SMALL MOLECULES IN CELLS
Having looked at the ways atoms combine to form small molecules and how these molecules behave in an aqueous environment, we now examine the main classes of small molecules found in cells and their biological roles. Amazingly, we will see that a few basic categories of molecules, formed from just a handful of different elements, give rise to all the extraordinary richness of form and behavior displayed by living things.
A Cell Is Formed from Carbon Compounds
If we disregard water, nearly all the molecules in a cell are based on carbon. Carbon is outstanding among all the elements in its ability to form large molecules. Because a carbon atom is small and has four electrons and four vacancies in its outer shell, it readily forms four covalent bonds with other atoms (see Figure 2–9). Most importantly, one carbon atom can link to other carbon atoms through highly stable covalent C–C bonds, producing rings and chains that can form the backbone of complex molecules with no obvious upper limit to their size. These carbon-containing compounds are called organic molecules. By contrast, all other molecules, including water, are said to be inorganic.
In addition to containing carbon, the organic molecules produced by cells frequently contain specific combinations of atoms, such as the methyl (–CH3), hydroxyl (–OH), carboxyl (–COOH), carbonyl (–C=O), phosphoryl (–PO32–), and amino (–NH2) groups. Each of these chemical groups has distinct chemical and physical properties that influence the behavior of the molecule in which the group occurs, including whether the molecule tends to gain or lose protons when dissolved in water and with which other molecules it will interact. Knowing these groups and their chemical properties greatly simplifies understanding the chemistry of life. The most common chemical groups and some of their properties are summarized in Panel 2–1 (pp. 66–67).
Cells Contain Four Major Families of Small Organic Molecules
The small organic molecules of the cell are carbon compounds with molecular weights in the range 100–1000 that contain up to 30 or so carbon atoms. They are usually found free in solution in the cytosol and have many different roles. Some are used as monomer subunits to construct the cell’s polymeric macromolecules—its proteins, nucleic acids, and large polysaccharides. Others serve as energy sources, being broken down and transformed into other small molecules in a maze of intracellular metabolic pathways. Many have more than one role in the cell—acting, for example, as both a potential subunit for a macromol-ecule and as an energy source. The small organic molecules are much less abundant than the organic macromolecules, accounting for only about one-tenth of the total mass of organic matter in a cell. But small organic molecules adopt a huge variety of chemical forms. Nearly 4000 different kinds of small organic molecules have been detected in the well-studied bacterium Escherichia coli.
All organic molecules are synthesized from—and are broken down into—the same set of simple compounds. Both their synthesis and their breakdown occur through sequences of simple chemical changes that are limited in variety and follow step-by-step rules. As a consequence, the compounds in a cell are chemically related, and most can be classified into a small number of distinct families. Broadly speaking, cells contain four major families of small organic molecules: the sugars, the fatty acids, the amino acids, and the nucleotides (Figure 2–17). Although many compounds present in cells do not fit into these categories, these four families of small organic molecules—together with the macromol-ecules made by linking them into long chains—account for a large fraction of a cell’s mass (Table 2–2).
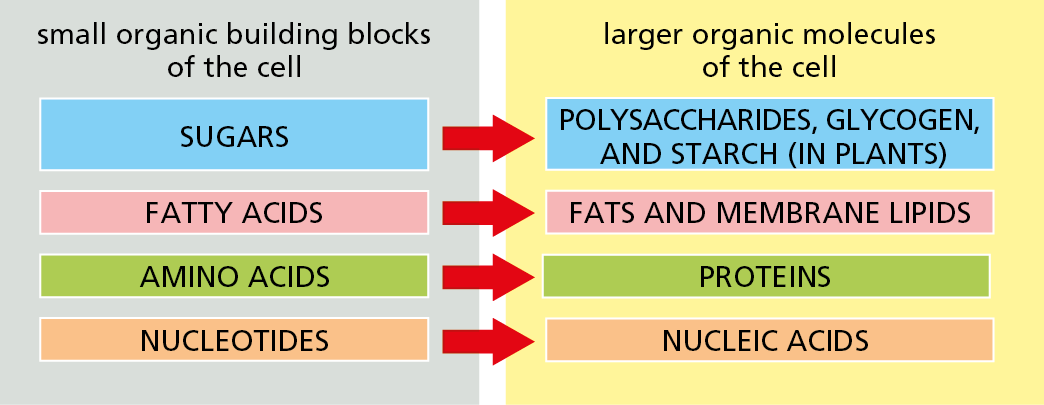
Figure 2–17 Sugars, fatty acids, amino acids, and nucleotides are the four main families of small organic molecules in cells. They form the monomeric building blocks, or subunits, for larger organic molecules, including most of the macromolecules and other molecular assemblies of the cell. Some, like the sugars and the fatty acids, are also energy sources.
|
Table 2–2 the chemical composition of a bacterial cell |
||
|
Substance |
Percent of Total Cell Weight |
Approximate Number of Types in Each Class |
|
Water |
70 |
1 |
|
Inorganic ions |
1 |
20 |
|
Sugars and precursors |
1 |
250 |
|
Amino acids and precursors |
0.4 |
100 |
|
Nucleotides and precursors |
0.4 |
100 |
|
Fatty acids and precursors |
1 |
50 |
|
Other small molecules |
0.2 |
3000 |
|
Phospholipids |
2 |
4* |
|
Macromolecules (nucleic acids, proteins, and polysaccharides) |
24 |
3000 |
|
*There are four classes of phospholipids, each of which exists in many varieties (discussed in Chapter 4). |
||
Sugars Are both Energy Sources and Subunits of Polysaccharides
The simplest sugars—the monosaccharides—are compounds with the general formula (CH2O)n, where n is usually 3, 4, 5, or 6. Glucose, for example, has the formula C6H12O6 (Figure 2–18). Because of this simple formula, sugars, and the larger molecules made from them, are called carbohydrates. The formula, however, does not adequately define the molecule: the same set of carbons, hydrogens, and oxygens can be joined together by covalent bonds in a variety of ways, creating structures with different shapes. Thus glucose can be converted into a different sugar—mannose or galactose—simply by switching the orientations of specific –OH groups relative to the rest of the molecule (Panel 2–4, pp. 72–73). In addition, each of these sugars can exist in either of two forms, called the D-form and the L-form, which are mirror images of each other. Sets of molecules with the same chemical formula but different structures are called isomers, and mirror-image pairs of such molecules are called optical isomers. Isomers are widespread among organic molecules in general, and they play a major part in generating the enormous variety of sugars. A more complete outline of sugar structures and chemistry is presented in Panel 2–4.
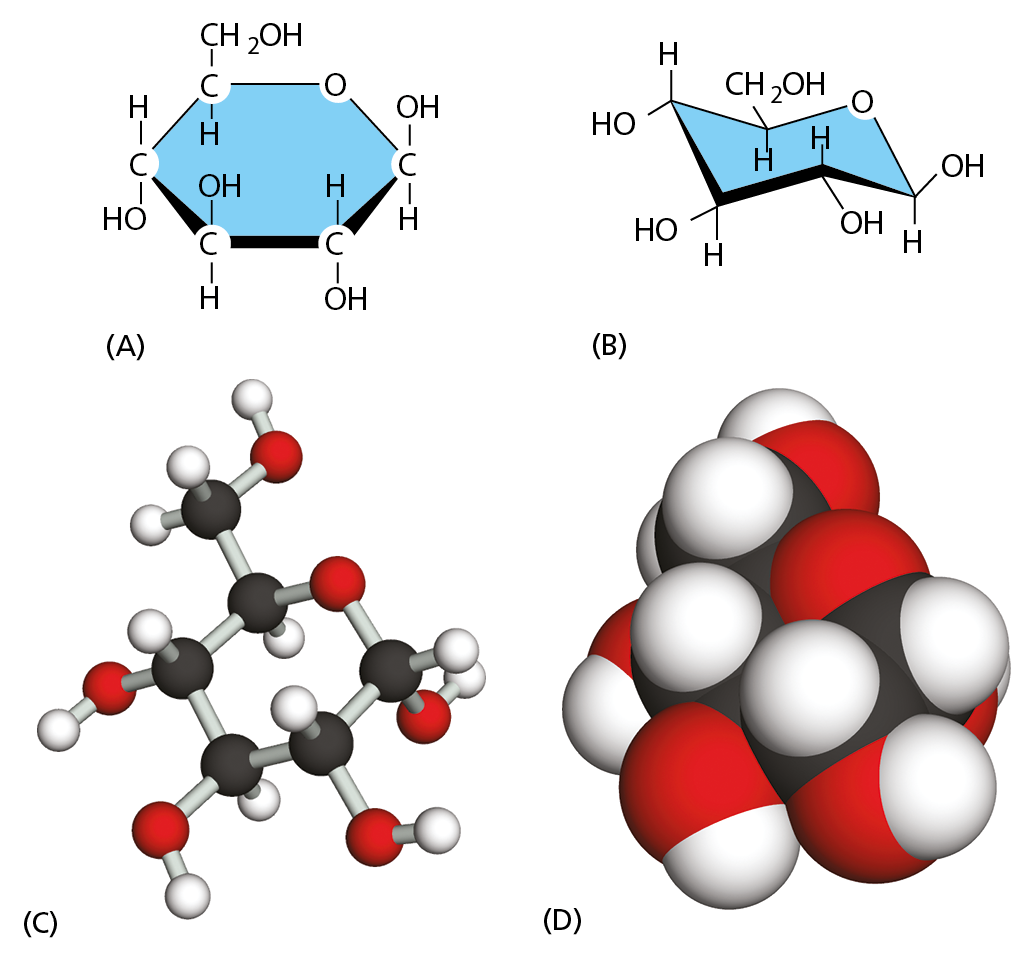
Figure 2–18 The structure of glucose, a monosaccharide, can be represented in several ways. (A) A structural formula in which the atoms are shown as chemical symbols, linked together by solid lines representing the covalent bonds. The thickened lines are used to indicate the plane of the sugar ring and to show that the –H and –OH groups are not in the same plane as the ring. (B) Another kind of structural formula that shows the three-dimensional structure of glucose in a so-called “chair configuration.” (C) A ball-and-stick model in which the three-dimensional arrangement of the atoms in space is indicated. (D) A space-filling model, which, as well as depicting the three-dimensional arrangement of the atoms, also shows the relative sizes and surface contours of the molecule (Movie 2.1). The atoms in (C) and (D) are colored as in Figure 2–9: C, black; H, white; O, red. This is the conventional color-coding for these atoms and will be used throughout this book.
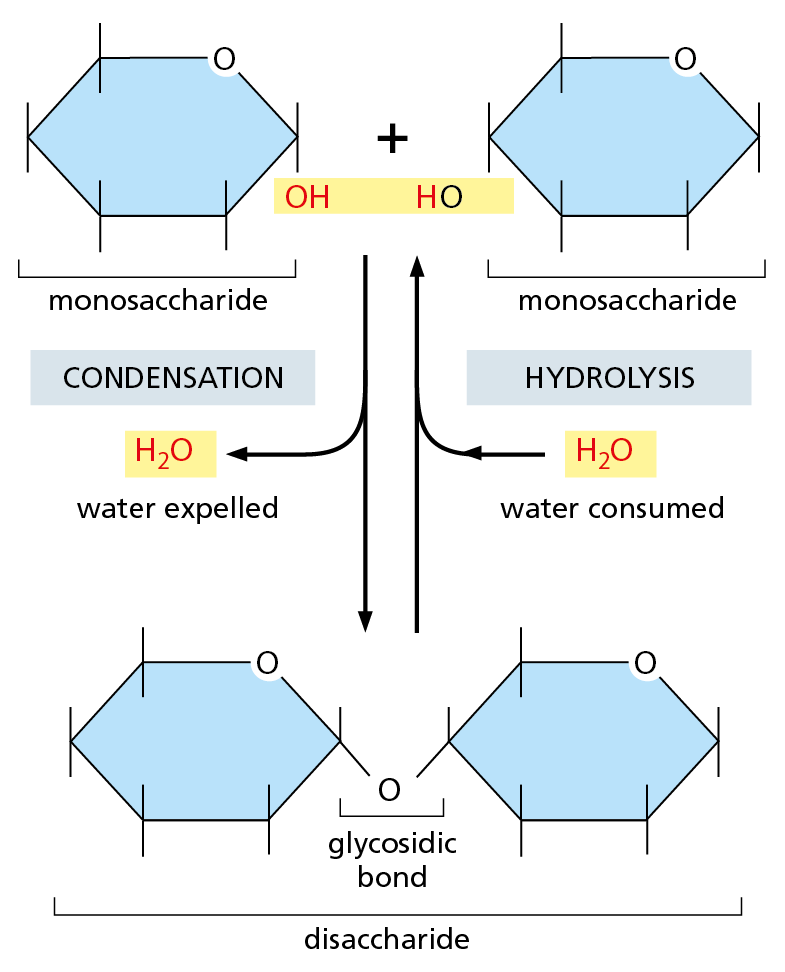
Figure 2–19 Two monosaccharides can be linked by a covalent glycosidic bond to form a disaccharide. This reaction belongs to a general category of reactions termed condensation reactions, in which two molecules join together as a result of the loss of a water molecule. The reverse reaction (in which water is added) is termed hydrolysis.
Monosaccharides can be linked by covalent bonds—called glycosidic bonds—to form larger carbohydrates. Two monosaccharides linked together make a disaccharide, such as sucrose, which is composed of a glucose and a fructose unit. Larger sugar polymers range from the oligosaccharides (trisaccharides, tetrasaccharides, and so on) up to giant polysaccharides, which can contain thousands of monosaccharide subunits (monomers). In most cases, the prefix oligo- is used to refer to molecules made of a small number of monomers, typically 2 to 10 in the case of oligosaccharides. Polymers, in contrast, can contain hundreds or thousands of subunits.
The way sugars are linked together illustrates some common features of biochemical bond formation. A bond is formed between an –OH group on one sugar and an –OH group on another by a condensation reaction, in which a molecule of water is expelled as the bond is formed (Figure 2–19). The subunits in other biological polymers, including nucleic acids and proteins, are also linked by condensation reactions in which water is expelled. The bonds created by all of these condensation reactions can be broken by the reverse process of hydrolysis, in which a molecule of water is consumed. Generally speaking, condensation reactions, which synthesize larger molecules from smaller subunits, are energetically unfavorable; hydrolysis reactions, which break down larger molecules into smaller subunits, are energetically favorable (Figure 2−20).
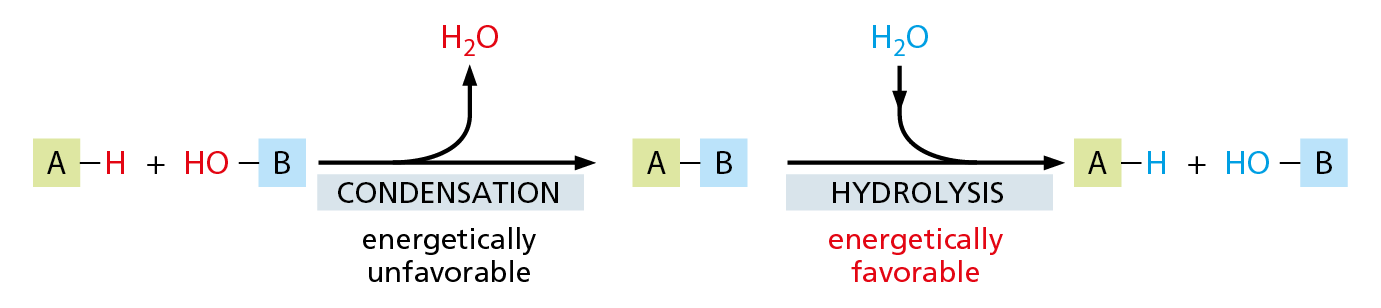
Figure 2–20 Condensation and hydrolysis are reverse reactions. The large polymeric macromolecules of the cell are formed from subunits (or monomers) by condensation reactions, and they are broken down by hydrolysis. Condensation reactions are energetically unfavorable; thus macromolecule formation requires an input of energy, as we discuss in Chapter 3.
Because each monosaccharide has several free hydroxyl groups that can form a link to another monosaccharide (or to some other compound), sugar polymers can be branched, and the number of possible polysaccharide structures is extremely large. For this reason, it is much more difficult to determine the arrangement of sugars in a complex polysaccharide than it is to determine the nucleotide sequence of a DNA molecule or the amino acid sequence of a protein, in which each unit is joined to the next in exactly the same way.
The monosaccharide glucose has a central role as an energy source for cells, as we explain in Chapter 13. It is broken down to smaller molecules in a series of reactions, releasing energy that the cell can harness to do useful work. Cells use simple polysaccharides composed only of glucose units—principally glycogen in animals and starch in plants—as long-term stores of glucose, held in reserve for energy production.
Sugars do not function exclusively in the production and storage of energy. They are also used, for example, to make mechanical supports. The most abundant organic molecule on Earth—the cellulose that forms plant cell walls—is a polysaccharide of glucose. Another extraordinarily abundant organic substance, the chitin of insect exoskeletons and fungal cell walls, is also a polysaccharide—in this case, a linear polymer of a sugar derivative called N-acetylglucosamine (see Panel 2–4, pp. 72–73). Other polysaccharides, which tend to be slippery when wet, are the main components of slime, mucus, and gristle.
Smaller oligosaccharides can be covalently linked to proteins to form glycoproteins, or to lipids to form glycolipids (Panel 2–5, pp. 74–75), which are both found in cell membranes. The sugar side chains attached to glycoproteins and glycolipids in the plasma membrane are thought to help protect the cell surface and often help cells adhere to one another. Differences in the types of cell-surface sugars form the molecular basis for the human blood groups, information that dictates which blood types can be used during transfusions.
Fatty Acid Chains Are Components of Cell Membranes
A fatty acid molecule, such as palmitic acid, has two chemically distinct regions. One is a long hydrocarbon chain, which is hydrophobic and not very reactive chemically. The other is a carboxyl (–COOH) group, which behaves as an acid (carboxylic acid): in an aqueous solution, it is ionized (–COO–), extremely hydrophilic, and chemically reactive (Figure 2–21). Molecules—such as fatty acids—that possess both hydrophobic and hydrophilic regions are termed amphipathic. Almost all the fatty acid molecules in a cell are covalently linked to other molecules by their carboxylic acid group (see Panel 2–5, pp. 74–75).
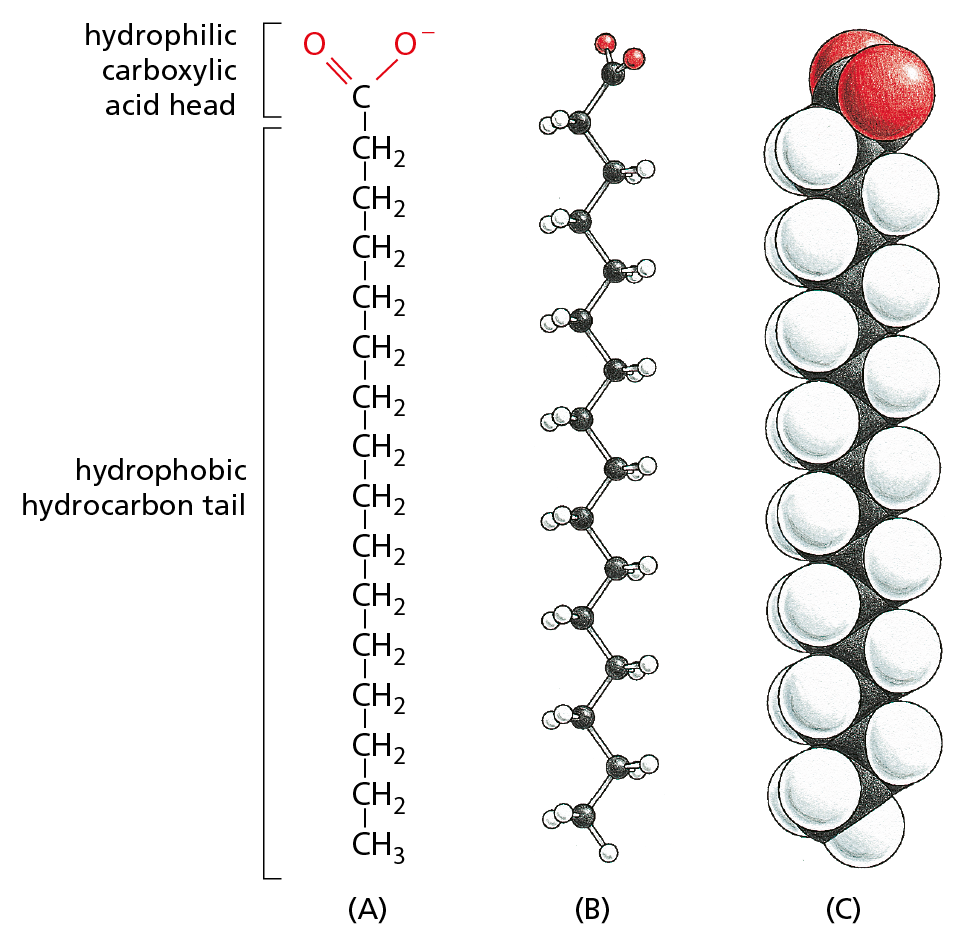
Figure 2–21 Fatty acids have both hydrophobic and hydrophilic components. The hydrophobic hydrocarbon chain is attached to a hydrophilic carboxylic acid group. Different fatty acids have different hydrocarbon tails. Palmitic acid is shown here. (A) Structural formula, showing the carboxylic acid head group in its ionized form, as it exists in water at pH 7. (B) Ball-and-stick model. (C) Space-filling model (Movie 2.2).
The hydrocarbon tail of palmitic acid is saturated: it has no double bonds between its carbon atoms and contains the maximum possible number of hydrogens. Some other fatty acids, such as oleic acid, have unsaturated tails, with one or more double bonds along their length. The double bonds create kinks in the hydrocarbon tails, interfering with their ability to pack together. Fatty acid tails are found in cell membranes, where the tightness of their packing affects the fluidity of the membrane. The many different fatty acids found in cells differ only in the length of their hydrocarbon chains and in the number and position of the carbon–carbon double bonds (see Panel 2–5).
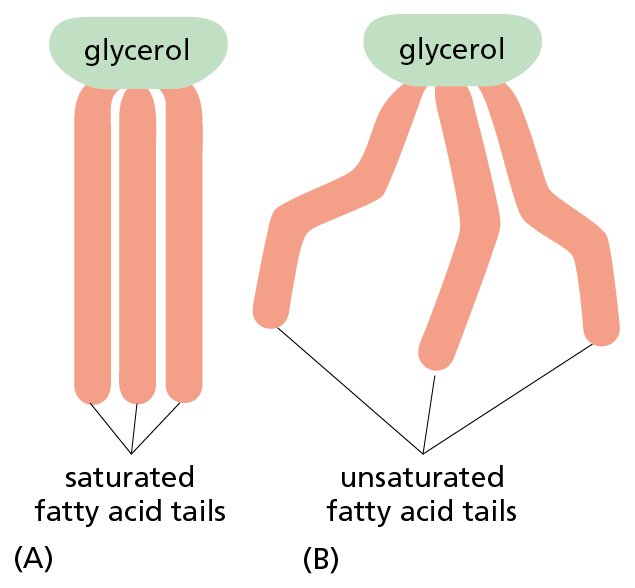
Figure 2–22 The properties of fats depend on the length and saturation of the fatty acid chains they carry. Fatty acids are stored in the cytosol of many cells in the form of droplets of triacylglycerol molecules made of three fatty acid chains joined to a glycerol molecule. (A) Saturated fats are found in meat and dairy products. (B) Plant oils, such as corn oil, contain unsaturated fatty acids, which may be monounsaturated (containing one double bond) or polyunsaturated (containing multiple double bonds). The presence of these double bonds causes plant oils to be liquid at room temperature. Although fats are essential in the diet, saturated fats raise the concentration of cholesterol in the blood, which tends to clog the arteries, increasing the risk of heart attacks and strokes.
Fatty acids serve as a concentrated food reserve in cells: they can be broken down to produce about six times as much usable energy, gram for gram, as glucose. Fatty acids are stored in the cytoplasm of many cells in the form of fat droplets composed of triacylglycerol molecules—compounds made of three fatty acid chains covalently joined to a glycerol molecule (Figure 2–22 and see Panel 2–5). Triacylglycerols are the animal fats found in meat, butter, and cream, and the plant oils such as corn oil and olive oil. When a cell needs energy, the fatty acid chains can be released from triacylglycerols and broken down into two-carbon units. These two-carbon units are identical to those derived from the breakdown of glucose, and they enter the same energy-yielding reaction pathways, as described in Chapter 13.
Fatty acids and their derivatives, including triacylglycerols, are examples of lipids. Lipids are loosely defined as molecules that are insoluble in water but soluble in fat and organic solvents such as benzene. They typically contain long hydrocarbon chains, as in the fatty acids, or multiple linked aromatic rings, as in the steroids (see Panel 2–5).
The most unique function of fatty acids is in the establishment of the lipid bilayer, the structure that forms the basis for all cell membranes. These thin sheets, which enclose all cells and surround their internal organelles, are composed largely of phospholipids (Figure 2–23).
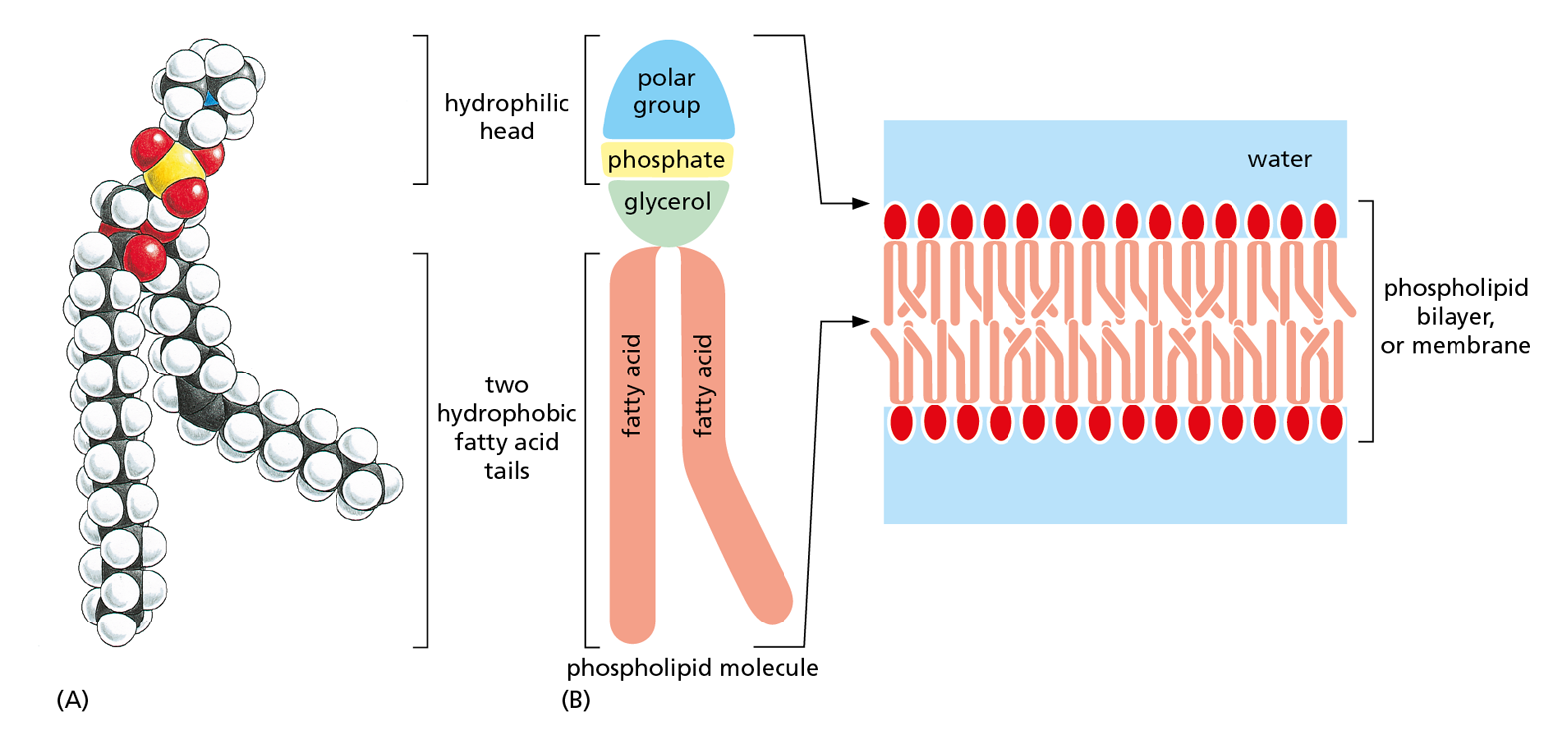
Figure 2–23 Phospholipids can aggregate to form cell membranes. Phospholipids contain two hydrophobic fatty acid tails and a hydrophilic head. (A) Phosphatidylcholine is the most common phospholipid in cell membranes. (B) Diagram showing how, in an aqueous environment, the hydrophobic tails of phospholipids pack together to form a lipid bilayer. In the lipid bilayer, the hydrophilic heads of the phospholipid molecules are on the outside, facing the aqueous environment, and the hydrophobic tails are on the inside, where water is excluded.
Like triacylglycerols, most phospholipids are constructed mainly from fatty acids and glycerol. In these phospholipids, however, the glycerol is joined to two fatty acid chains, rather than to three as in triacylglycerols. The remaining –OH group on the glycerol is linked to a hydrophilic phosphate group, which in turn is attached to a small hydrophilic compound such as choline (see Panel 2–5, pp. 74–75). With their two hydrophobic fatty acid tails and a hydrophilic, phosphate-containing head, phospholipids are strongly amphipathic. This characteristic amphipathic composition and shape gives them very different physical and chemical properties from triacylglycerols, which are predominantly hydrophobic. In addition to phospholipids, cell membranes contain differing amounts of other lipids, including glycolipids, which are structurally similar to phospholipids but contain one or more sugars instead of a phosphate group.
Thanks to their amphipathic nature, pure phospholipids readily form membranes in water. These lipids can spread over the surface of water to form a monolayer, with their hydrophobic tails facing the air and their hydrophilic heads in contact with the water. Alternatively, two of these phospholipid layers can readily combine tail-to-tail in water to form the phospholipid sandwich that is the lipid bilayer (see Chapter 11).
Amino Acids Are the Subunits of Proteins
Amino acids are small organic molecules with one defining property: they all possess a carboxylic acid group and an amino group, both attached to a central α-carbon atom (Figure 2–24). This α-carbon also carries a specific side chain, the identity of which distinguishes one amino acid from another.
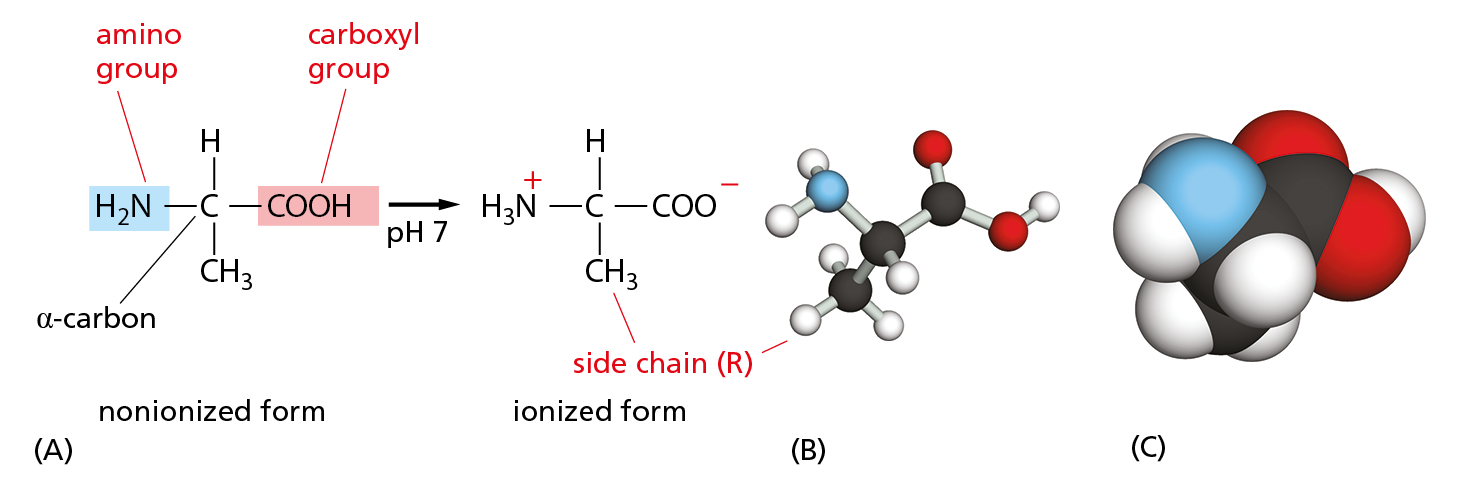
Figure 2–24 All amino acids have an amino group, a carboxyl group, and a side chain (R) attached to their α-carbon atom. In the cell, where the pH is close to 7, free amino acids exist in their ionized form; but, when they are incorporated into a polypeptide chain, the charges on their amino and carboxyl groups are lost. (A) The amino acid shown is alanine, one of the simplest amino acids, which has a methyl group (CH3) as its side chain. Its amino group is highlighted in blue and its carboxyl group in red. (B) A ball-and-stick model and (C) a space-filling model of alanine. In (B) and (C), the N atom is blue and the O atom is red.
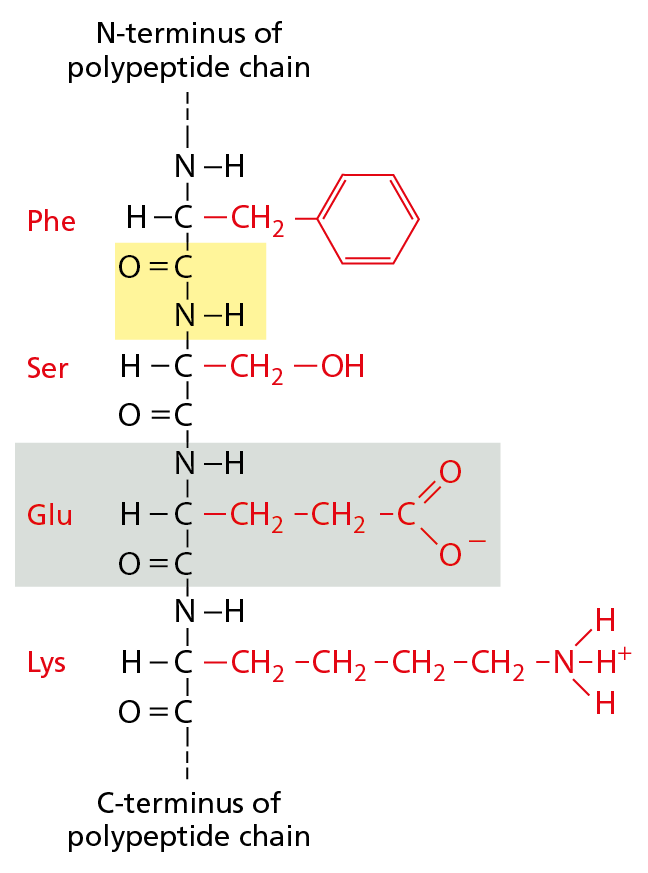
Figure 2–25 Amino acids in a protein are held together by peptide bonds. The four amino acids shown are linked together by three peptide bonds, one of which is highlighted in yellow. One of the amino acids, glutamic acid, is shaded in gray. The amino acid side chains are shown in red. The N-terminus of the polypeptide chain is capped by an amino group, and the C-terminus ends in a carboxyl group. The sequence of amino acids in a protein is abbreviated using either a three-letter or a one-letter code, and the sequence is always read starting from the N-terminus (see Panel 2–6, pp. 76–77). In the example given, the sequence is Phe-Ser-Glu-Lys (or FSEK).
Cells use amino acids to build proteins—polymers made of amino acids, which are joined head-to-tail in a long chain that folds up into a three-dimensional structure that is unique to each type of protein. The covalent bond between two adjacent amino acids in a protein chain is called a peptide bond, and the resulting chain of amino acids is therefore also known as a polypeptide. Peptide bonds are formed by condensation reactions that link one amino acid to the next. Regardless of the specific amino acids from which it is made, the polypeptide always has an amino (NH2) group at one end—its N-terminus—and a carboxyl (COOH) group at its other end—its C-terminus (Figure 2–25). This difference in the two ends gives a polypeptide a definite directionality—a structural (as opposed to electrical) polarity.
Twenty types of amino acids are commonly found in proteins, each with a different side chain attached to its α-carbon atom (Panel 2–6, pp. 76–77). How this precise set of 20 amino acids came to be chosen is one of the mysteries surrounding the evolution of life; there is no obvious chemical reason why other amino acids could not have served just as well. But once the selection had been locked into place, it could not be changed, as too much chemistry had evolved to exploit it. Switching the types of amino acids used by cells—whether bacterial, plant, or animal—would require the organism to retool its entire metabolism to cope with the new building blocks.
Question 2–6
Why do you suppose only l-amino acids and not a random mixture of the l- and d-forms of each amino acid are used to make proteins?
Like sugars, all amino acids (except glycine) exist as optical isomers termed d- and l-forms (see Panel 2–6). But only l-forms are ever found in proteins (although d-amino acids occur as part of bacterial cell walls and in some antibiotics, and d-serine is used as a signal molecule in the brain). The origin of this exclusive use of l-amino acids to make proteins is another evolutionary mystery.
The chemical versatility that the 20 standard amino acids provide is vitally important to the function of proteins. Five of the 20 amino acids—including lysine and glutamic acid, shown in Figure 2–25—have side chains that form ions in solution and can therefore carry a charge. The others are uncharged. Some amino acids are polar and hydrophilic, and some are nonpolar and hydrophobic (see Panel 2–6). As we discuss in Chapter 4, the collective properties of the amino acid side chains underlie all the diverse and sophisticated functions of proteins. And proteins, which constitute half the dry mass of a cell, lie at the center of life’s chemistry.
Nucleotides Are the Subunits of DNA and RNA
DNA and RNA are built from subunits called nucleotides. Nucleotides consist of a nitrogen-containing ring compound linked to a five-carbon sugar that has one or more phosphate groups attached to it (Panel 2–7, pp. 78–79). The sugar can be either ribose or deoxyribose. Nucleotides containing ribose are known as ribonucleotides, and those containing deoxyribose are known as deoxyribonucleotides.
The nitrogen-containing rings of all these molecules are generally referred to as bases for historical reasons: under acidic conditions, they can each bind an H+ (proton) and thereby increase the concentration of OH– ions in aqueous solution. There is a strong family resemblance between the different nucleotide bases. Cytosine (C), thymine (T), and uracil (U) are called pyrimidines, because they all derive from a six-membered pyrimidine ring; guanine (G) and adenine (A) are purines, which bear a second, five-membered ring fused to the six-membered ring. Each nucleotide is named after the base it contains (see Panel 2–7, pp. 78–79). A base plus its sugar (without any phosphate group attached) is called a nucleoside.
Nucleoside di- and triphosphates can act as short-term carriers of chemical energy. Above all others, the ribonucleoside triphosphate known as adenosine triphosphate, or ATP (Figure 2–26), participates in the transfer of energy in hundreds of metabolic reactions. ATP is formed through reactions that are driven by the energy released from the breakdown of foodstuffs. Its three phosphates are linked in series by two phosphoanhydride bonds (see Panel 2–7). Rupture of these phosphate bonds by hydrolysis releases large amounts of useful energy, also known as free energy (see Panel 3–1, pp. 94–95). Most often, it is the terminal phosphate group that is split off—or transferred to another molecule—to release energy that can be used to drive biosynthetic reactions (Figure 2–27). Other nucleotide derivatives serve as carriers for other chemical groups. All of this is described in Chapter 3.
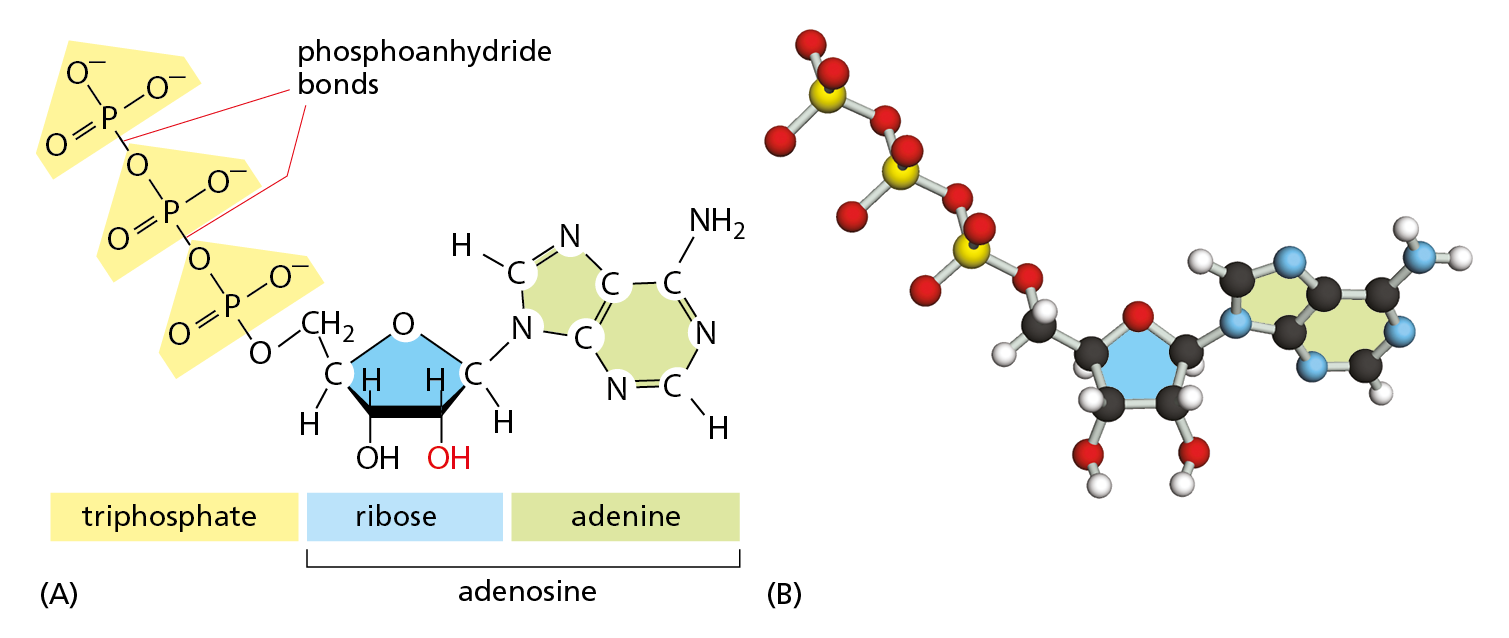
Figure 2–26 Adenosine triphosphate (ATP) is a crucially important energy carrier in cells.(A) Structural formula, in which the three phosphate groups are shaded in yellow. The presence of the OH group on the second carbon of the sugar ring (red) distinguishes this sugar as ribose. (B) Ball-and-stick model (Movie 2.3). In (B), the P atoms are yellow.
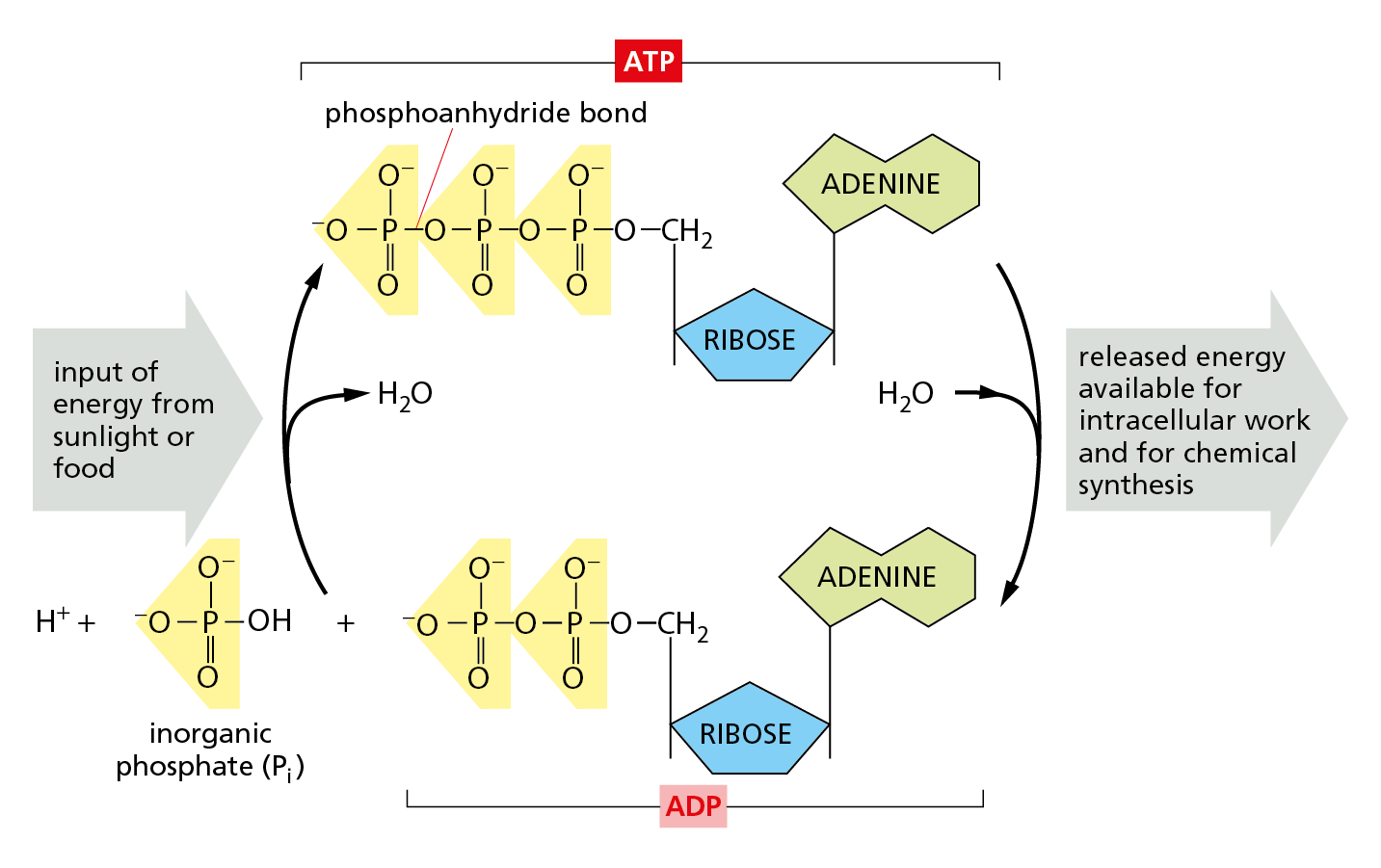
Figure 2–27 ATP is synthesized from ADP and inorganic phosphate, and it releases energy when it is hydrolyzed back to ADP and inorganic phosphate. The energy required for ATP synthesis is derived from either the energy-yielding oxidation of foodstuffs (in animal cells, fungi, and some bacteria) or the capture of light (in plant cells and some bacteria). The hydrolysis of ATP releases energy that is used to drive many processes inside cells. Together, the two reactions shown form the ATP cycle.
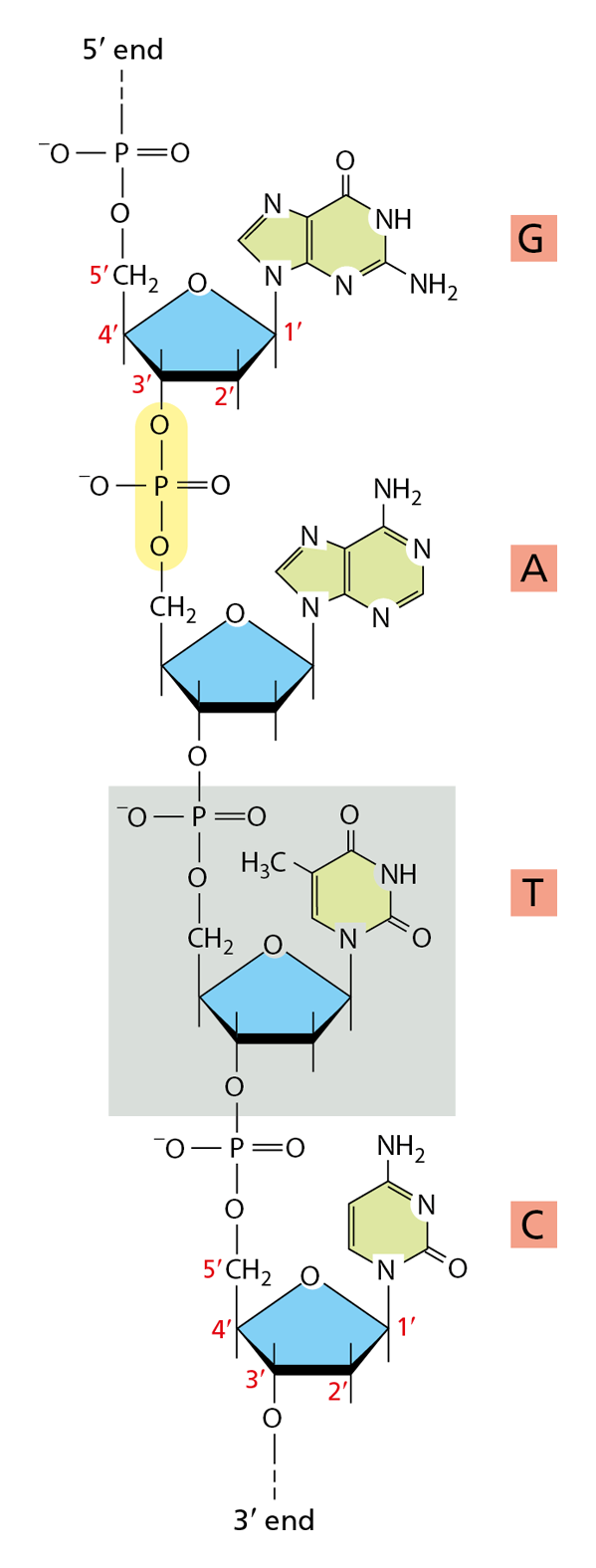
Figure 2–28 A short length of one chain of a deoxyribonucleic acid (DNA) molecule shows the covalent phosphodiester bonds linking four consecutive nucleotides. Because the bonds link specific carbon atoms in the sugar ring—known as the 5ʹ and 3ʹ carbon atoms—one end of a polynucleotide chain, the 5ʹ end, has a free phosphate group and the other, the 3ʹ end, has a free hydroxyl group. One of the nucleotides, T, is shaded in gray, and one phosphodiester bond is highlighted in yellow. The linear sequence of nucleotides in a polynucleotide chain is commonly abbreviated using a one-letter code, and the sequence is always read from the 5ʹ end. In the example illustrated, the sequence is GATC.
Nucleotides also have a fundamental role in the storage and retrieval of biological information. They serve as building blocks for the construction of nucleic acids—long polymers in which nucleotide subunits are linked by the formation of covalent phosphodiester bonds between the phosphate group attached to the sugar of one nucleotide and a hydroxyl group on the sugar of the next nucleotide (Figure 2–28). Nucleic acid chains are synthesized from energy-rich nucleoside triphosphates by a condensation reaction that releases inorganic pyrophosphate during phosphodiester bond formation (see Panel 2–7, pp. 78–79).
There are two main types of nucleic acids, which differ in the type of sugar contained in their sugar–phosphate backbone. Those based on the sugar ribose are known as ribonucleic acids, or RNA, and contain the bases A, G, C, and U. Those based on deoxyribose (in which the hydroxyl group at the 2ʹ position of the ribose carbon ring is replaced by a hydrogen) are known as deoxyribonucleic acids, or DNA, and contain the bases A, G, C, and T (T is chemically similar to the U in RNA; see Panel 2–7). RNA usually occurs in cells in the form of a single-stranded polynucleotide chain, but DNA is virtually always in the form of a double-stranded molecule: the DNA double helix is composed of two polynucleotide chains that run in opposite directions and are held together by hydrogen bonds between the bases of the two chains (see Panel 2–3, pp. 70–71).
The linear sequence of nucleotides in a DNA or an RNA molecule encodes genetic information. The two nucleic acids, however, have different roles in the cell. DNA, with its more stable, hydrogen-bonded helix, acts as a long-term repository for hereditary information, while single-stranded RNA is usually a more transient carrier of molecular instructions. The ability of the bases in different nucleic acid molecules to recognize and pair with each other by hydrogen-bonding (called base-pairing)—G with C, and A with either T or U—underlies all of heredity and evolution, as explained in Chapter 5.
- organic molecule
Chemical compound that contains carbon and hydrogen.
- inorganic
Not composed of carbon atoms.
- chemical group
A combination of atoms, such as a hydroxyl group (–OH) or an amino group (–NH2), with distinct chemical and physical properties that influence the behavior of the molecule in which it resides.
- sugar
A substance made of carbon, hydrogen, and oxygen with the general formula (CH2O)n. A carbohydrate or saccharide. The “sugar” of everyday use is sucrose, a sweet-tasting disaccharide made of glucose and fructose.
- condensation reaction
Chemical reaction in which a covalent bond is formed between two molecules as water is expelled; used to build polymers, such as proteins, polysaccharides, and nucleic acids.
- hydrolysis
Chemical reaction that involves cleavage of a covalent bond with the accompanying consumption of water (its –H being added to one product of the cleavage and its –OH to the other); the reverse of a condensation reaction.
- fatty acid
Molecule that consists of a carboxylic acid attached to a long hydrocarbon chain. Used as a major source of energy during metabolism and as a starting point for the synthesis of phospholipids.
- lipid
An organic molecule that is insoluble in water but dissolves readily in nonpolar organic solvents; typically contains long hydrocarbon chains or multiple rings. One class, the phospholipids, forms the structural basis for biological membranes.
- lipid bilayer
Thin pair of closely juxtaposed sheets, composed mainly of phospholipid molecules, that forms the structural basis for all cell membranes.
- amino acid
Small organic molecule containing both an amino group and a carboxyl group; it serves as the building block of proteins.
- protein
Macromolecule built from amino acids that provides cells with their shape and structure and performs most of their activities.
- nucleotide
Basic building block of the nucleic acids, DNA and RNA; a nucleoside linked to a phosphate.
- ATP
Activated carrier that serves as the principal carrier of energy in cells; a nucleoside triphosphate composed of adenine, ribose, and three phosphate groups. (See Figure 2–26.)
- RNA (ribonucleic acid)
Molecule produced by the transcription of DNA; usually single-stranded, it is a polynucleotide composed of covalently linked ribonucleotide subunits. Serves a variety of informational, structural, catalytic, and regulatory functions in cells.
- deoxyribonucleic acid (DNA)
Double-stranded polynucleotide formed from two separate chains of covalently linked deoxyribonucleotide units. It serves as the cell’s store of genetic information that is transmitted from generation to generation.