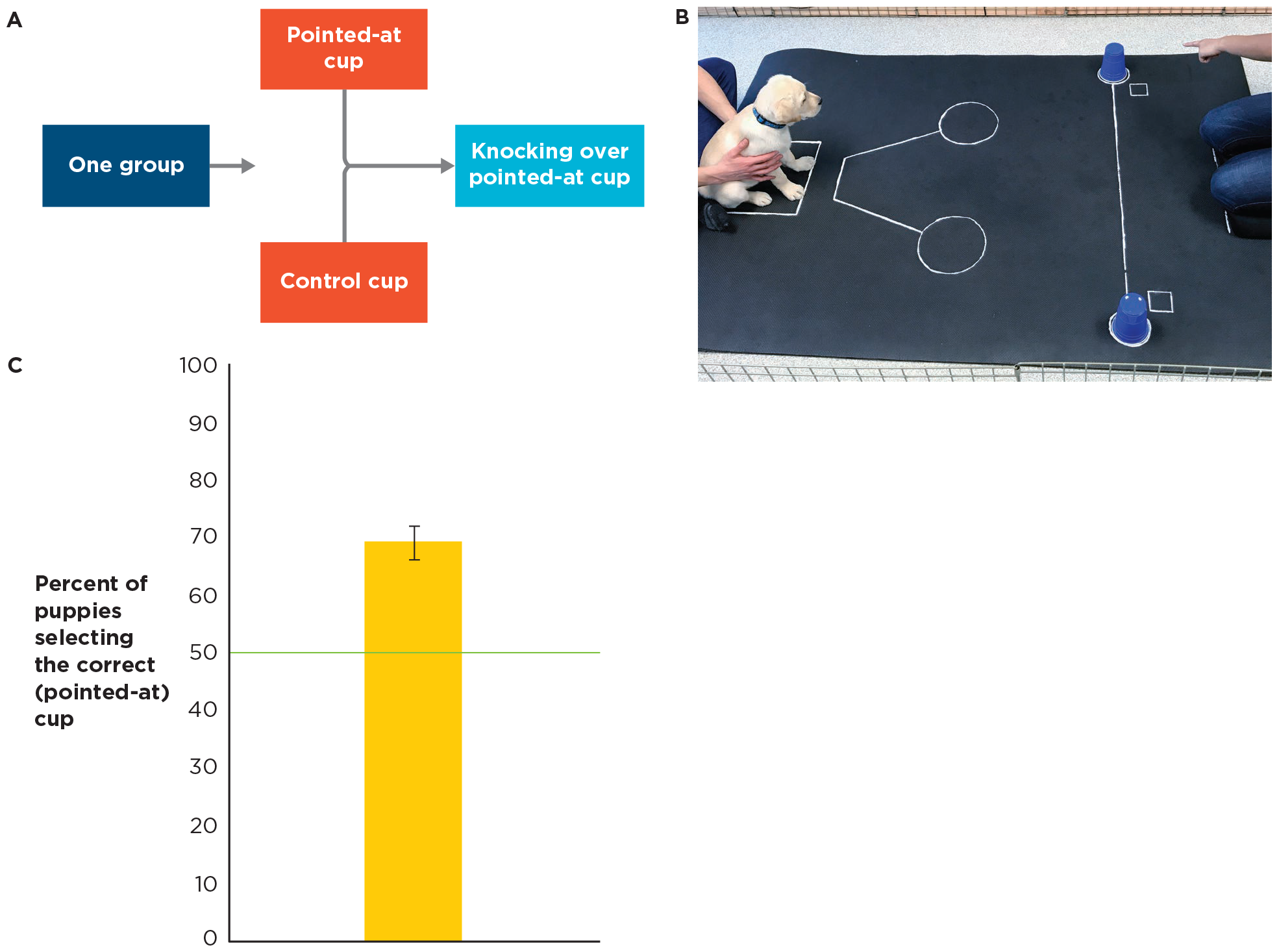
In a concurrent-measures design, participants are exposed to all the levels of an independent variable at roughly the same time, and a single attitudinal or behavioral preference is the dependent variable. An example is a study investigating whether 8- to 10-week-old puppies could follow humans’ communication cues. Researchers hid a treat under one of two inverted cups and then pointed to the cup with the treat in it. They recorded whether the puppies knocked over the correct cup (Bray et al., 2020; Figure 10.15). The independent variable was whether a cup was being pointed at, and puppies were exposed to both levels (point and no-point) at the same time. The puppy’s choice of cup was the dependent variable. This study found that the puppies picked the cup that was pointed at 69.4% of the time. This means the puppies were able to use human communication cues to locate treats.
More information
A three-part image about a concurrent-measures design for a puppy cognition study.
FIGURE 10.15
A concurrent-measures design for a puppy cognition study.
(A) The design of the study. (B) A puppy in the study going to the “correct” (pointed-at) cup with the treat hidden under it. (C) The results of the study. The study showed that puppies used the researcher’s pointing cue to find the treat most (69%) of the time.
Harlow also used a concurrent-measures design when he presented baby monkeys with both a wire and a cloth “mother” (Harlow, 1958). The monkeys indicated their preference by spending more time with one mother than the other. In Harlow’s study, the type of mother was the independent variable (manipulated as within-groups), and each baby monkey’s clinging behavior was the dependent variable. Concurrent-measures designs are also used in taste tests, where people taste (for example) two colas and indicate which one they prefer.
Advantages of Within-Groups Designs
The main advantage of a within-groups design is that it ensures the participants in the two groups will be equivalent. After all, they are the same participants! For example, some people really like dark chocolate and others do not. But in a repeated-measures design, people bring their same liking of chocolate to both conditions, so their individual liking for the chocolate stays the same. The only difference between the two conditions can then be attributed to the independent variable (whether people were sharing the experience with the confederate or not). In a within-groups design such as the chocolate study, researchers say that each woman “acted as her own control” because individual or personal variables are kept constant.
The idea of “treating each participant as their own control” also means matched-groups designs can be treated as within-groups designs. As discussed earlier, in a matched-groups design, researchers carefully match pairs of participants on some key control variable (such as hometown size) and assign each member of a set to a different group. The matched participants in the groups are assumed to be more similar to each other than in a more traditional independent-groups design, which uses random assignment.
Besides providing the ability to use each participant as their own control, within-groups designs also enable researchers to make more precise estimates of the differences between conditions. Statistically speaking, when extraneous differences (unsystematic variability) in personality, food preferences, genetic background, ability, and so on are held constant across all conditions, researchers can estimate the effect of the independent variable manipulation more precisely—there is less extraneous error in the measurement. Having extraneous differences between conditions in a study is like being at a noisy party: Your ability to understand somebody’s exact words is hampered when many other conversations are going on around you.
A within-groups design can also be attractive because it generally requires fewer participants overall. Suppose a team of researchers is running a study with two conditions. If they want 50 participants in each condition, they will need a total of 100 people for an independent-groups design. However, if they run the same study as a within-groups design, they will need only 50 participants because each participant experiences all levels of the independent variable (Figure 10.16). In this way, a repeated-measures design can be much more efficient.
FIGURE 10.16
Within-groups designs require fewer participants.
If researchers want a certain number of participants in each of two experimental conditions, a within-groups design is more efficient than an independent-groups design. Although only 40 participants are shown here (for reasons of space), psychologists usually need to use larger samples than this in their studies.
Covariance, Temporal Precedence, and Internal Validity in Within-Groups Designs
Do within-groups designs allow researchers to make causal claims? In other words, do they stand up to the three criteria for causation?
Because within-groups designs enable researchers to manipulate an independent variable and incorporate comparison conditions, they provide an opportunity for establishing covariance. The Boothby team’s (2014) results showed, for example, that the chocolate ratings covaried with whether people shared the tasting experience or not.
A repeated-measures design also establishes temporal precedence. The experimenter controls the independent variable and can ensure that it comes first. In the chocolate study, each person tasted chocolate as either a shared or an unshared experience and then rated the chocolate. In the puppy study, the researchers pointed to a cup first and then measured puppies’ choices.
What about internal validity? For a within-groups design, researchers don’t have to worry about selection effects because participants are exactly the same in the two conditions. They do need to avoid design confounds, however. For example, Boothby’s team made sure both chocolates were exactly the same. If the chocolate that people tasted in the shared condition was of better quality, the experimenters would not know if it was the chocolate quality or the shared experience that was responsible for higher ratings. Similarly, Bray’s team made sure both cups smelled the same (by affixing a treat to the bottom of each upturned cup). This ensured that puppies were using pointing cues, not smell, to make their choices.
INTERNAL VALIDITY: CONTROLLING FOR ORDER EFFECTS
Within-groups designs have the potential for a particular threat to internal validity: Sometimes, being exposed to one condition first changes how participants react to the later condition. Such responses are called order effects, and they happen when exposure to one level of the independent variable influences responses to the next level. An order effect in a within-groups design is a confound, meaning that behavior at later levels of the independent variable might be caused not by the experimental manipulation but rather by the sequence in which the conditions were experienced.
Some specific order effects are due to repeated testing, such as practice effects, in which a long sequence might lead participants to get better at the task, and fatigue effects, in which people get tired or bored toward the end. Order effects also include carryover effects, in which some form of contamination carries over from one condition to the next. For example, imagine sipping orange juice right after brushing your teeth; the first taste contaminates your experience of the second one.
An order effect in the chocolate-tasting study could have occurred if people rated the first chocolate higher than the second simply because the first bite of chocolate is always the best; subsequent bites are never quite as good. That would be an order effect and a threat to internal validity because the order of tasting chocolate is confounded with the condition (shared versus unshared experiences).
AVOIDING ORDER EFFECTS BY COUNTERBALANCING
Because order effects are potential internal validity problems in a within-groups design, experimenters take steps to avoid them. When researchers use counterbalancing, they present the levels of the independent variable to participants in different sequences. With counterbalancing, any order effects should cancel each other out when all the data are combined.
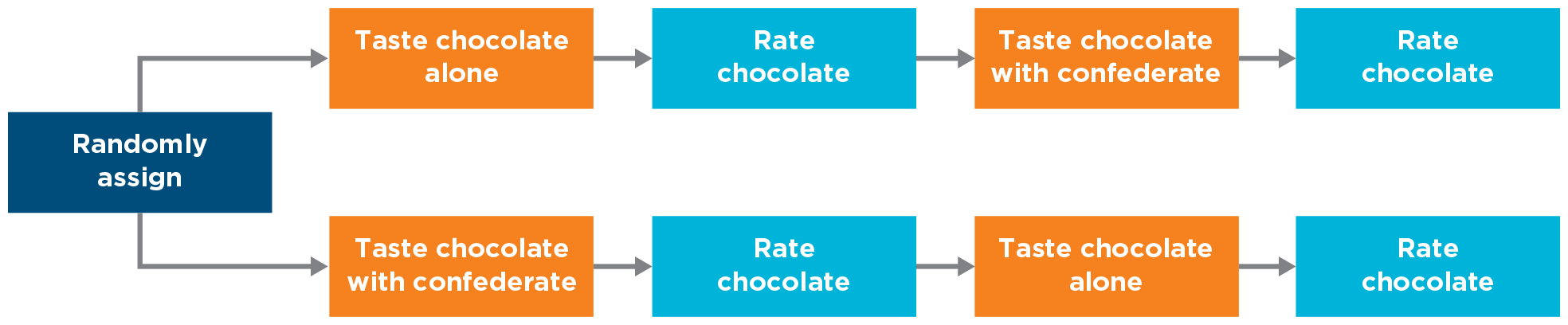
Boothby and her colleagues (2014) used counterbalancing in their experiment (Figure 10.17). Half the participants tasted their first chocolate in the shared condition and then had their second chocolate in the unshared condition. The other half tasted the first chocolate in the unshared condition and the second in the shared condition. Therefore, the potential order effect of “first taste of chocolate” was present for half of the people in each condition. When the data were combined from these two sequences, any order effect dropped out of the comparison between the shared and unshared conditions. As a result, the researchers knew that the difference they noticed was attributable only to the shared (versus unshared) experiences, and not to practice, fatigue, carryover, or some other order effect. Similarly, Bray et al. (2020) alternated which cup (right or left) was pointed to.
More information
A flowchart example of a counterbalanced design.
FIGURE 10.17
Counterbalanced design.
Using counterbalancing in an experiment will cancel out any order effects in a repeated-measures design.
Procedures Behind Counterbalancing.
When researchers counterbalance conditions (or levels) in a within-groups design, they split their participants into groups, and each group receives one of the condition sequences. How do the experimenters decide which participants receive the first order of presentation and which ones receive the second? Through random assignment, of course! They might recruit, say, 50 participants to a study and randomly assign 25 of them to receive the order A then B, and assign 25 of them to receive the order B then A.
There are two methods for counterbalancing an experiment: full and partial. When a within-groups experiment has only two or three levels of an independent variable, researchers can use full counterbalancing, in which all possible condition orders are represented. For example, a repeated-measures design with two conditions is easy to counterbalance because there are only two orders (A → B and B → A). In a repeated-measures design with three conditions—A, B, and C—each group of participants could be randomly assigned to one of the six following sequences:
A → B → C
B → C → A
A → C → B
C → A → B
B → A → C
C → B → A
As the number of conditions increases, however, the number of possible orders needed for full counterbalancing increases dramatically. For example, a study with four conditions requires 24 possible sequences. If experimenters want to put at least a few participants in each order, the need for participants can quickly increase, counteracting the typical efficiency of a repeated-measures design. Therefore, they might use partial counterbalancing, in which only some of the possible condition orders are represented. One way to partially counterbalance is to present the conditions in a randomized order for every subject. (This is easy to do when an experiment is administered by a computer; the computer delivers conditions in a new random order for each participant.)
Another technique for partial counterbalancing is to use a Latin square, a formal system to ensure that every condition appears in each position at least once. A Latin square for six conditions (conditions 1 through 6) looks like this:
1
2
6
3
5
4
2
3
1
4
6
5
3
4
2
5
1
6
4
5
3
6
2
1
5
6
4
1
3
2
6
1
5
2
4
3
The first row is set up according to a formula, and then the conditions simply go in numerical order down each column. Latin squares work differently for odd and even numbers of conditions. If you wish to create your own, you can find formulas for setting up the first rows of a Latin square online.
Disadvantages of Within-Groups Designs
Within-groups designs are true experiments because they involve a manipulated variable and a measured variable. They potentially establish covariance, they ensure temporal precedence, and when experimenters control for order effects and design confounds, they can establish internal validity, too. So why wouldn’t a researcher choose a within-groups design all the time?
Within-groups designs have three main disadvantages. First, as noted earlier, repeated-measures designs have the potential for order effects, which can threaten internal validity. But a researcher can usually control for order effects by using counterbalancing, so they may not be much of a concern.
A second possible disadvantage is that a within-groups design might not be possible or practical. Suppose someone has devised a new way of teaching children how to ride a bike, called Method A. They want to compare Method A with the older method, Method B. Obviously, they cannot teach a group of children to ride a bike with Method A and then return them to baseline and teach them again with Method B. Once taught, the children are permanently changed. In such a case, a within-groups design, with or without counterbalancing, would make no sense. The study on mindfulness training and GRE scores fits in this category. Once people had participated in mindfulness training, they presumably could apply their new skill indefinitely.
A third problem occurs when people see all levels of the independent variable and then change the way they would normally act. Imagine a study that asks people to rate the attractiveness of three photographed people—one Black, one Latine, and one White. Participants in such a study might think, “I know I’m participating in a study at the moment; seeing people of different ethnicities makes me wonder whether it has something to do with prejudice.” As a result, they might change their spontaneous behavior. A cue that can lead participants to guess an experiment’s hypothesis is known as a demand characteristic, or an experimental demand. Demand characteristics create an alternative explanation for a study’s results. You would have to ask: Did the intervention really work, or did the participants simply guess what the researchers expected them to do and change their behavior accordingly?
Table 10.1 summarizes the four types of experimental designs covered in this chapter.
TABLE 10.1 Two Independent-Groups Designs and Two Within-Groups Designs
INDEPENDENT-GROUPS DESIGNS
WITHIN-GROUPS DESIGNS
Definition: Different participants at each level of independent variable
Definition: Same participants at all levels of independent variable
Posttest-only design
Pretest/posttest design
Repeated-measures design
Concurrent-measures design
Is Pretest/Posttest a Repeated-Measures Design?
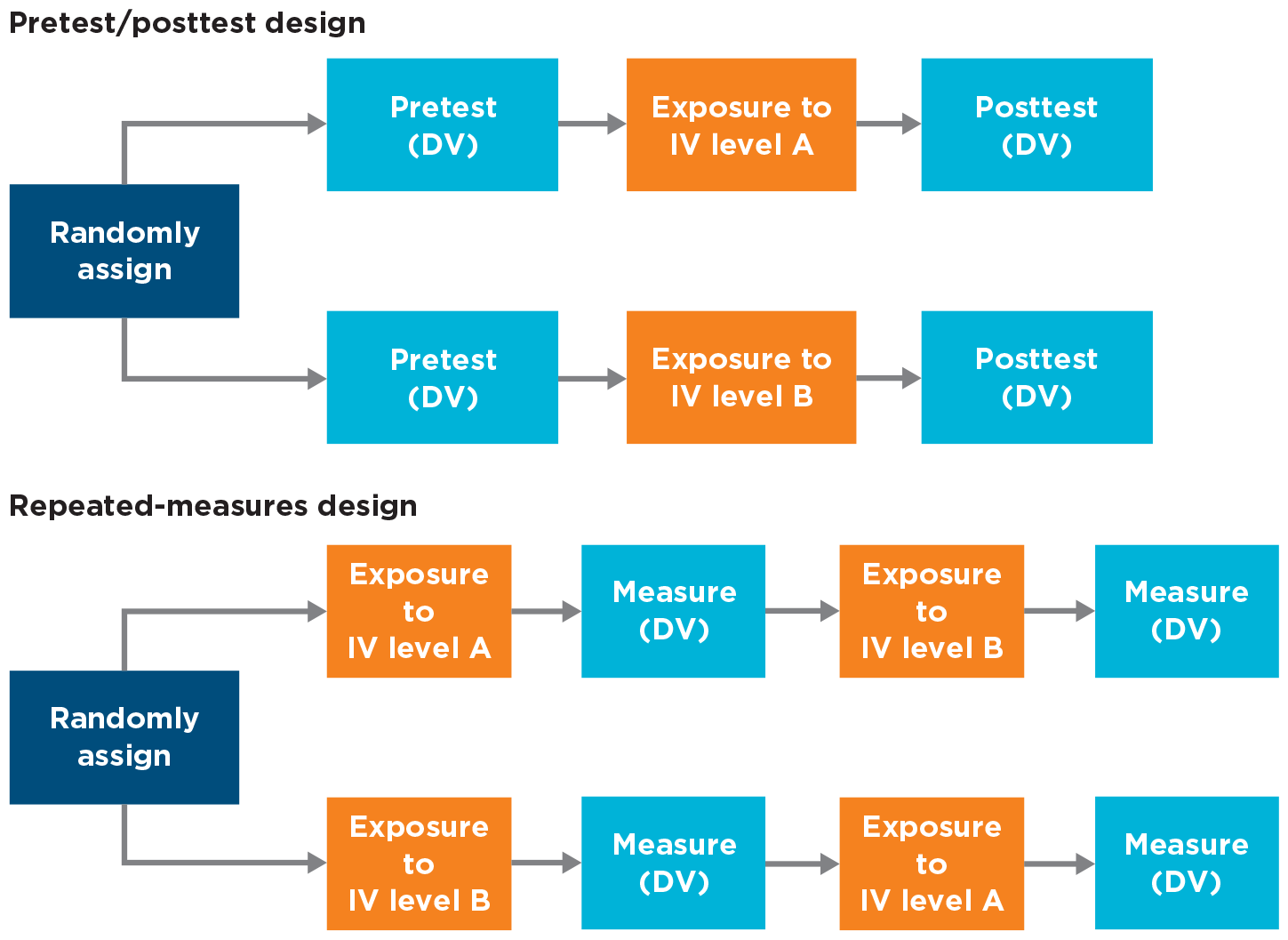
You might wonder whether the pretest/posttest independent-groups design should be considered a repeated-measures design. After all, in both designs, participants are tested on the dependent variable twice.
In a true repeated-measures design, however, participants are exposed to all levels of a meaningful independent variable, such as a shared or unshared experience, or the gender of the face they’re looking at. The levels of such independent variables can also be counterbalanced. In contrast, in a pretest/posttest design, participants see only one level of the independent variable, not all levels (Figure 10.18).
More information
Two flow charts, depicting pretest posttest design and repeated measures design.
FIGURE 10.18
Pretest/posttest design versus repeated-measures design.
In a pretest/posttest design, participants see only one level of the independent variable, but in a repeated-measures design, they see all the levels (DV = dependent variable; IV = independent variable).
TRY THIS!
Repeated-measures designs and concurrent-measures designs are both within-groups designs. What is the main way they differ?
Name one advantage of within-groups designs. Name one potential disadvantage.
An experiment using a within-groups design in which participants respond to a dependent variable more than once, after exposure to each level of the independent variable.
An experiment using a within-groups design in which participants are exposed to all the levels of an independent variable at roughly the same time, and a single attitudinal or behavioral preference is the dependent variable.
In a within-groups design, a threat to internal validity in which exposure to one condition changes participant responses to a later condition. See also carryover effect, practice effect, testing threat.
A type of order effect in which participants’ performance improves over time because they become practiced at the dependent measure (not because of the manipulation or treatment). Also called fatigue effect. See also order effect, testing threat.
A type of order effect in which participants’ performance degrades over time because they become tired, not because of the manipulation or treatment. See also order effect, practice effect.
In a repeated-measures experiment, presenting the levels of the independent variable to participants in different sequences to control for order effects. See also full counterbalancing, partial counterbalancing.
A method of counterbalancing in which some, but not all, of the possible condition orders are represented. See also counterbalancing, full counterbalancing.
 TRY THIS!
TRY THIS!