The constant supply of energy that cells need to generate and maintain the biological order that keeps them alive comes from the chemical-bond energy in food molecules.
The proteins, lipids, and polysaccharides that make up most of the food we eat must be broken down into smaller molecules before our cells can use them—either as a source of energy or as building blocks for other molecules. Enzymatic digestion breaks down the large polymeric molecules in food into their monomer subunits—proteins into amino acids, polysaccharides into sugars, and fats into fatty acids and glycerol. After digestion, the small organic molecules derived from food enter the cytosol of cells, where their gradual oxidation begins.
Sugars are particularly important fuel molecules, and they are oxidized in small controlled steps to carbon dioxide (CO2) and water (Figure 2–45). In this section, we trace the major steps in the breakdown, or catabolism, of sugars and show how they produce ATP, NADH, and other activated carrier molecules in animal cells. A very similar pathway also operates in plants, fungi, and many bacteria. As we shall see, the oxidation of fatty acids is equally important for cells. Other molecules, such as proteins, can also serve as energy sources when they are funneled through appropriate enzymatic pathways.
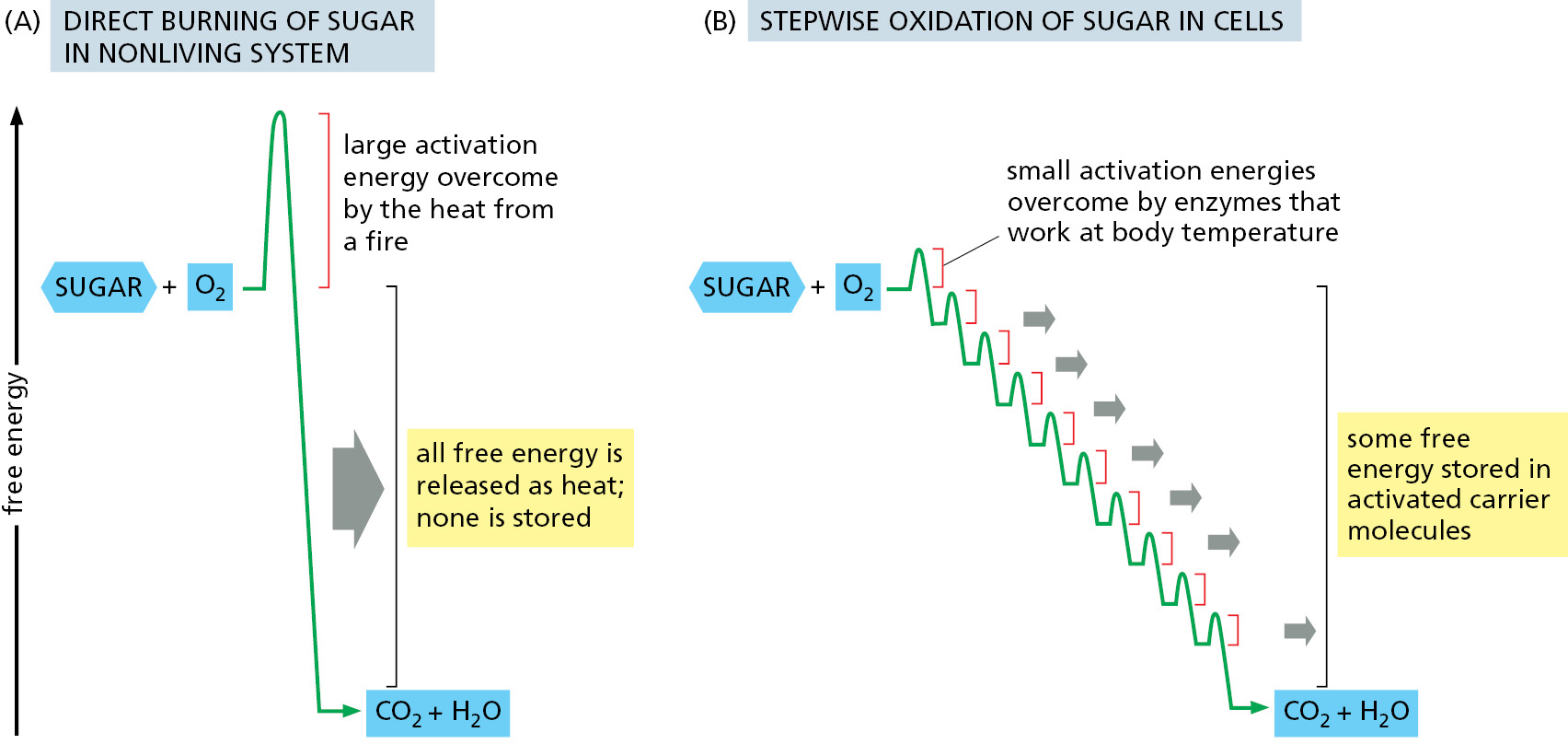
Figure 2–45Schematic representation of the controlled stepwise oxidation of sugar in a cell, compared with ordinary burning. (A) If the sugar were oxidized to CO2 and H2O in a single step, it would release an amount of energy much larger than could be captured for useful purposes. (B) In the cell, enzymes catalyze oxidation via a series of small steps in which free energy is transferred in conveniently sized packets to carrier molecules—most often ATP and NADH. Heat is also released, enabling the universe to be disordered sufficiently to make the entire pathway energetically favorable (ΔG is negative). Each step is catalyzed by an enzyme that lowers the activation-energy barrier that must be surmounted by the random collision of molecules to allow the reaction to occur at the temperature inside cells (see Figure 2–24). Note that the total free energy released by the complete oxidative breakdown of glucose to CO2 and H2O—2880 kJ/mole—is exactly the same in (A) and (B).
Glycolysis Is a Central ATP-producing Pathway
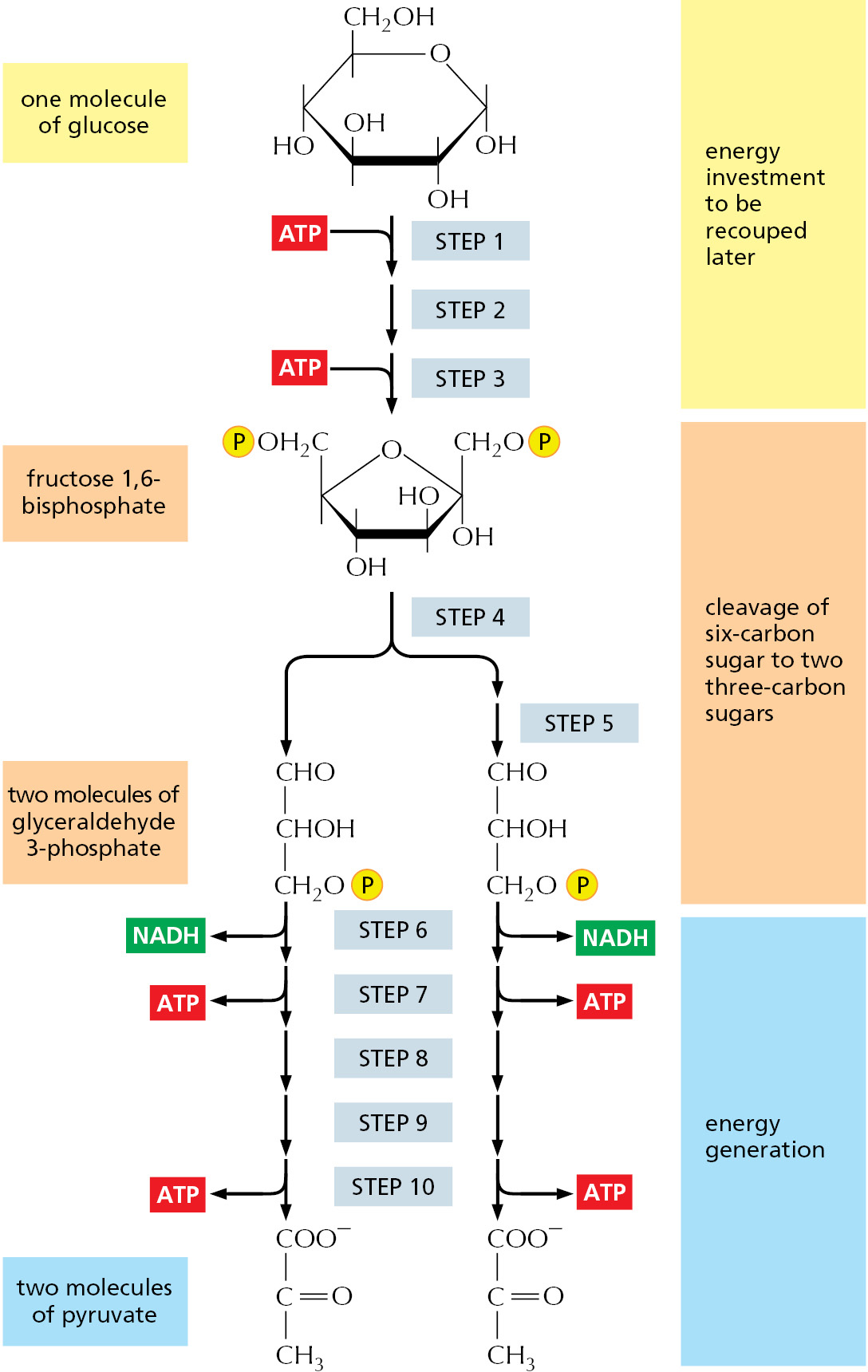
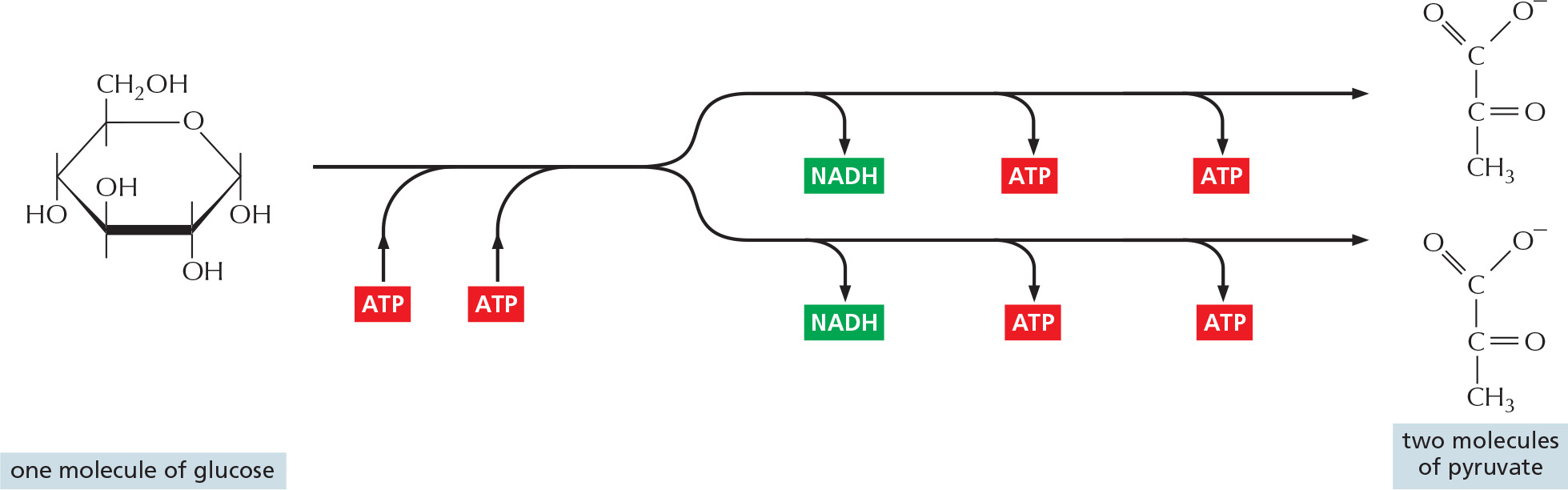
The major process for oxidizing sugars is the sequence of reactions known as glycolysis, which produces ATP without the involvement of molecular oxygen (O2 gas). It occurs in the cytosol of most cells, including many anaerobic microorganisms. Glycolysis probably evolved early in the history of life, before photosynthetic organisms introduced oxygen into the atmosphere. During glycolysis, a glucose molecule with six carbon atoms is converted into two molecules of pyruvate, each of which contains three carbon atoms. For each glucose molecule, two molecules of ATP are hydrolyzed to provide energy to drive the early steps, but four molecules of ATP are produced in the later steps. At the end of glycolysis, there is consequently a net gain of two molecules of ATP for each glucose molecule broken down.
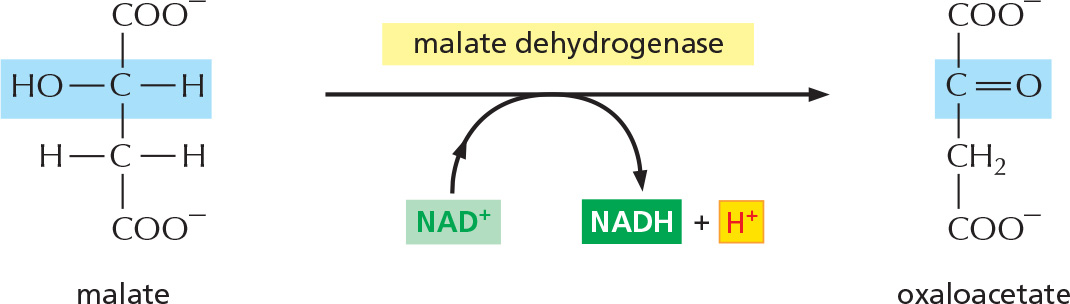
Piecing together the complete glycolytic pathway in the 1930s was a major triumph of biochemistry, as the pathway consists of a sequence of 10 separate reactions, each producing a different sugar intermediate and each catalyzed by a different enzyme. These enzymes, like most enzymes, all have names ending in “-ase”—like isomerase and dehydrogenase—which specify the type of reaction they catalyze. The sugar oxidation occurs when electrons are removed by NAD+ (producing NADH) from some of the carbons derived from the glucose molecule. Some of the energy released by this oxidation drives the direct synthesis of ATP molecules from ADP and phosphate, and some remains with the electrons in the activated electron carrier NADH. The pathway is outlined in Figure 2–46 and shown in detail in Panel 2–8 (pp. 108–109) and Movie 2.5.
Figure 2–46An outline of glycolysis. Each of the 10 steps shown is catalyzed by a different enzyme. Note that step 4 cleaves a six-carbon sugar into two three-carbon sugars, so that the number of molecules at every stage after this doubles. Note also that one of the two products of step 4 is modified (isomerized) in step 5 to convert it into a second molecule of glyceraldehyde 3-phosphate, the other product of step 4. As indicated, step 6 begins the energy-generation phase of glycolysis. Because two molecules of ATP are hydrolyzed in the early, energy-investment phase, glycolysis results in the net synthesis of 2 ATP and 2 NADH molecules per molecule of glucose. Glycolysis is also referred to as the Embden–Meyerhof pathway, named for the biochemists who first described it. All the steps of glycolysis are reviewed in Panel 2–8 and Movie 2.5.
Two molecules of NADH are formed per molecule of glucose in the course of glycolysis. As we shall see, in aerobic organisms these NADH molecules donate their electrons to the electron-transport chain described in Chapter 14, which enables the NAD+ formed by NADH oxidization to be reused for glycolysis.
Glycolysis Illustrates How Enzymes Couple Oxidation to Energy Storage
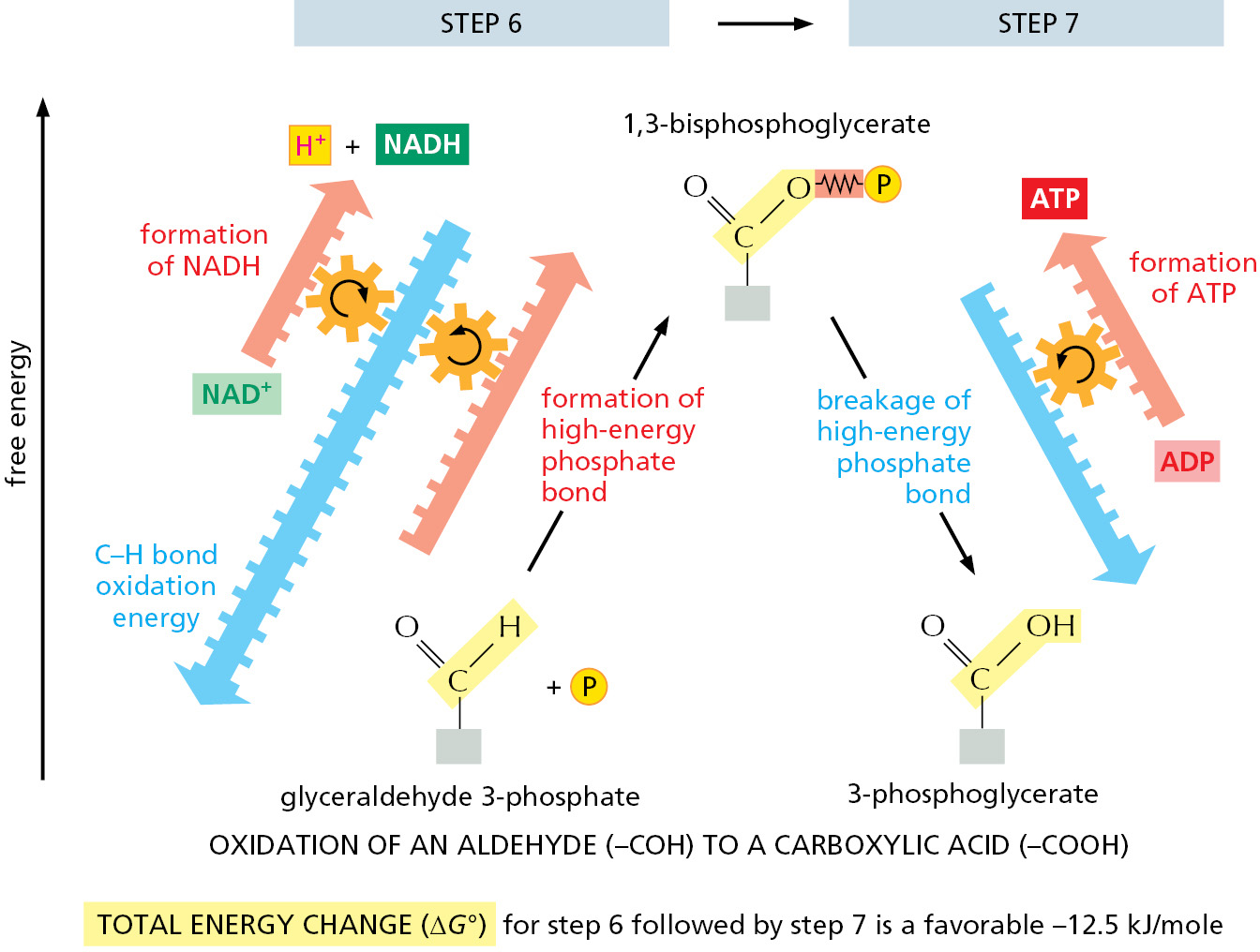
The formation of ATP during glycolysis provides a particularly clear demonstration of how enzymes couple energetically unfavorable reactions with favorable ones, thereby driving the many chemical reactions that make life possible. Two central reactions in glycolysis (steps 6 and 7) convert the three-carbon sugar intermediate glyceraldehyde 3-phosphate (an aldehyde) into 3-phosphoglycerate (a carboxylic acid; see Panel 2–8, pp. 108–109), thus oxidizing an aldehyde group to a carboxylic acid group. This sugar oxidation process releases enough free energy to convert a molecule of ADP to ATP and to transfer two electrons (and a proton) from the aldehyde to NAD+ to form NADH, while still liberating enough heat to the environment to make the overall reaction energetically favorable (ΔG° for the overall reaction is –12.5 kJ/mole).
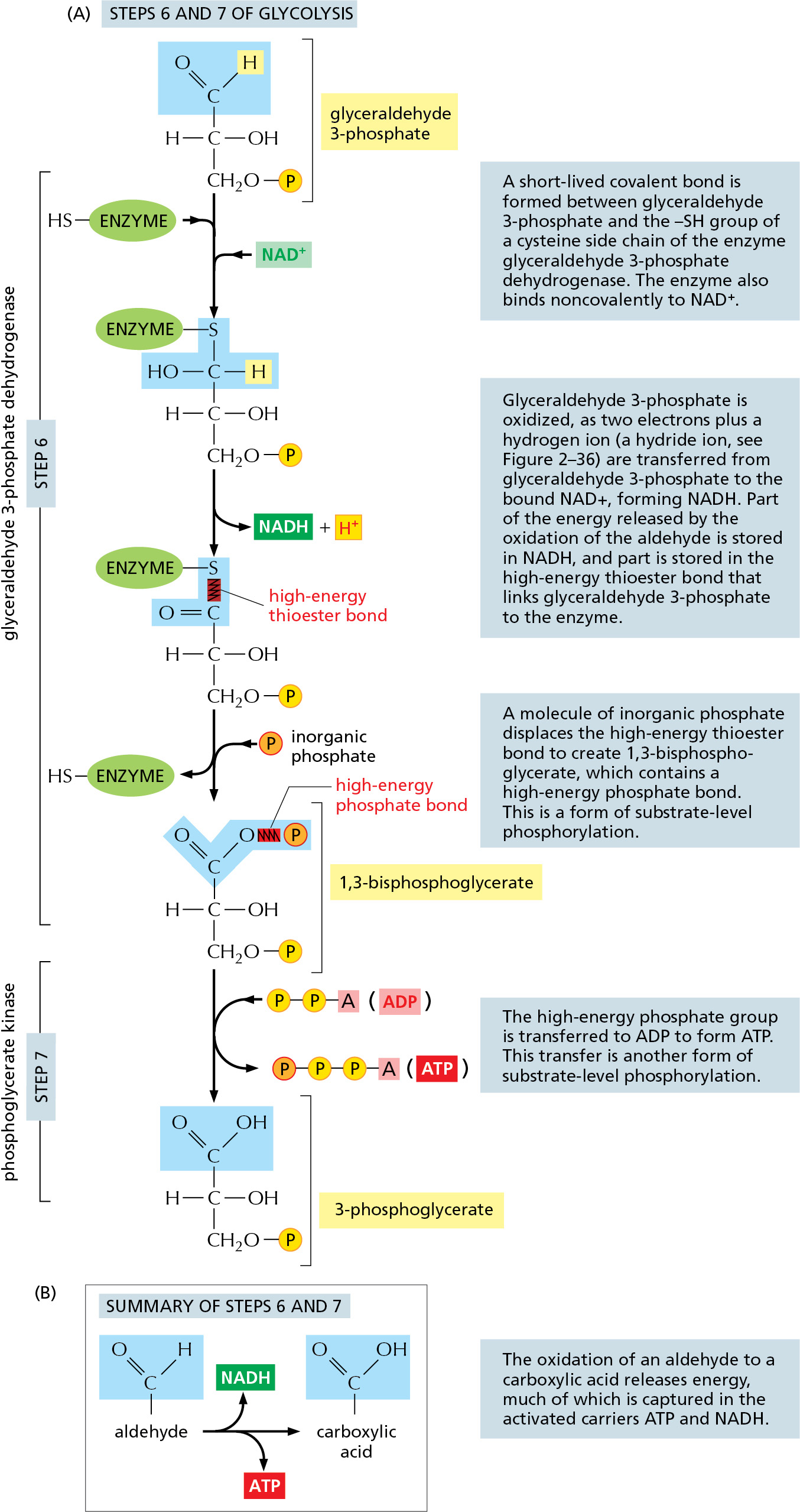
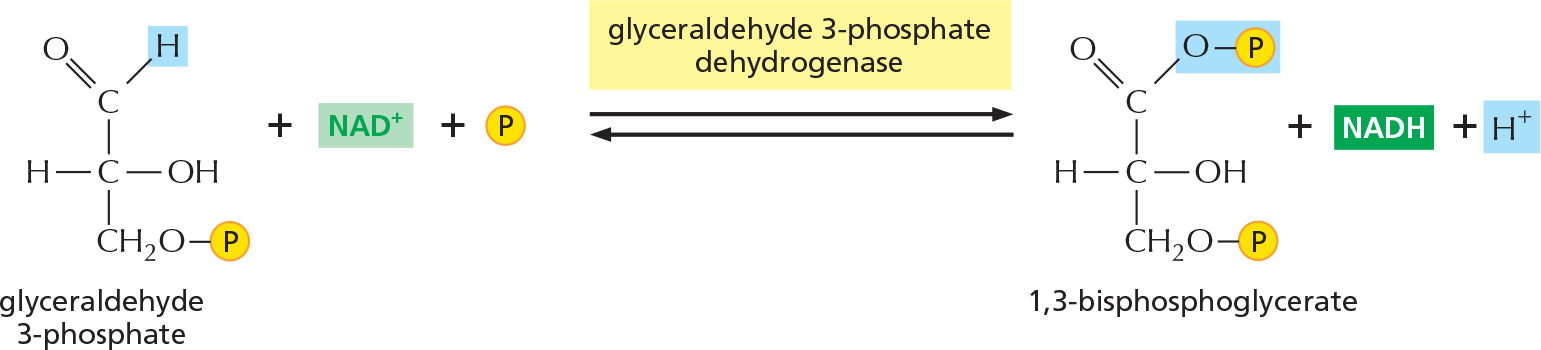
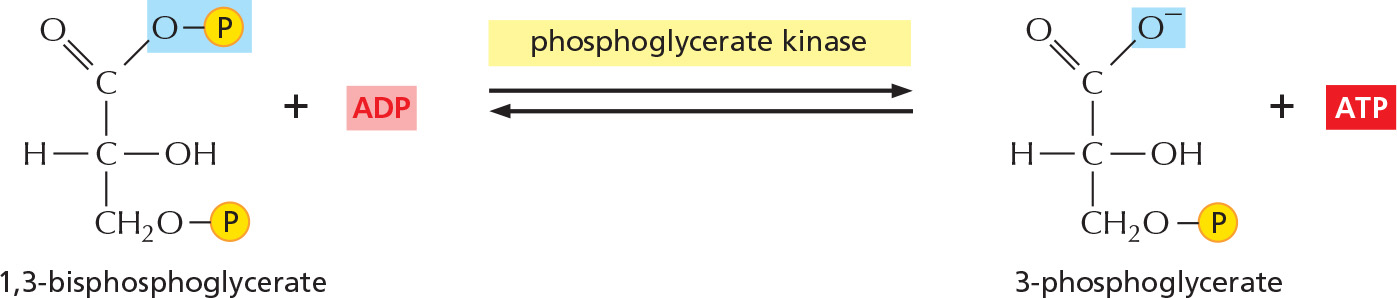
Figure 2–47 details this remarkable feat of energy harvesting. The chemical reactions are precisely guided by two enzymes to which the sugar intermediates are tightly bound. The first enzyme (glyceraldehyde 3-phosphate dehydrogenase) forms a covalent bond to the sugar aldehyde group through a reactive –SH group on the enzyme and then catalyzes the oxidation of this aldehyde group to a carboxylic acid. This creates a highly reactive enzyme–substrate bond that is displaced by an inorganic phosphate ion to produce a high-energy sugar phosphate intermediate. This intermediate (1,3-bisphosphoglycerate) then binds to the second enzyme (phosphoglycerate kinase), which catalyzes an energetically favorable transfer of its high-energy phosphate to ADP, forming ATP and completing the process of oxidizing a sugar aldehyde to a carboxylic acid.
Figure 2–47How the oxidation of glyceraldehyde 3-phosphate is coupled to the formation of ATP and NADH in steps 6 and 7 of glycolysis. (A) In step 6, the enzyme glyceraldehyde 3-phosphate dehydrogenase couples the energetically favorable oxidation of an aldehyde to the energetically unfavorable formation of a high-energy phosphate bond. At the same time, this oxidation enables energy to be stored in NADH. In step 7, the newly formed high-energy phosphate bond in 1,3-bisphosphoglycerate is transferred to ADP by the enzyme phosphoglycerate kinase, forming a molecule of ATP and leaving a free carboxylic acid group on the oxidized sugar. The part of the molecule that undergoes a change is shaded in blue; the rest of the molecule remains unchanged throughout all these reactions. (B) Summary of the overall chemical change produced by the reactions of steps 6 and 7.
We have shown this particular oxidation process in some detail because it provides a clear example of enzyme-mediated energy storage through coupled reactions (Figure 2–48). Steps 6 and 7 are the only reactions in glycolysis that create a high-energy phosphate linkage directly from inorganic phosphate. As such, they account for the net yield of two ATP molecules and two NADH molecules per molecule of glucose (see Panel 2–8, pp. 108–109).
Figure 2–48How a pair of coupled reactions drives the energetically unfavorable formation of NADH and ATP in steps 6 and 7 of glycolysis. In this diagram, energetically favorable reactions are represented by blue arrows and energetically costly reactions by red arrows. In step 6, the energy released by the energetically favorable oxidation of a C–H bond in glyceraldehyde 3-phosphate (blue arrow) is large enough to drive two energetically costly reactions: the formation of both NADH and a high-energy phosphate bond in 1,3-bisphosphoglycerate (red arrows). The subsequent energetically favorable breakage of that high-energy phosphate bond in step 7 then drives the formation of ATP.
As we have just seen, ATP can be formed readily from ADP when a reaction intermediate is formed with a phosphate bond of higher energy than that of the terminal phosphate bond in ATP. Phosphate bonds can be ordered in energy by comparing the standard free-energy change (ΔG°) for the breakage of each bond by hydrolysis. Figure 2–49 compares the high-energy phosphoanhydride bonds in ATP with the energy of other types of phosphate bonds that are generated during glycolysis.
Figure 2–49Phosphate bonds with different hydrolysis energies. Examples of molecules formed during glycolysis that contain different types of phosphate bonds are shown, along with the standard free-energy change for hydrolysis of those bonds in kJ/mole. The transfer of a phosphate group from one molecule to another is energetically favorable if the standard free-energy change (ΔG°) for hydrolysis of the phosphate bond is more negative for the donor molecule than for the acceptor. (The hydrolysis reactions can be thought of as the transfer of the phosphate group to water.) Thus, a phosphate group is readily transferred from 1,3-bisphosphoglycerate to ADP to form ATP. Transfer reactions involving the phosphate groups in these molecules are detailed in Panel 2–8 (pp. 108–109). Note that standard conditions often do not pertain to living cells, where the relative concentrations of reactants and products will influence the actual change in free energy (see p. 67).
Fermentations Produce ATP in the Absence of Oxygen
For most animal and plant cells, glycolysis is only a prelude to the final stage of the breakdown of food molecules. In these cells, the pyruvate formed by glycolysis is rapidly transported into the mitochondria, where it is converted into CO2 plus acetyl CoA, whose acetyl group is then completely oxidized to CO2 and H2O.
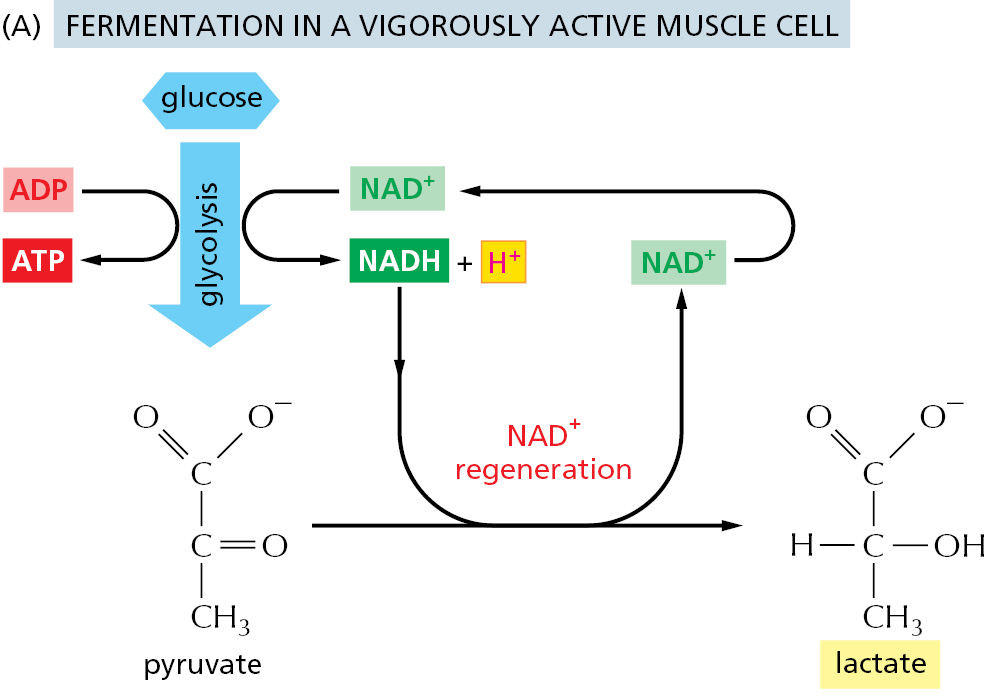
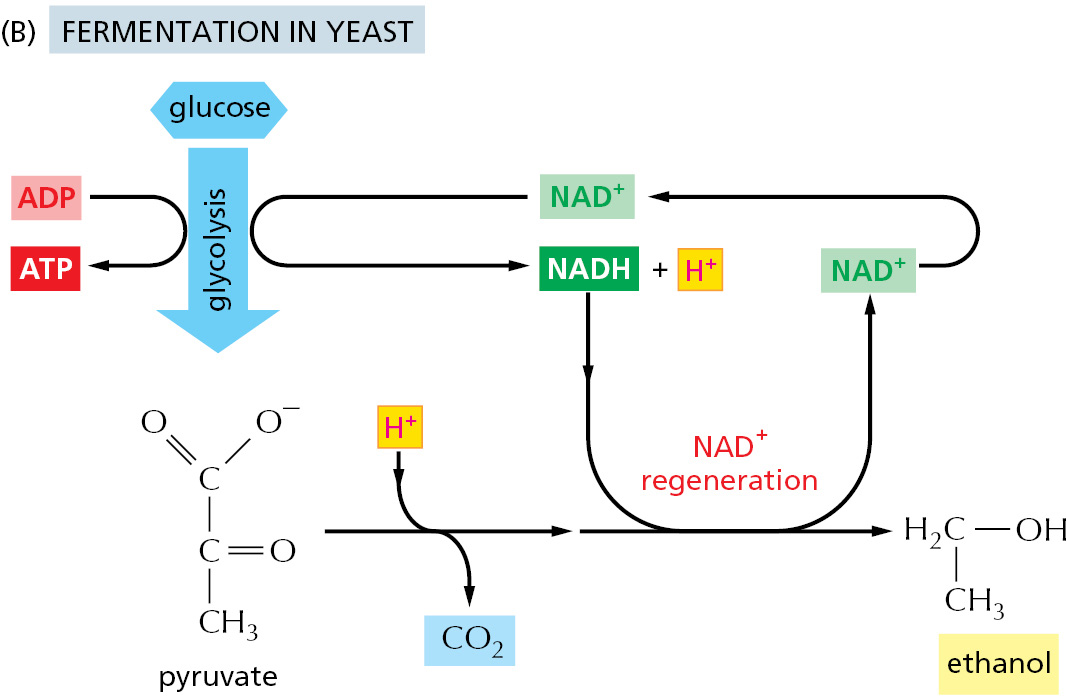
In contrast, for many anaerobic organisms—which do not utilize molecular oxygen and can grow and divide without it—glycolysis is the principal source of the cell’s ATP. Certain animal tissues, such as skeletal muscle, can also continue to function when molecular oxygen is limited. In these anaerobic conditions, the pyruvate and the NADH electrons stay in the cytosol. The pyruvate is converted into products excreted from the cell; for example, into ethanol and CO2 in the yeasts used in brewing and breadmaking or into lactic acid (lactate) in muscle. In this process, the NADH gives up its electrons and is converted back into NAD+. This is crucial, because a regeneration of NAD+ is required to maintain the reactions of glycolysis (Figure 2–50). Energy-yielding pathways like these are called fermentations.
Figure 2–50Two pathways for the anaerobic breakdown of pyruvate. (A) When there is inadequate oxygen in a muscle cell undergoing vigorous contraction, the pyruvate produced by glycolysis is converted to lactic acid (lactate) as shown. This reaction regenerates the NAD+ required in step 6 of glycolysis, but the whole pathway yields much less energy overall than complete oxidation does. (B) In some organisms that can grow anaerobically, such as yeasts, pyruvate is converted via acetaldehyde into carbon dioxide and ethanol. Again, this pathway regenerates NAD+ from NADH, as needed for glycolysis to continue. Both (A) and (B) are examples of fermentations.
Organisms Store Food Molecules in Special Reservoirs
All organisms need to maintain a high ATP/ADP ratio to maintain biological order in their cells. Yet animals have only periodic access to food, and plants need to survive overnight without sunlight, when they are unable to produce sugar from photosynthesis. For this reason, both plants and animals convert sugars and fats to special forms for storage.
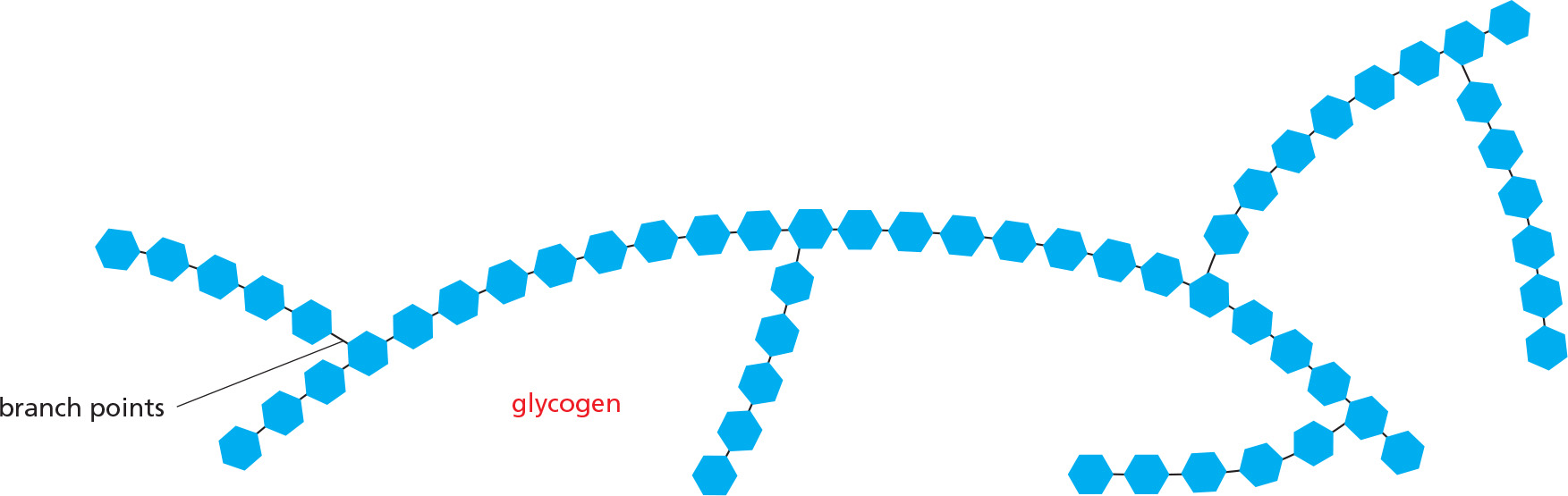
To compensate for long periods of fasting, animals store fatty acids as fat droplets composed of water-insoluble triacylglycerols (also called triglycerides). The triacylglycerols in animals are mostly stored in the cytoplasm of specialized fat cells called adipocytes (Figure 2–51). For shorter-term storage, sugar is stored as glucose subunits in the large branched polysaccharide glycogen, which is present as small granules in the cytoplasm of many cells, with the largest stores in liver and muscle.
Figure 2–51Fats stored in the form of lipid droplets in cells. (A) Fat droplets (stained red) in the cytoplasm of developing adipocytes. (B) Lipid droplets (red) in yeast cells, which also use them as a reservoir of energy and as building blocks for membrane lipid biosynthesis. (A, courtesy of Peter Tontonoz and Ronald M. Evans; B, courtesy of Sepp D. Kohlwein.)
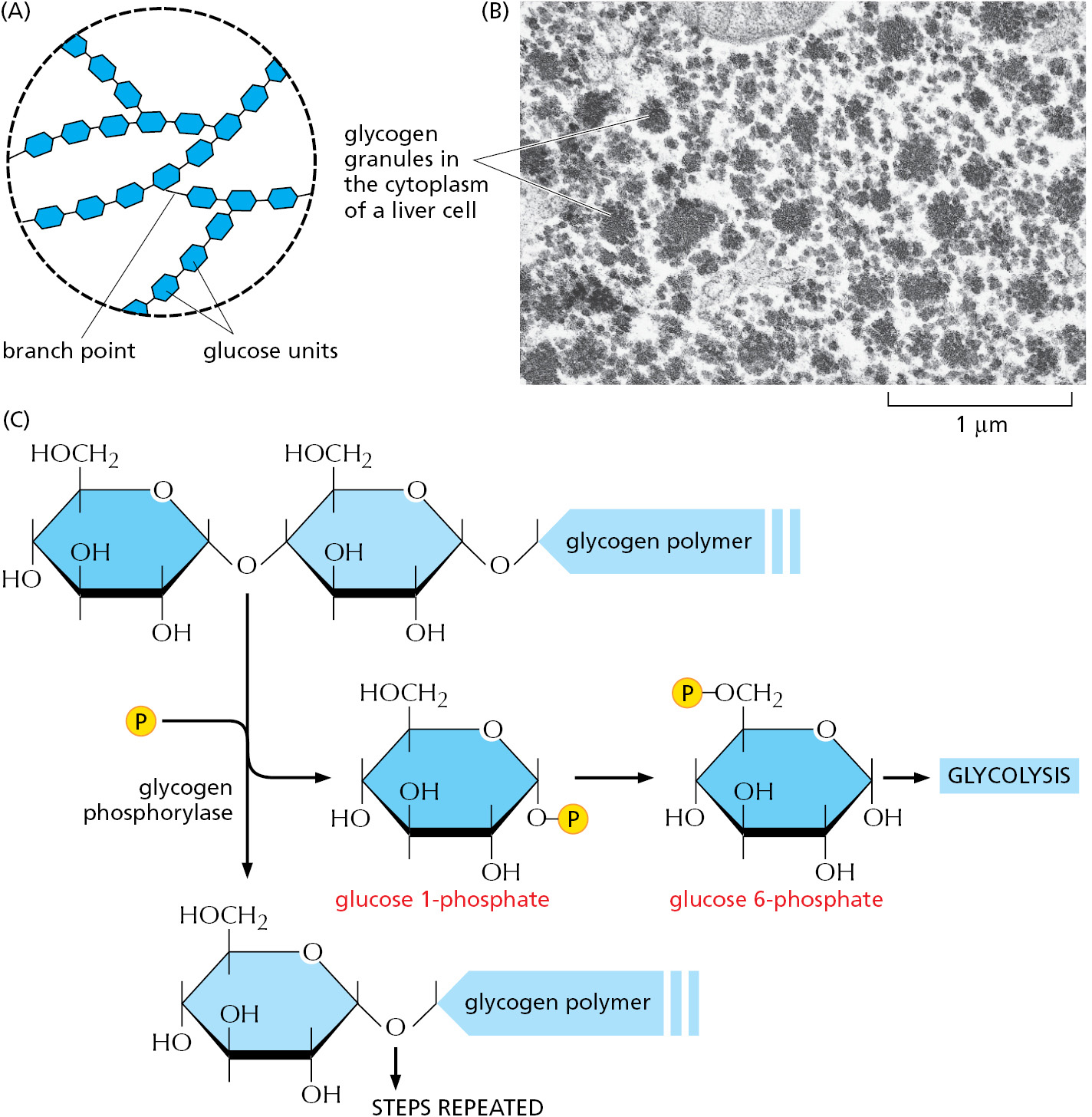
The synthesis and degradation of glycogen are rapidly regulated according to need. When cells need more ATP than they can generate from the food molecules taken in from the bloodstream, they break down glycogen in a reaction that produces glucose 1-phosphate, which is rapidly converted to glucose 6-phosphate for glycolysis (Figure 2–52). During fasting, liver cells release glucose derived from breakdown of their glycogen stores into the bloodstream for use by other cells, while muscle cells hoard their supplies for their own use.
Figure 2–52How animal cells store glucose in the form of glycogen to provide energy in times of need. (A) The structure of glycogen; starch in plants is a very similar branched polymer of glucose but has many fewer branch points. (B) An electron micrograph showing glycogen granules in the cytoplasm of a liver cell; each granule contains both glycogen and the enzymes required for glycogen synthesis and breakdown. (C) The enzyme glycogen phosphorylase breaks down glycogen when cells need more glucose. (B, courtesy of Robert Fletterick and Daniel S. Friend, by permission of E.L. Bearer.)
Quantitatively, fat is far more important than glycogen as an energy store for animals, because it provides for more efficient storage. The oxidation of a gram of fat releases about twice as much energy as the oxidation of a gram of glycogen does. Moreover, glycogen differs from fat in binding a great deal of water, producing a sixfold difference in the actual mass of glycogen required to store the same amount of energy as fat. An average adult human stores enough glycogen for only about a day of normal activities but enough fat to last for nearly a month. If our main fuel reservoir had to be carried as glycogen instead of fat, body weight would increase by an average of about 60 pounds.
How do plants store sugars and fats? Plants produce abundant amounts of both ATP and NADPH by the photosynthesis that is carried out in their chloroplasts. But this organelle is isolated from the rest of its plant cell by a membrane that is impermeable to both types of activated carrier molecules. Moreover, the plant contains many cells—such as those in the roots—that lack chloroplasts and therefore cannot produce their own sugars. Thus, sugars are exported from chloroplasts to the mitochondria present in all cells of the plant. Most of the ATP needed for general plant cell metabolism is synthesized in these mitochondria, using exactly the same pathways for the oxidative breakdown of sugars as in nonphotosynthetic organisms; this ATP is then passed to the rest of the cell.
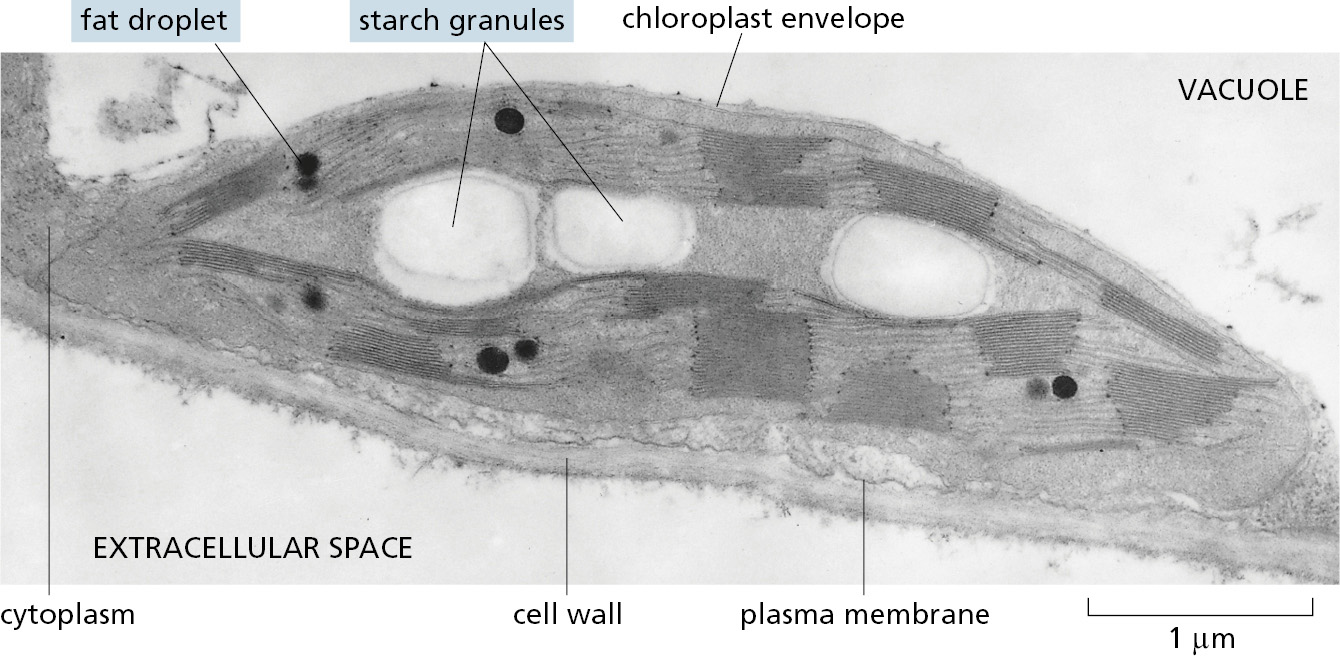
During periods of excess photosynthetic capacity during the day, chloroplasts convert some of the sugars that they make into fats and into starch, a polymer of glucose analogous to the glycogen of animals. Both are stored inside the chloroplast until needed for energy-yielding oxidation during periods of darkness (Figure 2–53).
Figure 2–53Plant cells store both starch and fats in their chloroplasts. An electron micrograph of a single chloroplast in a plant cell shows the starch granules and fat droplets that have been synthesized in the organelle. (Courtesy of K. Plaskitt.)
The embryos inside plant seeds must live on stored sources of energy for a prolonged period until they germinate and produce leaves that can harvest the energy in sunlight. For this reason, plant seeds often contain especially large amounts of fats and starch—which makes them a major food source for animals, including ourselves (Figure 2–54).
Figure 2–54Some plant seeds that serve as important foods for humans. Corn, nuts, and peas all contain rich stores of starch and fat that provide the young plant embryo in the seed with energy and building blocks for biosynthesis. (Courtesy of the John Innes Foundation.)
Between Meals, Most Animal Cells Derive Their Energy from Fatty Acids Obtained from Fat
After a meal, most of the energy that an animal needs is derived from sugars obtained from food. Excess sugars, if any, are used to replenish depleted glycogen stores or to synthesize fats as a stable longer-term food store. In the absence of another meal, the liver begins to release glucose from its store of glycogen to maintain circulating glucose levels, and the fat stored in adipose tissue is also called into play. By the morning after an overnight fast, the glycogen reserves are exhausted, and fatty acid oxidation generates most of the ATP we need.
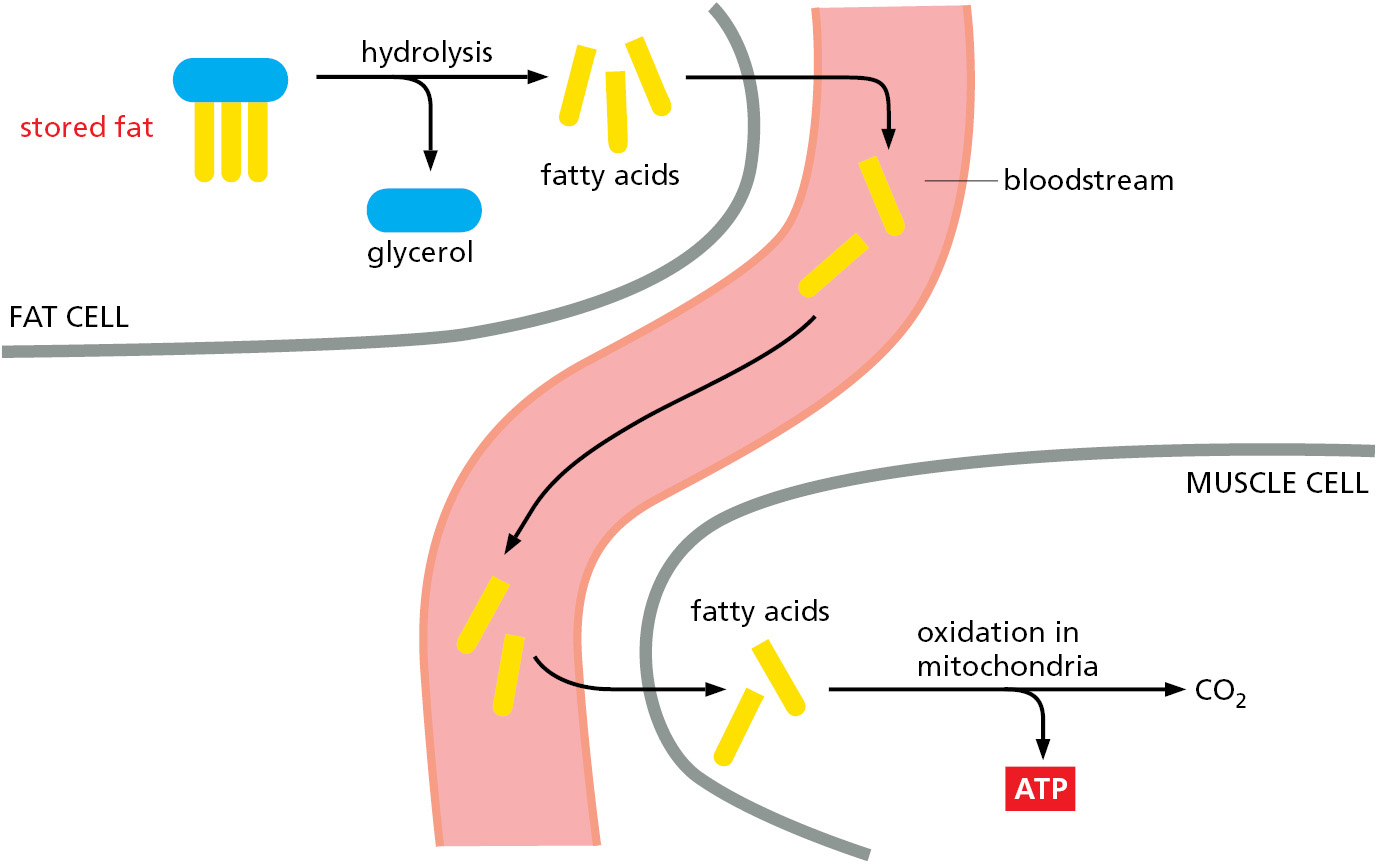
Low glucose levels in the blood trigger the breakdown of fats for energy production. As illustrated in Figure 2–55, the triacylglycerols stored in fat droplets in adipocytes are hydrolyzed to produce fatty acids and glycerol, and the fatty acids released are transferred to cells in the body through the bloodstream. Notably, the brain must rely on circulating glucose—or ketone bodies when available—because fatty acids are poorly utilized by the brain.
Figure 2–55How stored fats are mobilized for energy production in animals. Low glucose levels in the blood trigger the hydrolysis of the triacylglycerol molecules in fat droplets to free fatty acids and glycerol. These fatty acids enter the bloodstream, where they bind to the abundant blood protein, serum albumin. Special fatty acid transporters in the plasma membrane of cells that oxidize fatty acids, such as muscle cells, then pass these fatty acids into the cytosol, from which they are moved into mitochondria for energy production.
What are ketone bodies? During prolonged periods of fasting, when the circulating supply of glucose is mostly maintained by its synthesis from amino acids derived from the breakdown of proteins in muscle, the liver assumes its role as a central metabolic hub to convert fatty acids to the energy-rich molecules acetoacetate and β-hydroxybutyrate. These ketone bodies are released into the bloodstream to serve as an alternative fuel in heart and brain cells, where they are oxidized through the citric acid cycle to generate ATP. By thereby meeting most of the energy needs of the brain and heart, this process partially spares protein breakdown. Consumption of a diet very low in carbohydrate (a ketogenic diet) leads to the production of ketone bodies and can enable weight loss in most individuals. A spontaneous breakdown of acetoacetate to acetone generates the bad breath often associated both with such diets and with prolonged fasting.
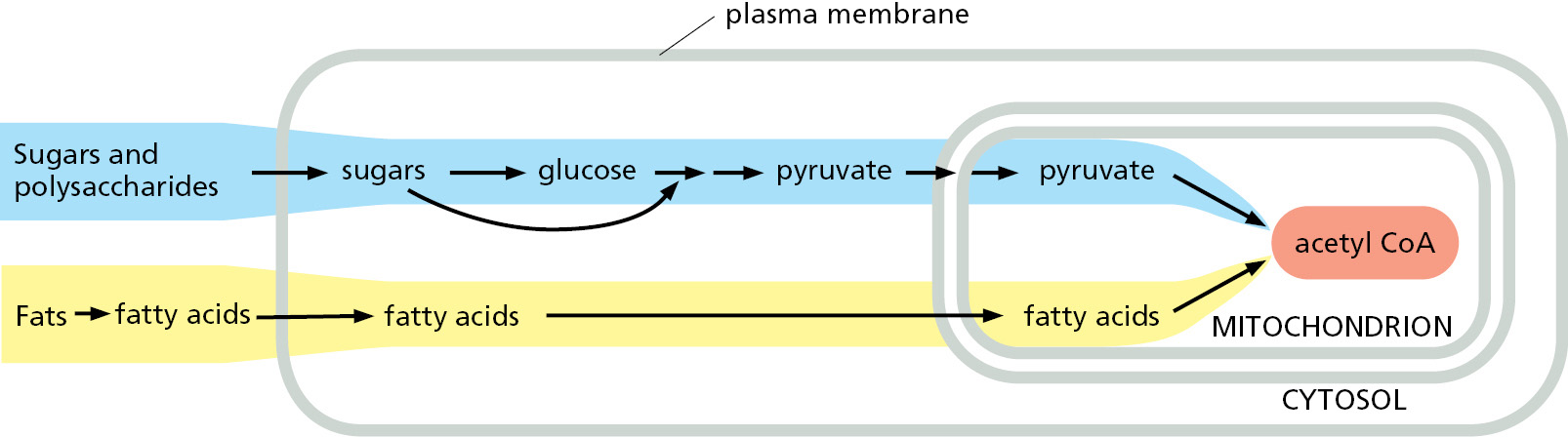
Sugars and Fats Are Both Degraded to Acetyl CoA in Mitochondria
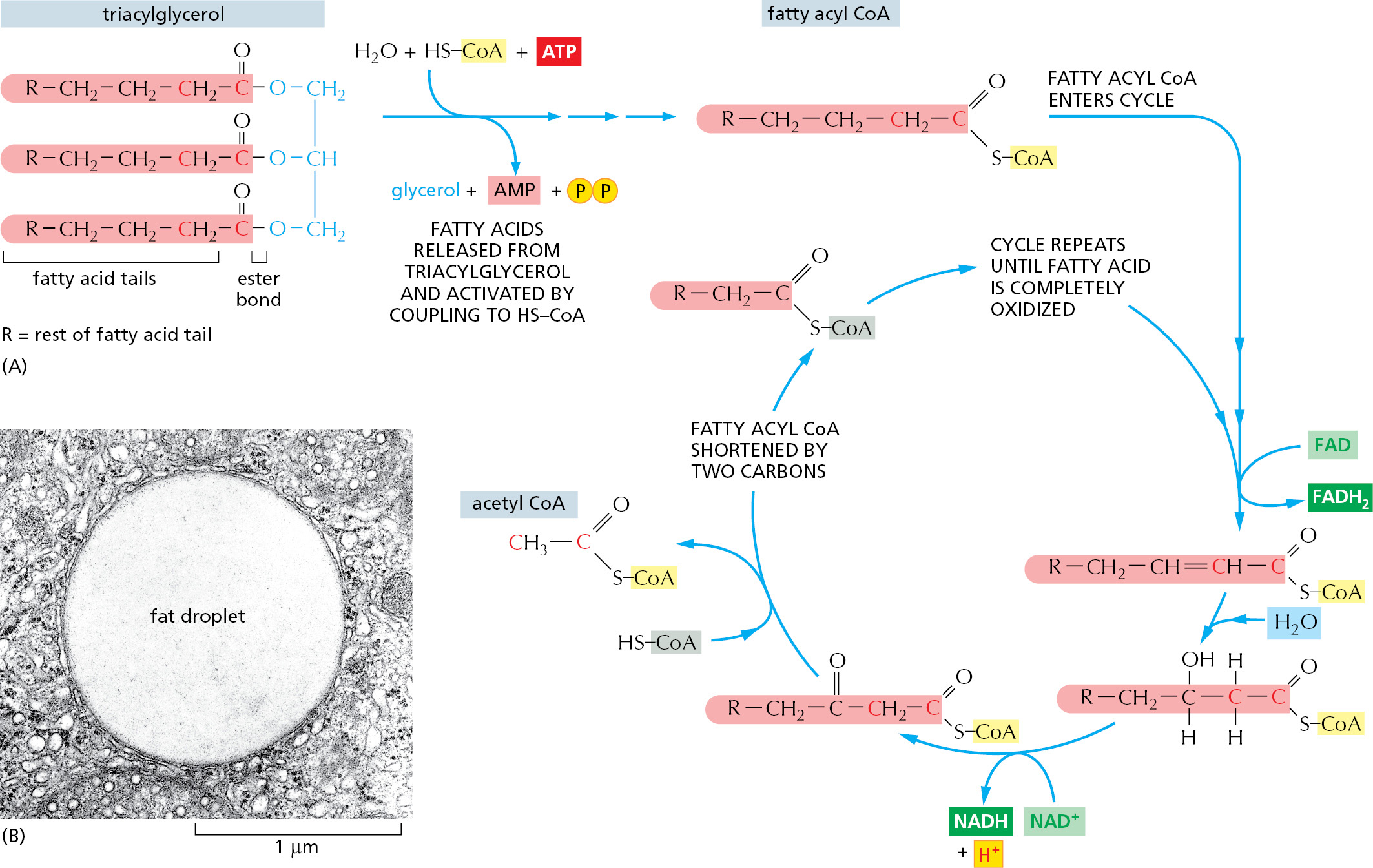
The fatty acids imported from the bloodstream are moved into mitochondria, where all of their oxidation takes place (Figure 2–56). Each molecule of fatty acid (as the activated molecule fatty acyl CoA) is broken down completely by a cycle of reactions that trims two carbons at a time from its carboxyl end, generating one molecule of acetyl CoA for each turn of the cycle. A molecule of NADH and a molecule of FADH2 are also produced in this process (Figure 2–57).
Figure 2–56Pathways for the production of acetyl CoA from sugars and fats. The mitochondrion in eukaryotic cells is where acetyl CoA is produced from both types of food molecules. It is therefore the place where most of the cell’s oxidation reactions occur and where most of its ATP is made. Amino acids (not shown) can also enter mitochondria to be converted there into acetyl CoA or another intermediate of the citric acid cycle. The structure and function of mitochondria are discussed in detail in Chapter 14.Figure 2–57How the oxidation of fatty acids produces acetyl CoA. (A) Fats are stored in the form of triacylglycerol, the glycerol portion of which is shown in blue. Three fatty acid chains (shaded in red) are linked to this glycerol through ester bonds that can be hydrolyzed by enzymes called lipases to allow the fatty acids to enter the bloodstream (see Figure 2–55). Once the fatty acids enter mitochondria (see Figure 2–56), they are coupled to coenzyme A in a reaction requiring ATP. These activated fatty acids (fatty acyl CoA molecules) are then oxidized in a cycle containing four enzymes, which are not shown. As indicated, each turn of the cycle shortens the fatty acyl CoA molecule by two carbons (red) and generates one molecule each of the energy-rich molecules FADH2, NADH, and acetyl CoA. (B) Fats are insoluble in water and spontaneously form large lipid droplets. This electron micrograph shows a lipid droplet in the cytoplasm of a specialized fat cell, an adipocyte. (B, courtesy of Daniel S. Friend and by permission of E.L. Bearer.)
As was shown in Figure 2–56, in eukaryotes the pyruvate that was produced by glycolysis from sugars in the cytosol is likewise transported into mitochondria, where it is rapidly decarboxylated by a giant complex of three enzymes, called the pyruvate dehydrogenase complex. The products are a molecule of CO2 (a waste product), a molecule of NADH, and acetyl CoA (see Panel 2–9, pp. 110–111).
Sugars and fats are the major energy sources for most nonphotosynthetic organisms, including humans. Most of the useful energy that can be extracted from their oxidation remains stored in the acetyl CoA molecules that are produced from both sources. In the citric acid cycle of reactions, the acetyl group (–COCH3) in acetyl CoA is completely oxidized to CO2 and H2O. This cycle, to be described next, therefore plays a critical, central role in the energy metabolism of aerobic organisms.
The Citric Acid Cycle Generates NADH by Oxidizing Acetyl Groups to CO2
In the nineteenth century, biologists noticed that in the absence of air, cells produce lactic acid (for example, in muscle) or ethanol (for example, in yeast), while in its presence they consume O2 and produce CO2 and H2O instead. Efforts to define the pathways of aerobic metabolism eventually focused on the oxidation of pyruvate and led in 1937 to the discovery of the citric acid cycle, also known as the tricarboxylic acid cycle or the Krebs cycle. The citric acid cycle accounts for about two-thirds of the total oxidation of carbon compounds in most cells, and its major end products are CO2 and high-energy electrons in the form of NADH. The CO2 is released as a waste product, while the high-energy electrons from NADH are passed to a membrane-bound electron-transport chain that will be discussed in Chapter 14, eventually combining with O2 to produce H2O.
The citric acid cycle itself does not use gaseous O2 (it uses oxygen atoms from H2O). But the cycle does require O2 in subsequent reactions to keep it going. This is because there is no other efficient way for the NADH to get rid of its electrons and thus regenerate the NAD+ that the cycle requires.
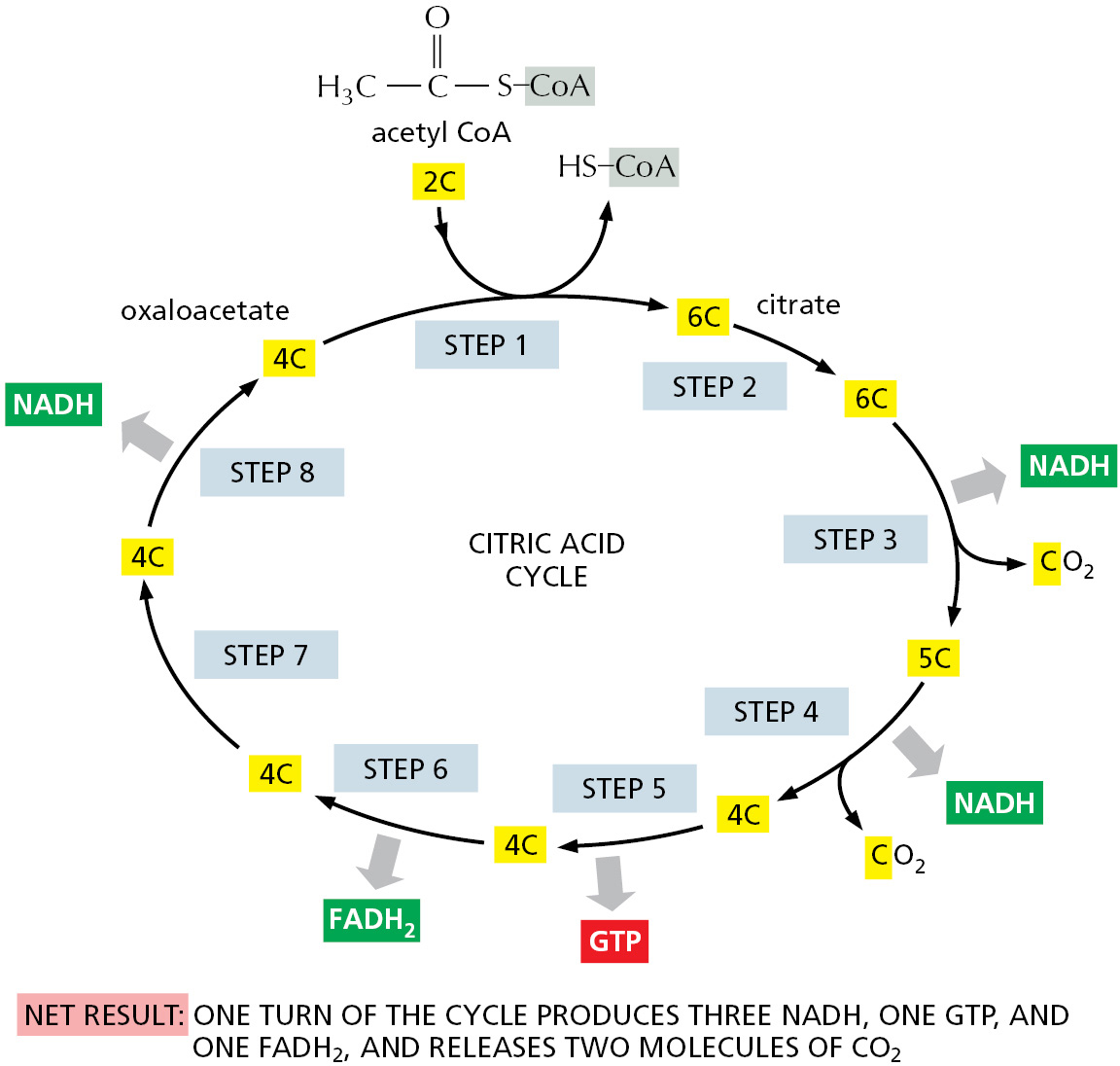
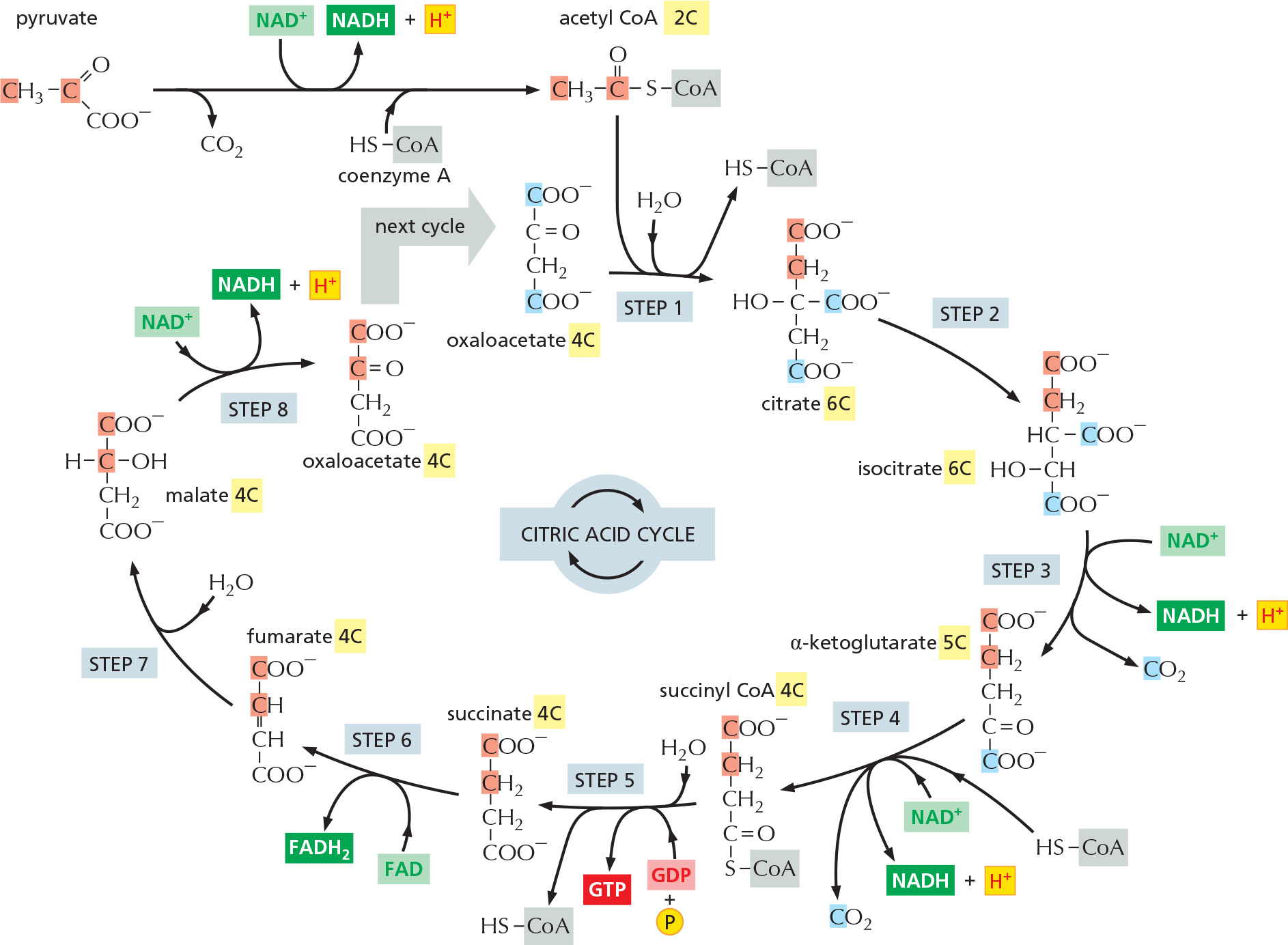
The citric acid cycle takes place inside mitochondria in eukaryotic cells. The process begins when the acetyl group is transferred from acetyl CoA to a four-carbon molecule, oxaloacetate, to form the six-carbon tricarboxylic acid, citric acid, for which the subsequent cycle of reactions is named. This citric acid molecule is then gradually oxidized, allowing the energy of oxidation to be harnessed to produce activated carrier molecules. The chain of eight reactions forms a cycle because at the end the oxaloacetate is regenerated to enter a new turn of the cycle, as shown in outline in Figure 2–58.
Figure 2–58Simple overview of the citric acid cycle. The reaction of acetyl CoA with oxaloacetate starts the cycle by producing citrate (citric acid). In each turn of the cycle, two molecules of CO2 are produced as waste products, plus three molecules of NADH, one molecule of GTP, and one molecule of FADH2. The number of carbon atoms in each intermediate is shown in a yellow box. For details, see Panel 2–9 (pp. 110–111).
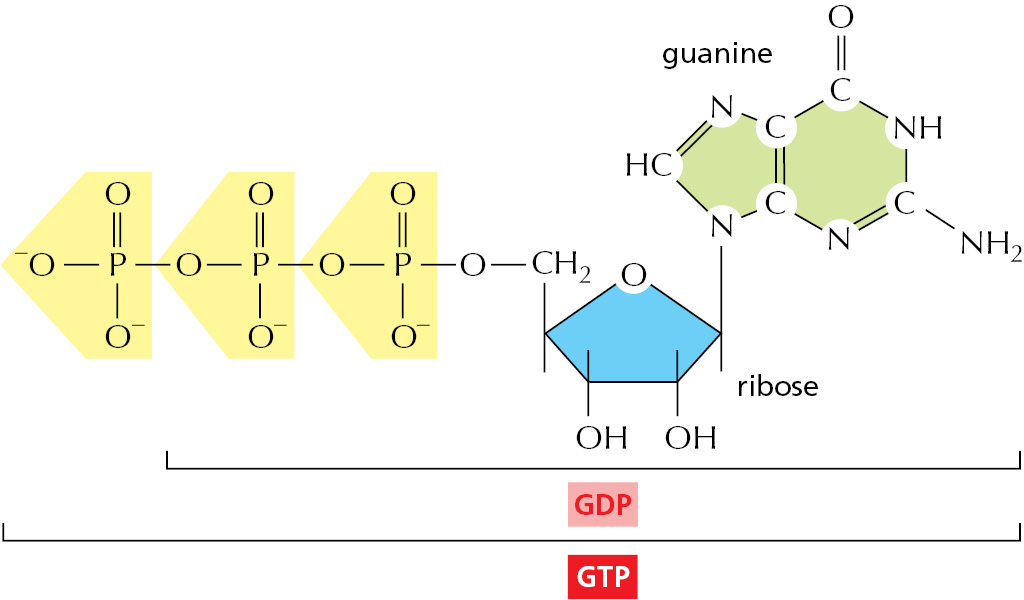
We have thus far highlighted only one of the three types of activated carrier molecules that are produced by the citric acid cycle: NADH, the reduced form of the NAD+/NADH electron carrier system (see Figure 2–36). In addition to three molecules of NADH, each turn of the cycle also produces one molecule of FADH2 from FAD (see Figure 2–39) and one molecule of GTP, guanosine triphosphate, from GDP. The structure of GTP is illustrated in Figure 2–59. GTP is a close relative of ATP, and the transfer of its terminal phosphate group to ADP produces one ATP molecule in each cycle.
Figure 2–59The structure of GTP, guanosine triphosphate. GTP and GDP are close relatives of ATP and ADP, respectively.
Panel 2–9 (pp. 110–111) and Movie 2.6 present the complete citric acid cycle. Water, rather than molecular oxygen, supplies the extra oxygen atoms required to make CO2 from the acetyl groups entering the citric acid cycle. As illustrated in the Panel, three molecules of water are taken up in each cycle, and the oxygen atoms of some of them are ultimately used to make CO2.
In addition to pyruvate and fatty acids, some amino acids pass from the cytosol into mitochondria, where they are also converted into acetyl CoA or one of the other intermediates of the citric acid cycle. As we discuss next, in mitochondria the large amount of energy stored in the electrons of NADH and FADH2 is utilized for ATP production through the process of oxidative phosphorylation, which is the only step in the oxidative catabolism of foodstuffs that directly requires gaseous oxygen (O2) from the atmosphere. Thus, in the eukaryotic cell, the mitochondrion is the center toward which all energy-yielding processes lead, whether they begin with sugars, fats, or proteins.
Electron Transport Drives the Synthesis of the Majority of the ATP in Most Cells
Most chemical energy is released in the last stage in the degradation of a food molecule. This process begins when NADH and FADH2 transfer the electrons that they obtained by oxidizing food-derived organic molecules to an electron-transport chain embedded in the inner membrane of the mitochondrion. As the electrons pass along this long chain of specialized electron acceptor and donor molecules, they fall to successively lower energy states, being finally passed to molecules of oxygen gas (O2) that have diffused into the mitochondrion, reducing the oxygen to produce water. The electrons have now reached a very low energy level, and all the available energy has been extracted from the oxidized food molecule.
The energy released by this chain of electron transfers is used to pump H+ ions (protons) across the membrane—from the innermost mitochondrial compartment (the matrix) to the intermembrane space (and then to the cytosol). The resulting electrochemical proton gradient across the inner mitochondrial membrane serves as a major source of energy for cells, being tapped like a battery to drive a variety of energy-requiring reactions. The most prominent of these reactions is the generation of ATP by the phosphorylation of ADP, as part of a process known as oxidative phosphorylation (see Figure 14–12). This harnessing of chemical energy through membrane-based electron transfers is one of the most remarkable achievements of cell evolution—as such, we shall devote an entire chapter to it (Chapter 14).
Many Biosynthetic Pathways Begin with Glycolysis or the Citric Acid Cycle
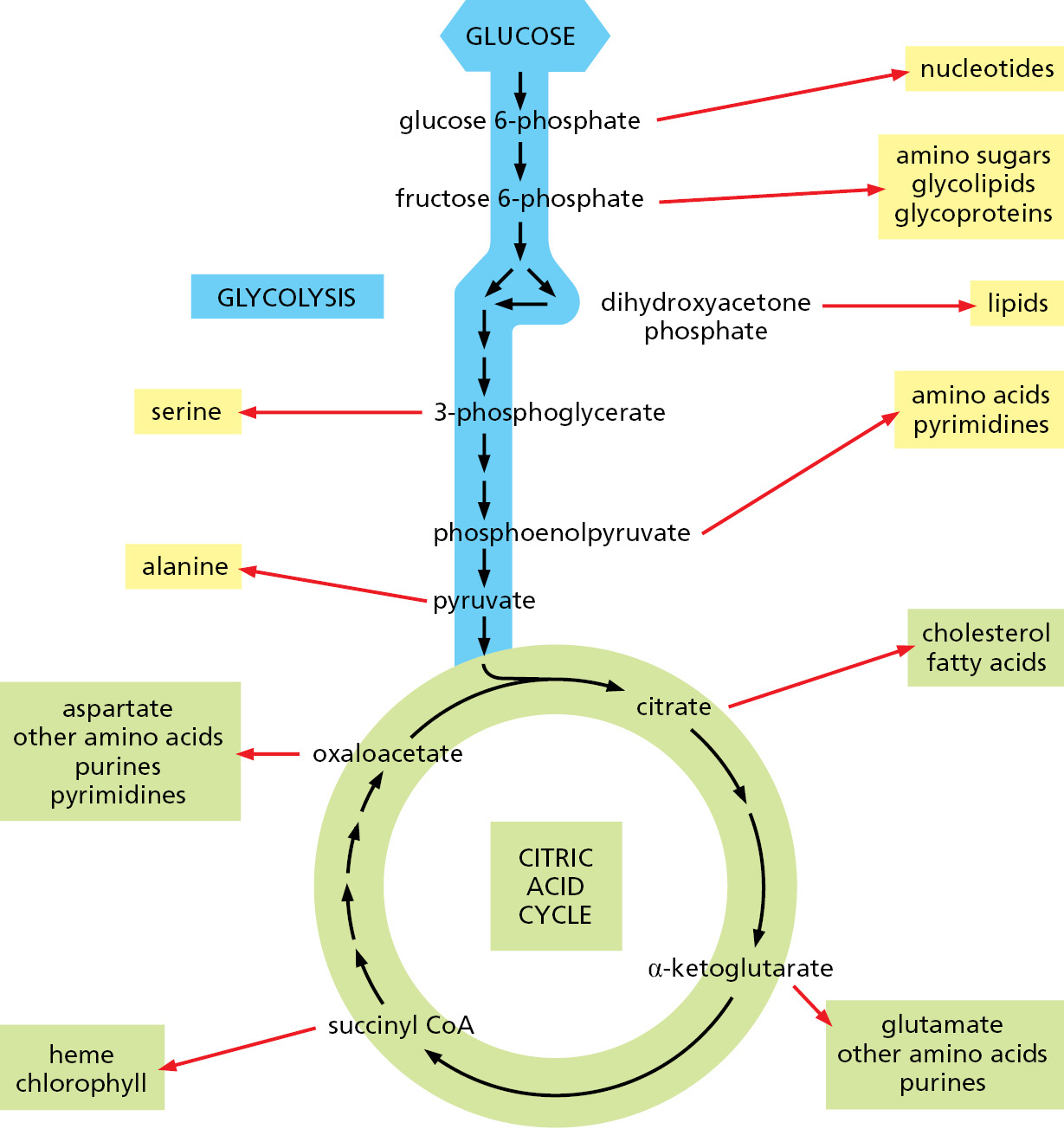
Catabolic reactions, such as those of glycolysis and the citric acid cycle, produce both energy for the cell and the building blocks from which many other organic molecules are made. Thus far, we have emphasized energy production rather than the provision of starting materials for biosynthesis. But many of the intermediates formed in glycolysis and the citric acid cycle are siphoned off by such anabolic pathways, in which the intermediates are converted by a series of enzyme-catalyzed reactions into amino acids, nucleotides, lipids, and other small organic molecules that the cell needs. The oxaloacetate and α-ketoglutarate produced during the citric acid cycle, for example (see Panel 2–9, pp. 110–111), are transferred from the mitochondrial matrix back to the cytosol, where they serve as precursors for the production of many essential molecules, such as the amino acids aspartate and glutamate, respectively. An idea of the extent of these anabolic pathways can be gathered from Figure 2–60, which illustrates some of the branches leading from the central catabolic reactions to biosyntheses.
Figure 2–60Glycolysis and the citric acid cycle provide the precursors needed to synthesize many important biological molecules. The amino acids, nucleotides, lipids, sugars, and other molecules—shown here as products—in turn serve as the precursors for the many macromolecules of the cell. Each black arrow in this diagram denotes a single enzyme-catalyzed reaction; the red arrows generally represent pathways with many steps that are required to produce the indicated products.
Animals Must Obtain All the Nitrogen and Sulfur They Need from Food
So far we have concentrated mainly on carbohydrate metabolism and have not yet considered the metabolism of nitrogen or sulfur. These two elements are important constituents of biological macromolecules. Nitrogen and sulfur atoms pass from compound to compound and between organisms and their environment in a series of reversible cycles.
Although molecular nitrogen constitutes nearly 80% of Earth’s atmosphere, nitrogen is chemically unreactive as a gas. Only a few living species are able to incorporate it into organic molecules, a process called nitrogen fixation. Nitrogen fixation occurs both in certain microorganisms and by some geophysical processes, such as lightning discharge. It is essential to the biosphere as a whole, for without it life could not exist on this planet. Only a small fraction of the nitrogenous compounds in today’s organisms, however, is due to fresh products of nitrogen fixation from the atmosphere. Most organic nitrogen has been in circulation for some time, passing from one living organism to another. Thus, present-day nitrogen-fixing reactions can be said to perform a “topping-up” function for the total nitrogen supply.
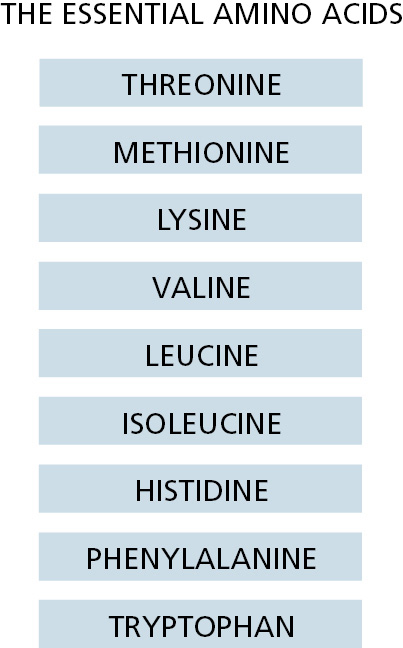
Figure 2–61The nine essential amino acids. These cannot be synthesized by human cells and so must be supplied in the diet.
Vertebrates receive virtually all of their nitrogen from their dietary intake of proteins and nucleic acids. In the body, these macromolecules are broken down to amino acids and the components of nucleotides, and the nitrogen they contain is used to produce new proteins and nucleic acids—or other molecules. About half of the 20 amino acids found in proteins are essential amino acids for vertebrates (Figure 2–61), which means that they cannot be synthesized from other ingredients of the diet. The other amino acids can be so synthesized, using a variety of raw materials that include the intermediates of the citric acid cycle just described. The essential amino acids are made by plants and other organisms, usually by long and energetically expensive pathways that have been lost in the course of vertebrate evolution.
The nucleotides needed to make RNA and DNA are synthesized using specialized biosynthetic pathways. All of the nitrogens in the purine and pyrimidine bases (as well as some of the carbons) are derived from the plentiful amino acids glutamine, aspartic acid, and glycine, whereas the ribose and deoxyribose sugars are derived from glucose. There are no “essential nucleotides” that must be provided in the diet.
As we have seen, the amino acids derived from food that are not used in biosynthesis can be oxidized to generate metabolic energy. Most of their carbon and hydrogen atoms eventually form CO2 or H2O, whereas their nitrogen atoms are shuttled through various forms and eventually appear as urea, which is excreted. Each amino acid is processed differently, and a whole constellation of enzymatic reactions exists for their catabolism.
Sulfur is abundant on Earth in its most oxidized form, sulfate (SO42–). To be useful for life, sulfate must be reduced to sulfide (S2–), the oxidation state of sulfur required for the synthesis of essential biological molecules, including the amino acids methionine and cysteine, coenzyme A, and the iron–sulfur centers essential for electron transport. The sulfur-reduction process begins in bacteria, fungi, and plants, where a special group of enzymes use ATP and reducing power to create a sulfate assimilation pathway. Humans and other animals cannot reduce sulfate and must therefore acquire the sulfur they need for their metabolism in the food that they eat.
Metabolism Is Highly Organized and Regulated
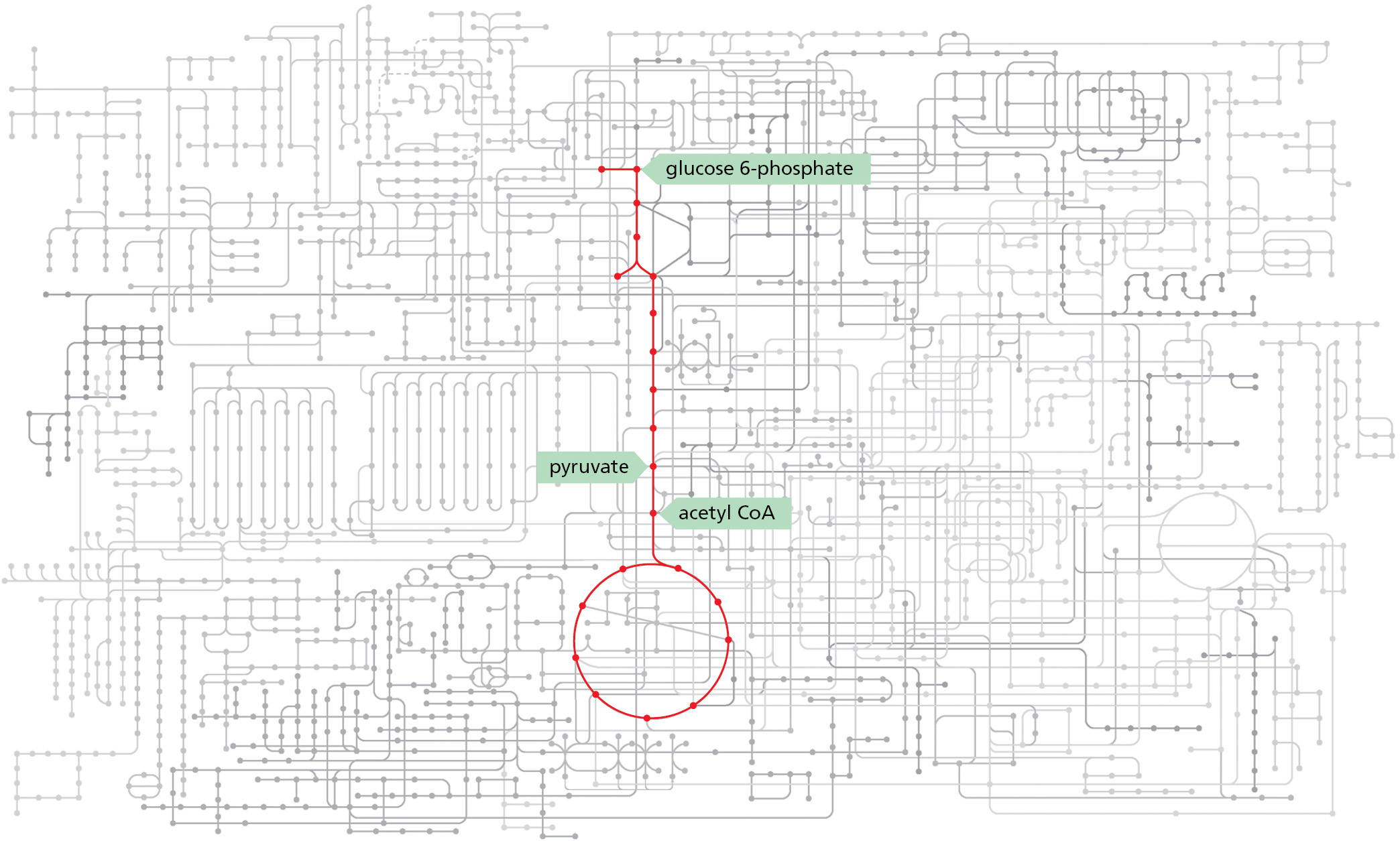
One can get a sense of the intricacy of a cell as a chemical machine from the relation of glycolysis and the citric acid cycle to the other metabolic pathways sketched out in Figure 2–62. This diagram represents only some of the enzymatic pathways in a human cell. It is obvious that our discussion of cell metabolism has dealt with only a tiny fraction of the broad field of cell chemistry.
Figure 2–62Glycolysis and the citric acid cycle are at the center of an elaborate set of metabolic pathways in human cells. Some 2000 metabolic reactions are shown schematically with the reactions of glycolysis and the citric acid cycle in red. Many other reactions either lead into these two central pathways—delivering small molecules to be catabolized with production of energy—or they lead outward as in Figure 2–60 to supply carbon compounds for the purpose of biosynthesis. (Adapted from KEGG Database. With permission from Kanehisa Laboratories.)
All these reactions occur in a cell that is less than 0.1 mm in diameter, and each requires a different enzyme. The same molecule can often be part of many different pathways. Pyruvate, for example, is a substrate for half a dozen or more different enzymes, each of which modifies it chemically in a different way. One enzyme converts pyruvate to acetyl CoA, another to oxaloacetate; a third enzyme changes pyruvate to the amino acid alanine, a fourth to lactate, and so on. All of these different pathways compete for the same pyruvate molecule, and similar competitions for thousands of other small molecules go on at the same time.
The situation is further complicated in a multicellular organism. Different cell types require somewhat different sets of enzymes. And different tissues make distinct contributions to the chemistry of the organism as a whole. All types of cells have their distinctive metabolic traits, and they cooperate extensively in the normal state, as well as in response to stress and starvation. One might think that the whole system would need to be so finely balanced that any minor upset, such as a temporary change in dietary intake, would be disastrous.
In fact, the metabolic balance of a cell is amazingly stable. Whenever the balance is perturbed, the cell reacts so as to restore the initial state. The cell can adapt and continue to function during starvation or disease. Mutations of many kinds can damage or even eliminate particular reaction pathways, and yet—provided that certain minimum requirements are met—the cell survives. It does so because an elaborate network of control mechanisms regulates and coordinates the rates of all of its reactions. These controls rest, ultimately, on the remarkable abilities of proteins to change their shape and their chemistry in response to changes in their immediate environment.
The principles that underlie how proteins are built and the chemistry behind their regulation are clearly central to all of biology. And it is proteins that will be our next concern.
Summary
Food molecules are broken down by controlled stepwise oxidation to provide chemical energy in the form of ATP and NADH. Following the breakdown of large food molecules to their simple subunits, three main sets of reactions act in series, the products of each being the starting material for the next: glycolysis (which occurs in the cytosol), the citric acid cycle (in the mitochondrial matrix), and oxidative phosphorylation (on the inner mitochondrial membrane). The intermediate products of glycolysis and the citric acid cycle are used both as sources of metabolic energy and to produce many of the small molecules used as the raw materials for biosynthesis. Cells store sugar molecules as glycogen in animals and starch in plants; both plants and animals also use fats extensively as a food store. These storage materials in turn serve as a major source of food for humans, along with the proteins that comprise the majority of the dry mass of most of the cells in the foods we eat.
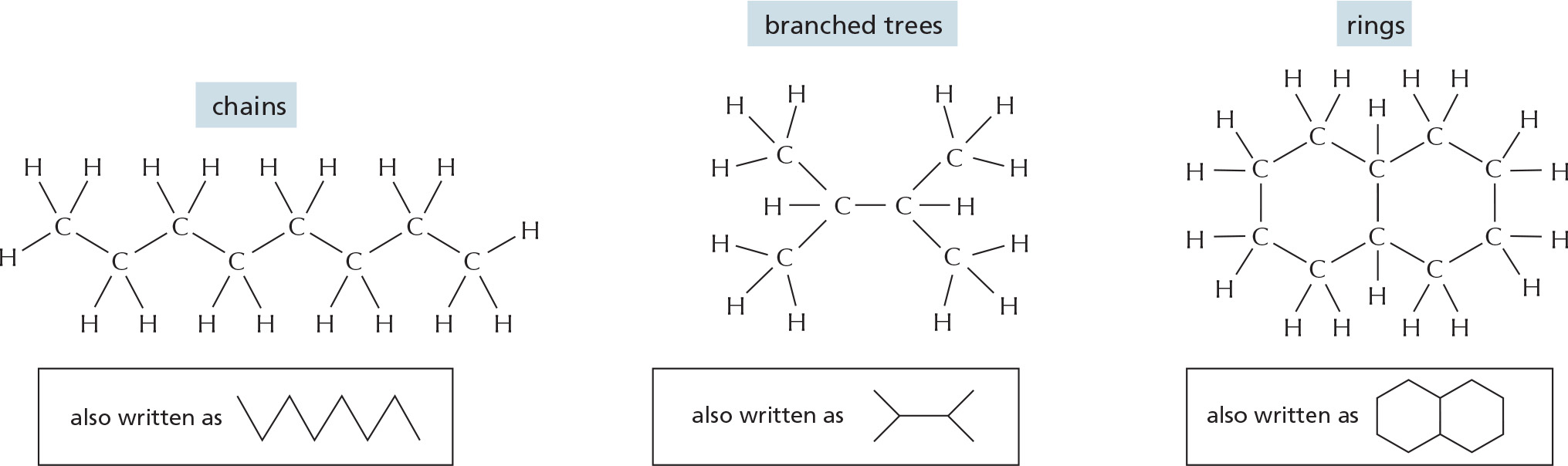
PANEL 2–1: Chemical Bonds and Groups Commonly Encountered in Biological Molecules
CARBON SKELETONS
Carbon has a unique role in the cell because of its ability to form strong covalent bonds with other carbon atoms. Thus carbon atoms can join to form:
COVALENT BONDS
A covalent bond forms when two atoms come very close together and share one or more of their outer-shell electrons. Each atom forms a fixed number of covalent bonds in a defined spatial arrangement.
SINGLE BONDS: two electrons shared per bond
DOUBLE BONDS: four electrons shared per bond
The precise spatial arrangement of covalent bonds influences the three-dimensional structure and chemistry of molecules.
In this review Panel, we see how covalent bonds are used in a variety of biological molecules.
Atoms joined by two or more covalent bonds cannot rotate freely around the bond axis. This restriction has a major influence on the three-dimensional shape of many macromolecules.
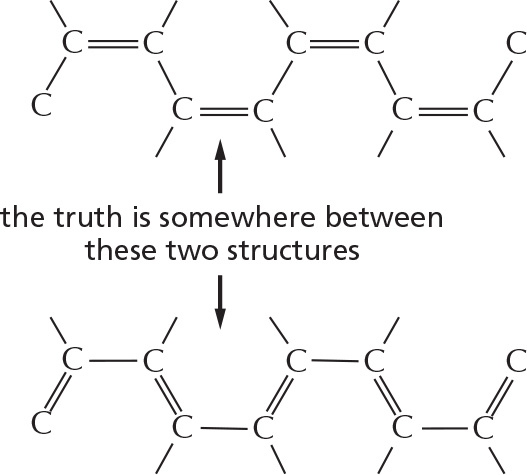
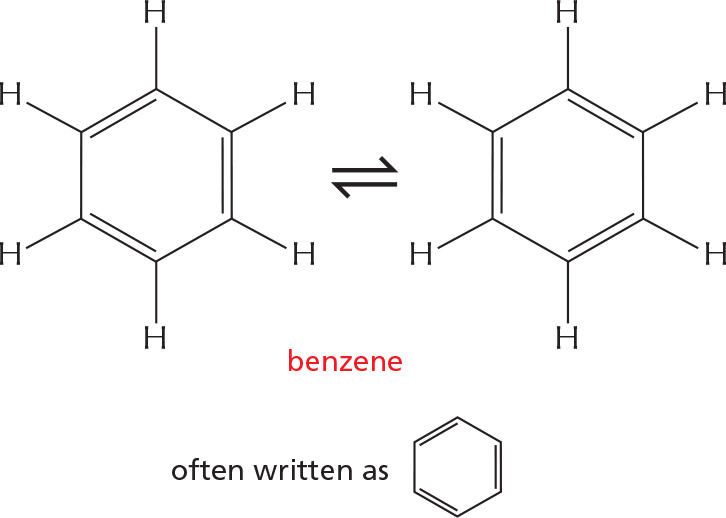
ALTERNATING DOUBLE BONDS
A carbon chain can include double bonds. If these are on alternate carbon atoms, the bonding electrons move within the molecule, stabilizing the structure by a phenomenon called resonance.
Alternating double bonds in a ring can generate a very stable structure.
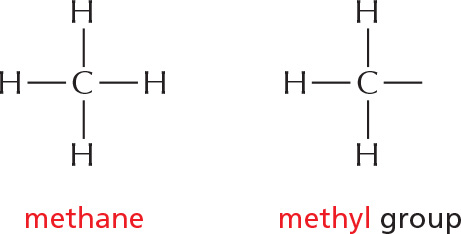
C–H COMPOUNDS
Carbon and hydrogen together make stable compounds (or groups) called hydrocarbons. These are nonpolar, do not form hydrogen bonds, and are generally insoluble in water.
part of the hydrocarbon "tail" of a fatty acid molecule
C–O COMPOUNDS
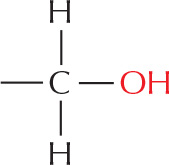
Many biological compounds contain a carbon covalently bonded to an oxygen. For example,
alcohol
The –OH is called a hydroxyl group.
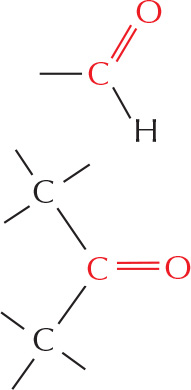
aldehyde
The C═O is called a carbonyl group.
ketone
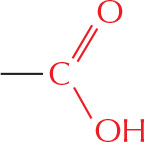
carboxylic acid
The –COOH is called a carboxyl group. In water, this loses an H+ ion to become –COO–.
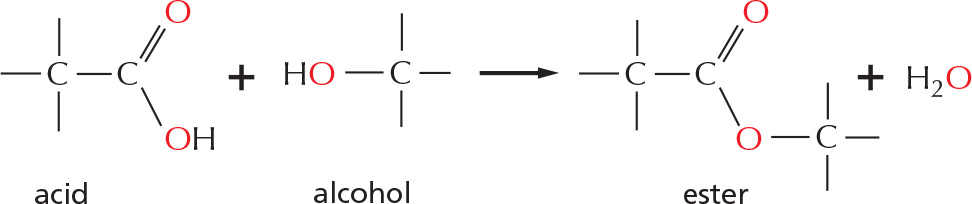
esters
Esters are formed by combining an acid and an alcohol.
C–N COMPOUNDS
Amines and amides are two important examples of compounds containing a carbon linked to a nitrogen.
Amines in water combine with an H+ ion to become positively charged.
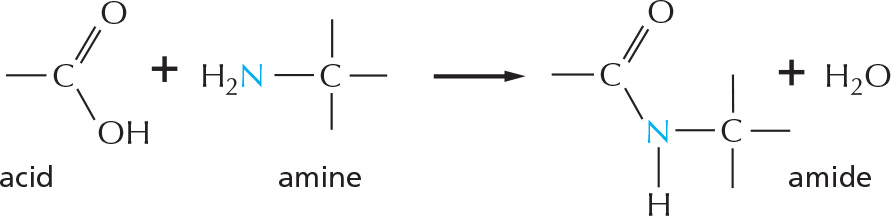
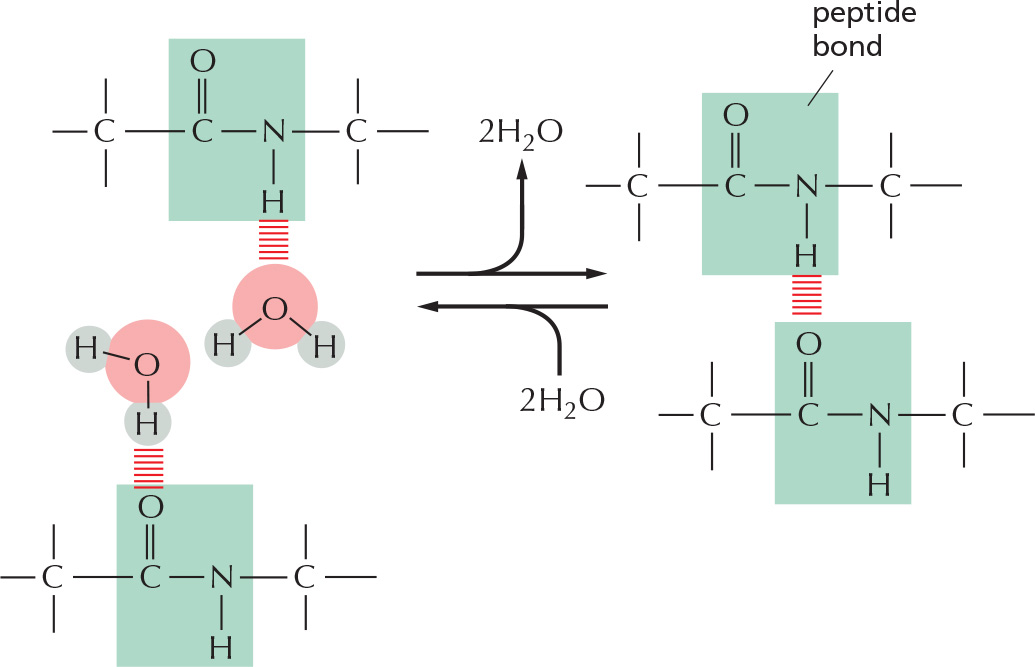
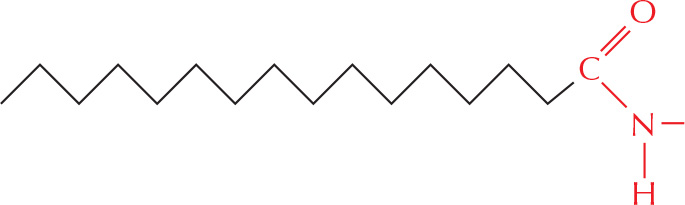
Amides are formed by combining an acid and an amine. Unlike amines, amides are uncharged in water. An example is the peptide bond that joins amino acids in a protein.
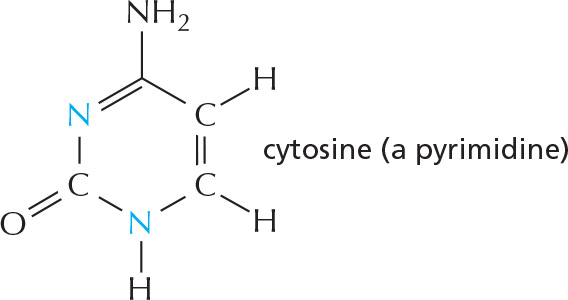
Nitrogen also occurs in several ring compounds, including important constituents of nucleic acids: purines and pyrimidines.
SULFHYDRYL GROUP
The is called a sulfhydryl group. In the amino acid cysteine, the sulfhydryl group may exist in the reduced form or more rarely in an oxidized, cross-bridging form
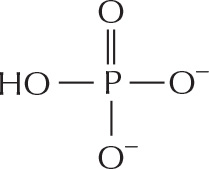
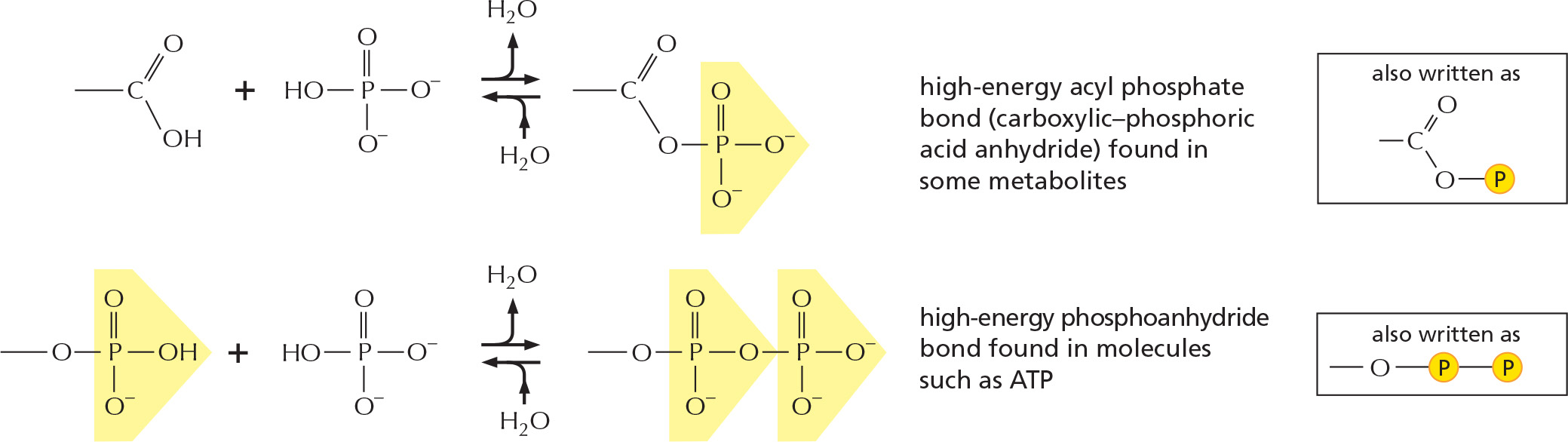
PHOSPHATES
Inorganic phosphate is a stable ion formed from phosphoric acid, H3PO4. It is also written as .
Phosphate esters can form between a phosphate and a free hydroxyl group. Phosphate groups are often covalently attached to proteins in this way.
The combination of a phosphate and a carboxyl group, or two or more phosphate groups, produces an acid anhydride. Because compounds of this type release a large amount of free energy when the bond is broken by hydrolysis in the cell, they are often said to contain a high-energy bond.
PANEL 2–2: Water and Its Influence on the Behavior of Biological Molecules
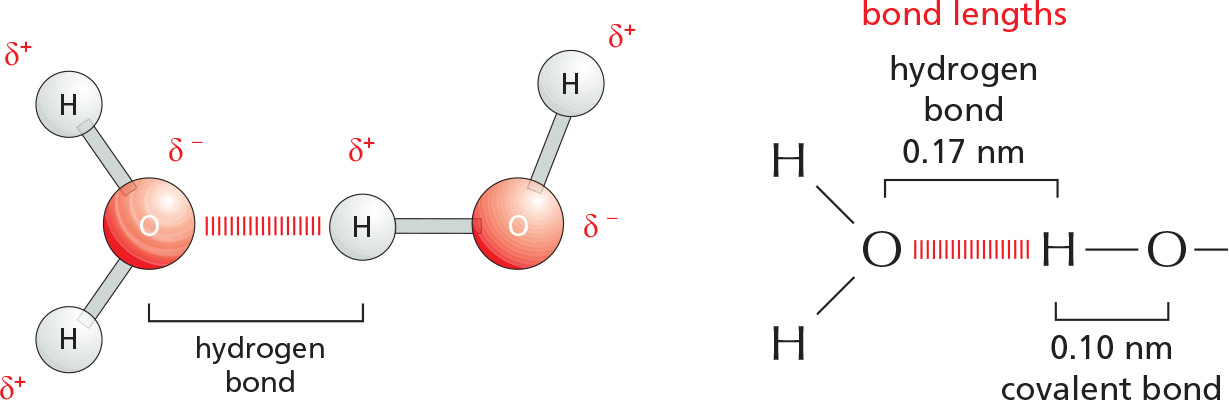
HYDROGEN BONDS
Because they are polarized, two adjacent H2O molecules can form a noncovalent linkage known as a hydrogen bond. Hydrogen bonds have only about 1/20 the strength of a covalent bond.
Hydrogen bonds are strongest when the three atoms lie in a straight line.
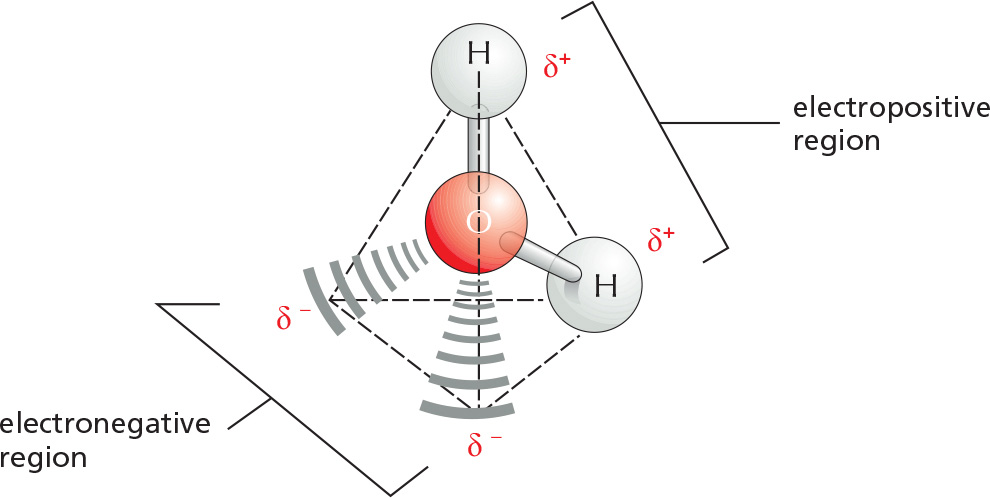
WATER
Two atoms connected by a covalent bond may exert different attractions for the electrons of the bond. In such cases, the bond is polar, with one end slightly negatively charged (δ–) and the other slightly positively charged (δ+).
Although a water molecule has an overall neutral charge (having the same number of electrons and protons), the electrons are asymmetrically distributed, making the molecule polar. The oxygen nucleus draws electrons away from the hydrogen nuclei, leaving the hydrogen nuclei with a small net positive charge. The excess of electron density on the oxygen atom creates weakly negative regions at the other two corners of an imaginary tetrahedron. On these pages, we review the chemical properties of water and see how water influences the behavior of biological molecules.
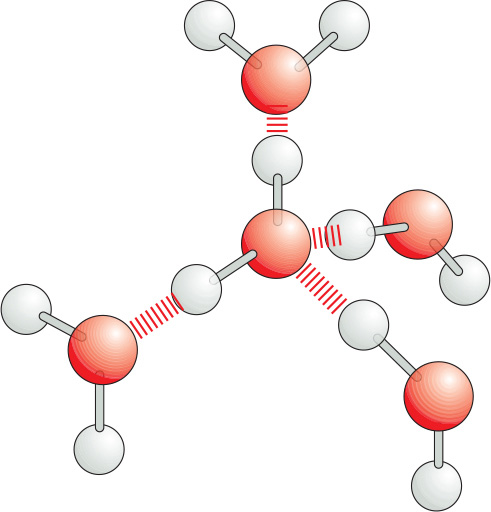
WATER STRUCTURE
Molecules of water join together transiently in a hydrogen-bonded lattice. Even at 37°C, 15% of the water molecules are joined to four others in a short-lived assembly known as a flickering cluster.
The cohesive nature of water is responsible for many of its unusual properties, such as high surface tension, high specific heat capacity, and high heat of vaporization.
HYDROPHILIC MOLECULES
Substances that dissolve readily in water are termed hydrophilic. They include ions and polar molecules that attract water molecules through electrical charge effects. Water molecules surround each ion or polar molecule and carry it into solution.
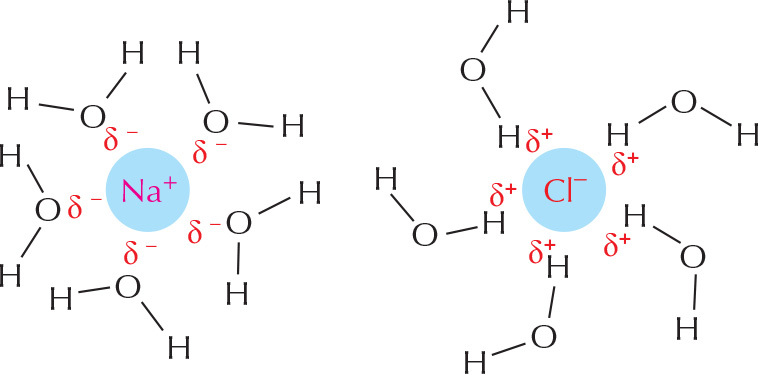
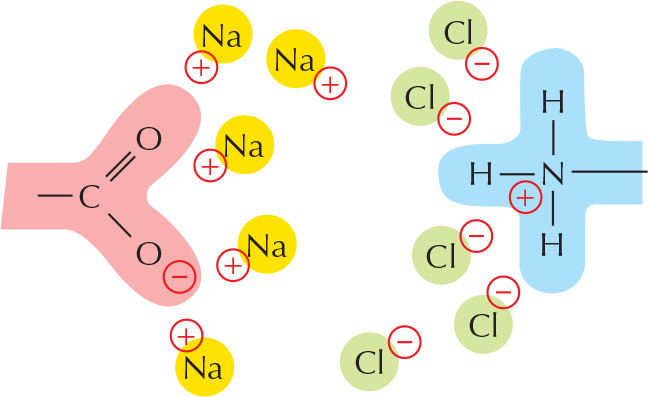
Ionic substances such as sodium chloride dissolve because water molecules are attracted to the positive (Na+) or negative (Cl–) charge of each ion.
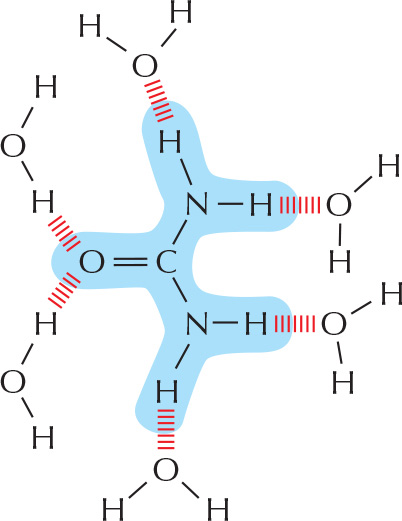
Polar substances such as urea dissolve because their molecules form hydrogen bonds with the surrounding water molecules.
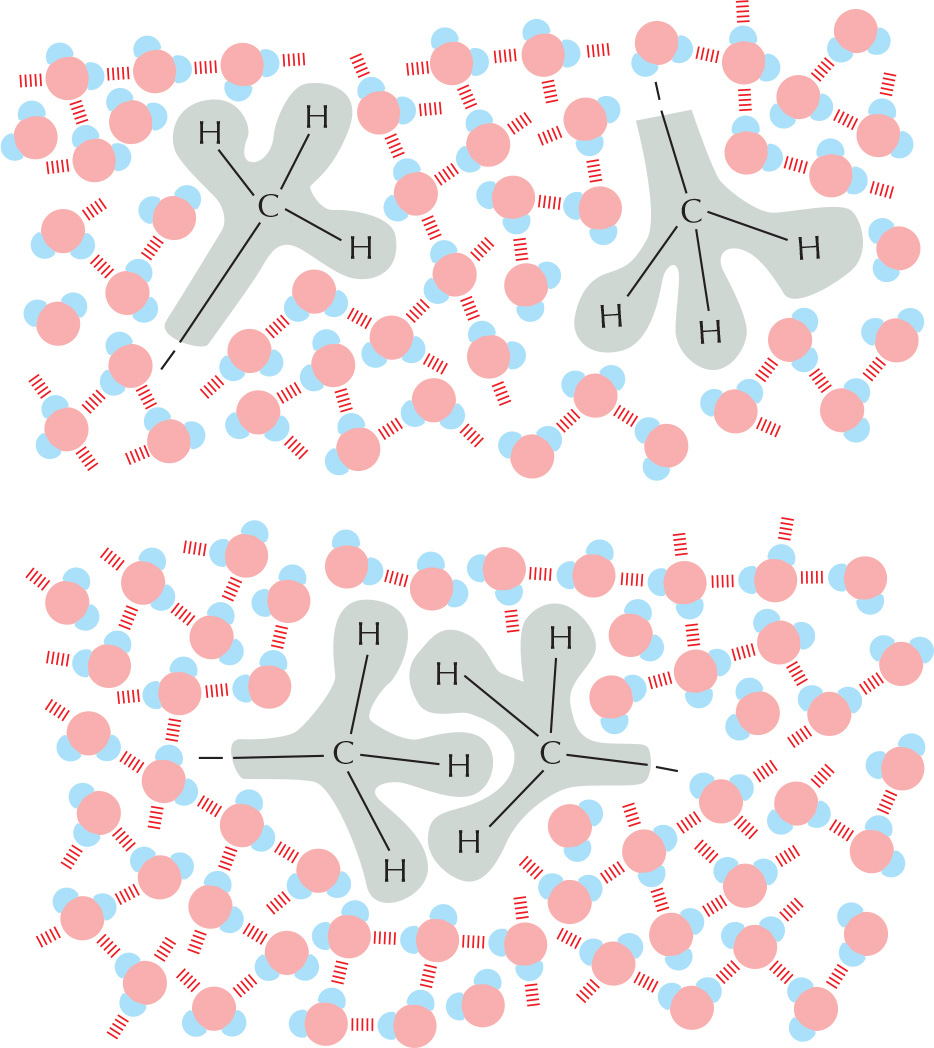
HYDROPHOBIC MOLECULES
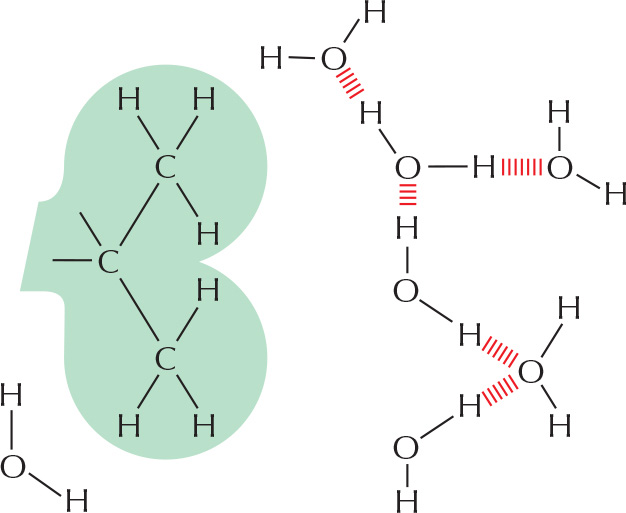
Substances that contain a preponderance of nonpolar bonds are usually insoluble in water and are termed hydrophobic. Water molecules are not attracted to such hydrophobic molecules and so have little tendency to surround them and bring them into solution.
Hydrocarbons, which contain many C–H bonds, are especially hydrophobic.
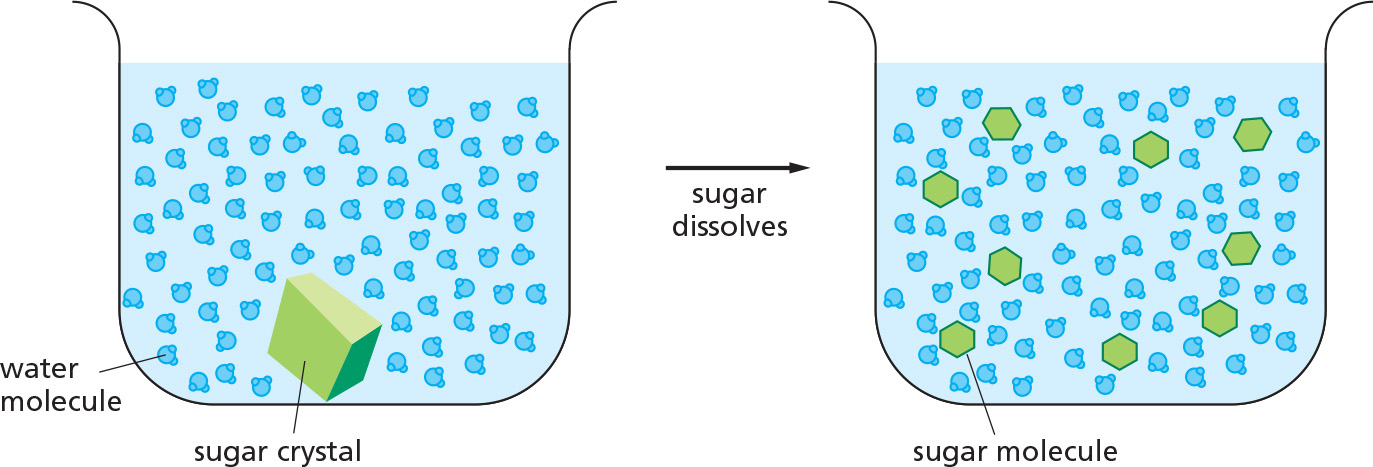
WATER AS A SOLVENT
Many substances, such as household sugar (sucrose), dissolve in water. That is, their molecules separate from each other, each becoming surrounded by water molecules.
When a substance dissolves in a liquid, the mixture is termed a solution. The dissolved substance (in this case sugar) is the solute, and the liquid that does the dissolving (in this case water) is the solvent. Water is an excellent solvent for hydrophilic substances because of its polar bonds.
ACIDS
Substances that release hydrogen ions (protons) into solution are called acids.
Many of the acids important in the cell are not completely dissociated, and they are therefore weak acids; for example, the carboxyl group (–COOH), which dissociates to give a hydrogen ion in solution.
Note that this is a reversible reaction.
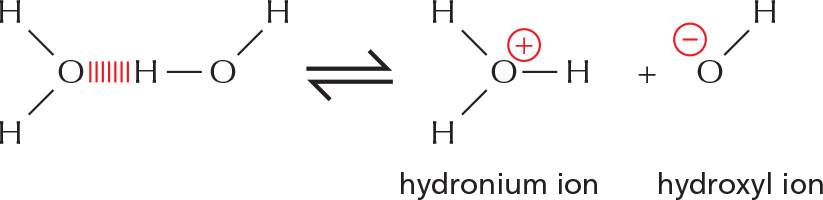
HYDROGEN ION EXCHANGE
Positively charged hydrogen ions (H+) can spontaneously move from one water molecule to another, thereby creating two ionic species.
often written as:
Because the process is rapidly reversible, hydrogen ions are continually shuttling between water molecules. Pure water contains equal concentrations of hydronium ions and hydroxyl ions (both 10–7 M).
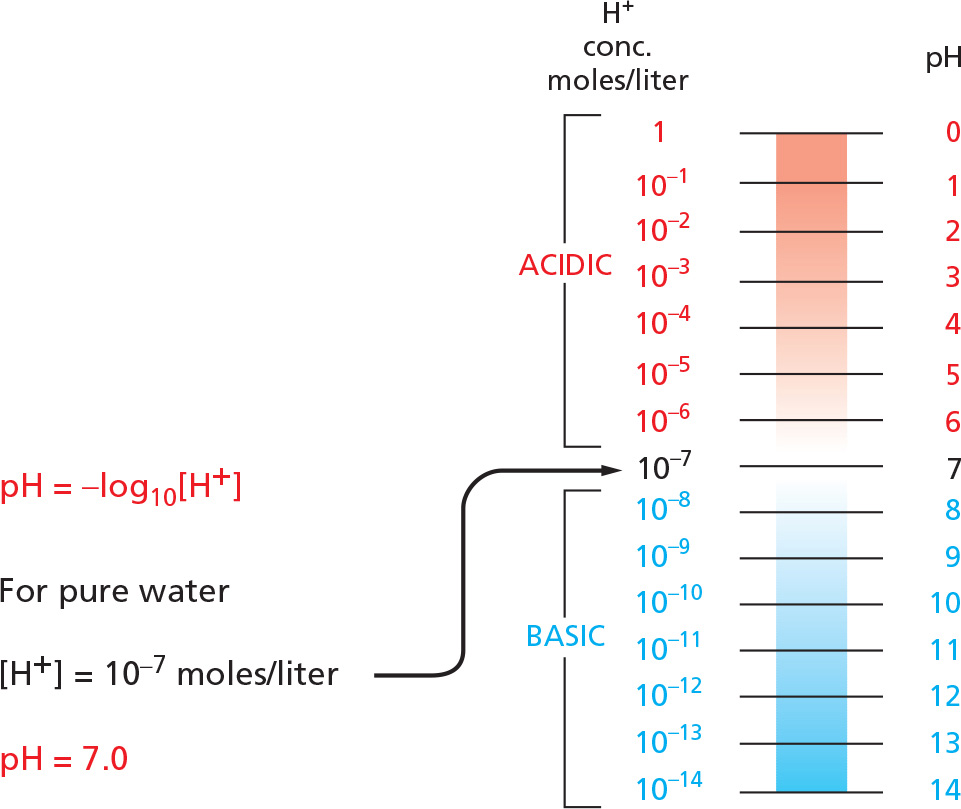
pH
The acidity of a solution is defined by the concentration (conc.) of hydronium ions (H3O+) it possesses, generally abbreviated as H+. For convenience, we use the pH scale, where
BASES
Substances that reduce the number of hydrogen ions in solution are called bases. Some bases, such as ammonia, combine directly with hydrogen ions.
Other bases, such as sodium hydroxide, reduce the number of H+ ions indirectly, by producing OH– ions that then combine directly with H+ ions to make H2O.
Many bases found in cells are partially associated with H+ ions and are termed weak bases. This is true of compounds that contain an amino group (–NH2), which has a weak tendency to reversibly accept an H+ ion from water, thereby increasing the concentration of free OH– ions.
PANEL 2–3: The Principal Types of Weak Noncovalent Bonds That Hold Macromolecules Together
WEAK NONCOVALENT CHEMICAL BONDS
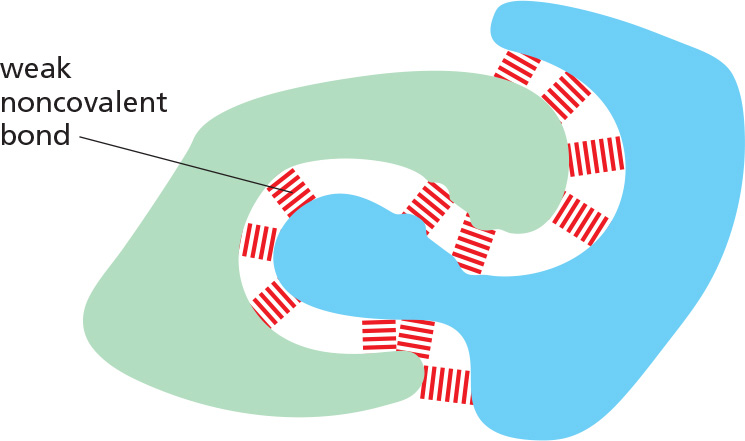
Organic molecules can interact with other molecules through three types of short-range attractive forces known as noncovalent bonds: van der Waals attractions, electrostatic attractions, and hydrogen bonds. The repulsion of hydrophobic groups from water is also important for these interactions and for the folding of biological macromolecules.
Weak noncovalent bonds have less than 1/20 the strength of a strong covalent bond. They are strong enough to provide tight binding only when many of them are formed simultaneously.
VAN DER WAALS ATTRACTIONS
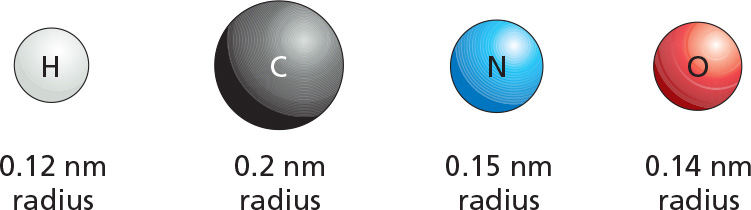
If two atoms are too close together, they repel each other very strongly. For this reason, an atom can often be treated as a sphere with a fixed radius. The characteristic “size" for each atom is specified by a unique van der Waals radius. The contact distance between any two noncovalently bonded atoms is the sum of their van der Waals radii.
At very short distances, any two atoms show a weak bonding interaction due to their fluctuating electrical charges. The two atoms will be attracted to each other in this way until the distance between their nuclei is approximately equal to the sum of their van der Waals radii. Although they are individually very weak, such van der Waals attractions can become important when two macromolecular surfaces fit together very closely, because many atoms are involved.
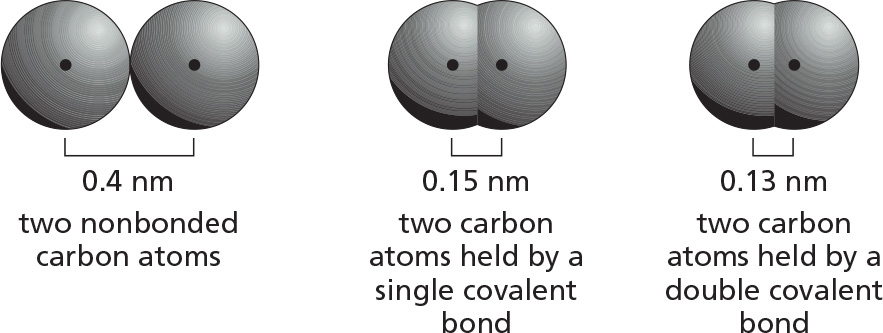
Note that when two atoms form a covalent bond, the centers of the two atoms (the two atomic nuclei) are much closer together than the sum of the two van der Waals radii. Thus,
HYDROGEN BONDS
As already described for water (see Panel 2-2, pp. 96-97), hydrogen bonds form when a hydrogen atom is “sandwiched" between two electron-attracting atoms (usually oxygen or nitrogen).
Hydrogen bonds are strongest when the three atoms are in a straight line:
Examples in macromolecules:
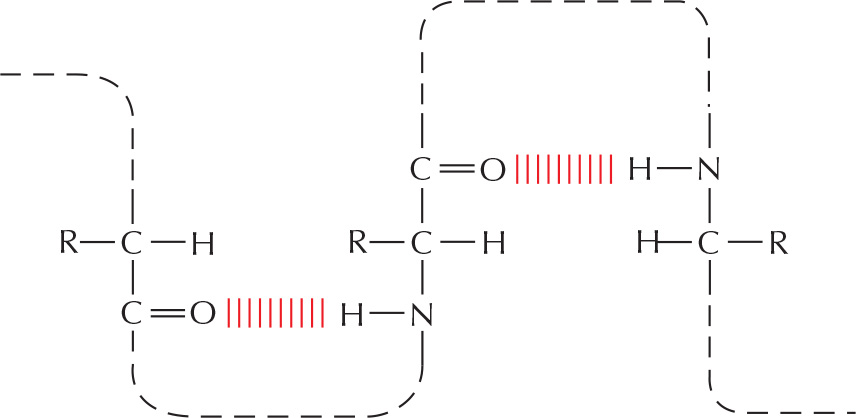
Amino acids in a polypeptide chain can be hydrogen-bonded together in a folded protein.
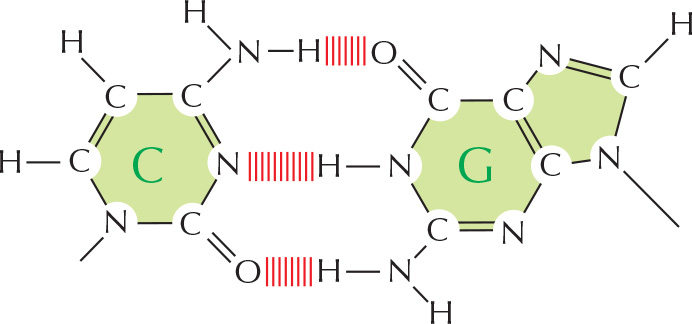
Two bases, G and C, are hydrogen bonded in a DNA double helix.
HYDROGEN BONDS IN WATER
Any two atoms that can form hydrogen bonds to each other can alternatively form hydrogen bonds to water molecules. Because of this competition with water molecules, the hydrogen bonds formed in water between two peptide bonds, for example, are relatively weak.
ELECTROSTATIC ATTRACTIONS
Electrostatic attractions occur both between fully charged groups (ionic bond) and between partially charged groups on polar molecules.
The force of attraction between the two partial charges, δ+ and δ–, falls off rapidly as the distance between the charges increases.
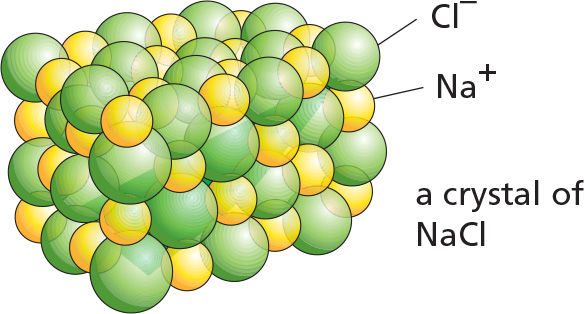
In the absence of water, ionic bonds are very strong. They are responsible for the strength of such minerals as marble and agate and for crystal formation in common table salt, NaCl.
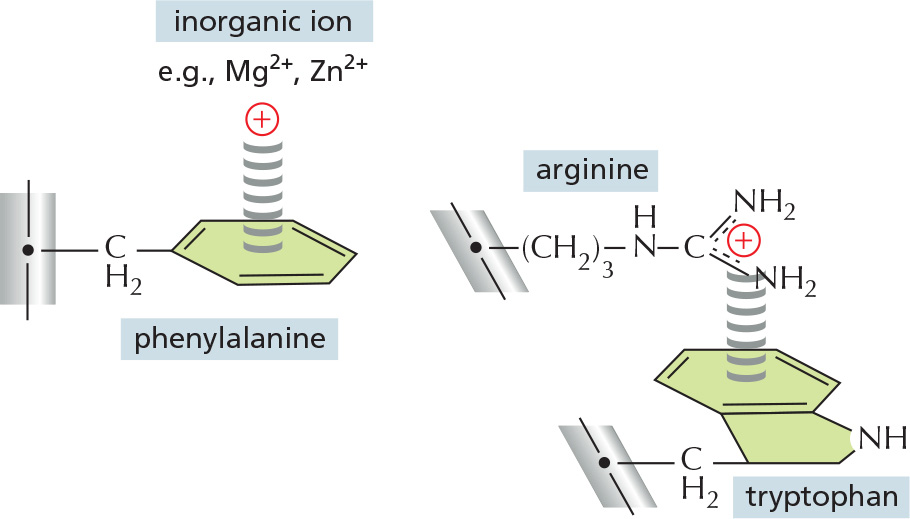
CATION–π INTERACTIONS
The structure of a typical protein reveals that it contains several cation–π (pi) interactions, these electrostatic attractions being about half as abundant as the electrostatic attractions between positively and negatively charged amino-acid side chains. In this energetically favorable interaction, a cation is paired with the aromatic (π) electrons of either a tryptophan, tyrosine, or phenylalanine side chain. As shown, the cation can either be an inorganic ion or a positively charged lysine or arginine side chain. A tryptophan–arginine pair is the most common, as illustrated here.
ELECTROSTATIC ATTRACTIONS IN WATER
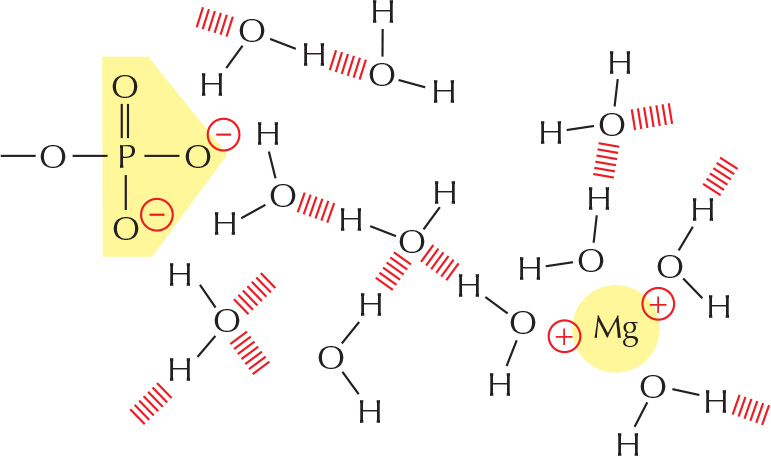
Charged groups are shielded by their interactions with water molecules. Electrostatic attractions are therefore quite weak in water.
Inorganic ions in solution can also cluster around charged groups and further weaken these electrostatic attractions.
Despite being weakened by water and inorganic ions, electrostatic attractions are very important in biological systems.
HYDROPHOBIC FORCES
Water forces hydrophobic groups together in order to minimize their disruptive effects on the water network formed by the hydrogen bonds between water molecules. Hydrophobic groups held together in this way are sometimes said to be held together by “hydrophobic bonds," even though the attraction is actually caused by a repulsion from water.
PANEL 2–4: An Outline of Some of the Types of Sugars Commonly Found in Cells
MONOSACCHARIDES
Monosaccharides usually have the general formula (CH2O)n, where n can be 3, 4, 5, 6, 7, or 8, and have two or more hydroxyl groups. They contain either an aldehyde group and are called aldoses or a ketone group and are called ketoses.
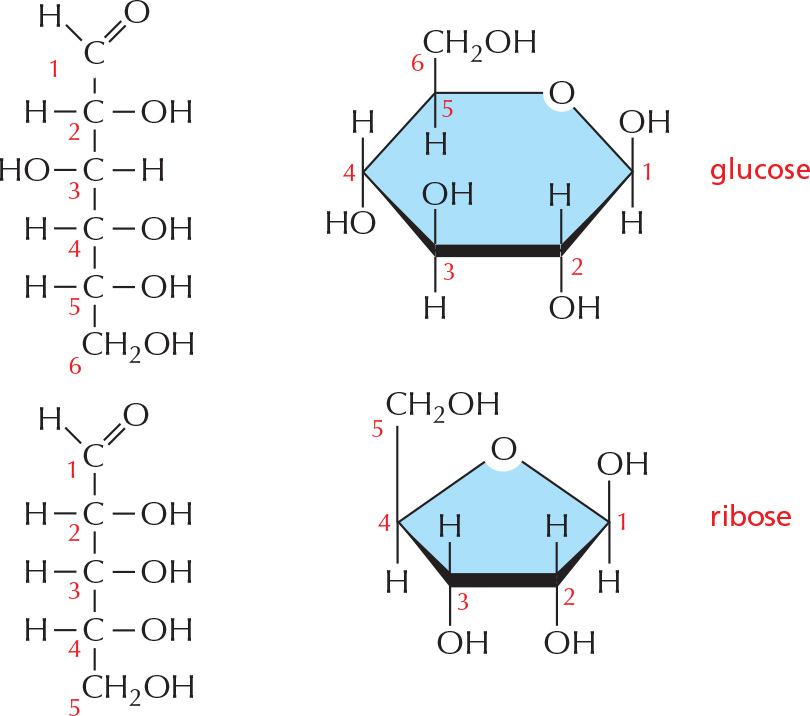
RING FORMATION
In aqueous solution, the aldehyde or ketone group of a sugar molecule tends to react with a hydroxyl group of the same molecule, thereby closing the molecule into a ring.
Note that each carbon atom has a number.
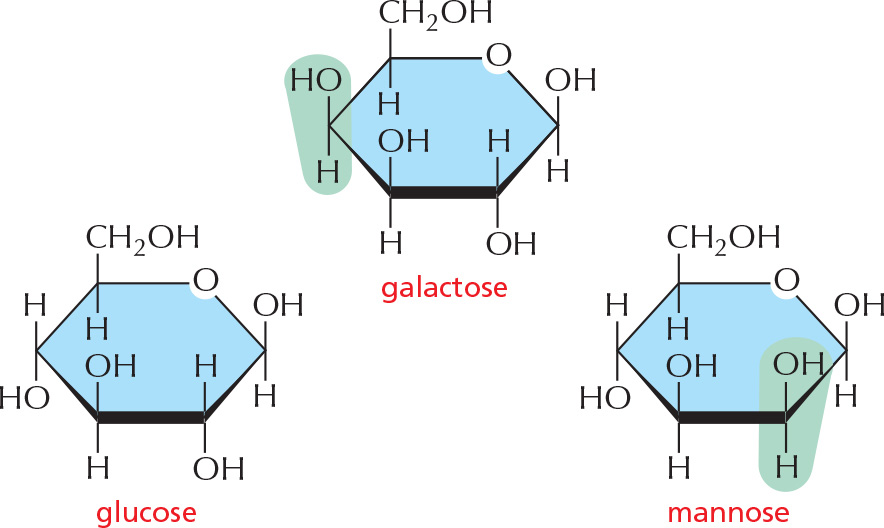
ISOMERS
Many monosaccharides differ only in the spatial arrangement of atoms; that is, they are isomers. For example, glucose, galactose, and mannose have the same formula (C6H12O6) but differ in the arrangement of groups around one or two carbon atoms.
These small differences make only minor changes in the chemical properties of the sugars. But the differences are recognized by enzymes and other proteins and therefore can have major biological effects.
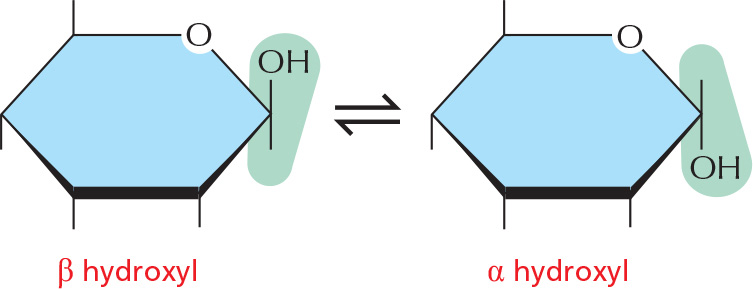
α AND β LINKS
The hydroxyl group on the carbon that carries the aldehyde or ketone can rapidly change from one position to the other. These two positions are called α and β.
As soon as one sugar is linked to another, the α or β form is frozen.
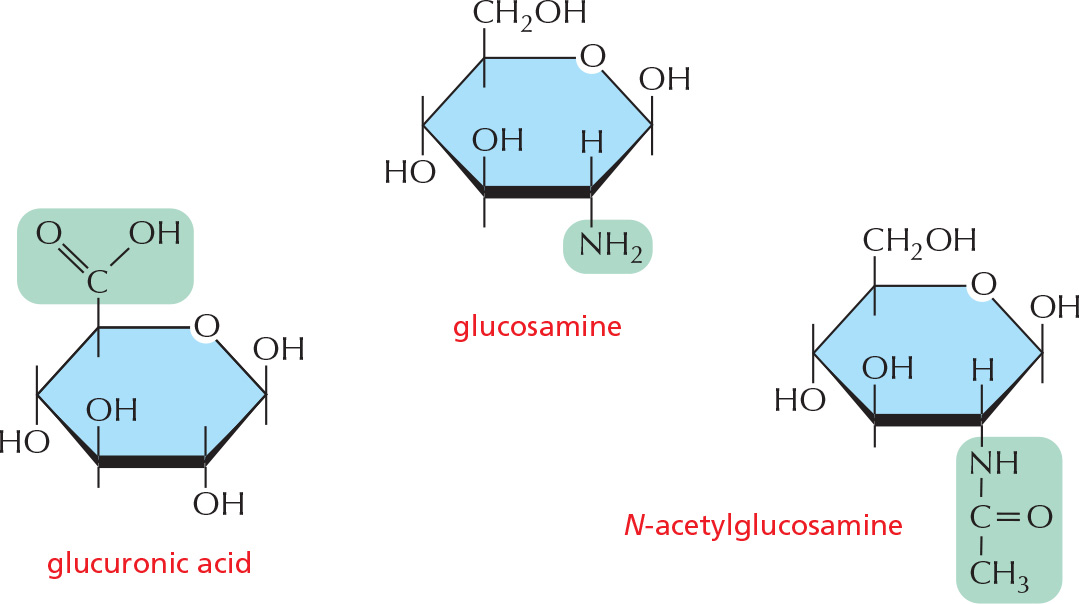
SUGAR DERIVATIVES
The hydroxyl groups of a simple monosaccharide, such as glucose, can be replaced by other groups.
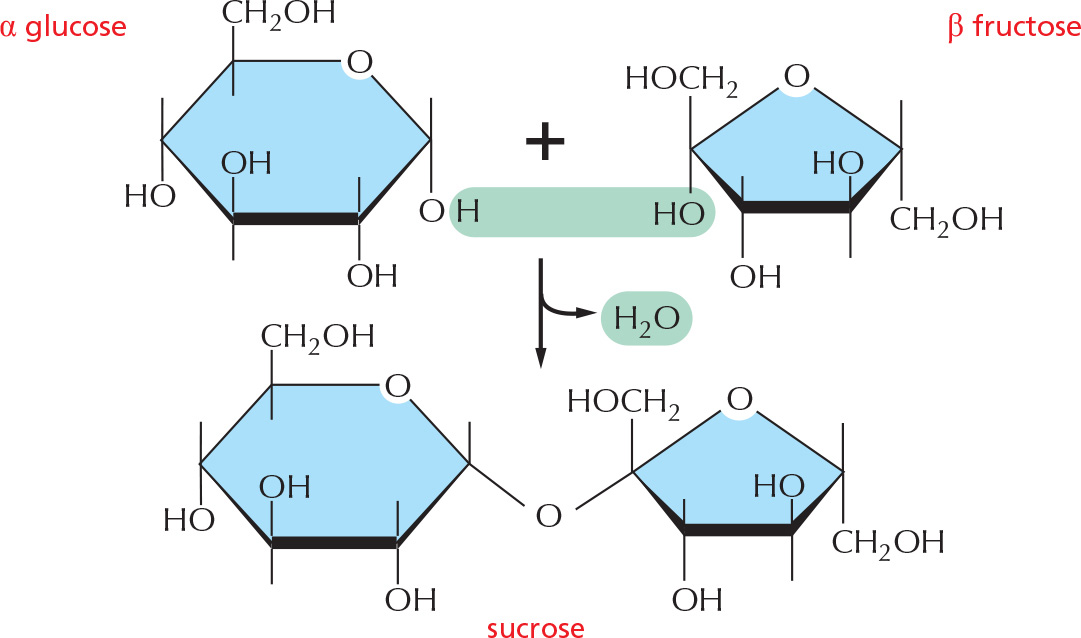
DISACCHARIDES
The carbon that carries the aldehyde or the ketone can react with any hydroxyl group on a second sugar molecule to form a disaccharide. Three common disaccharides are
Large linear and branched molecules can be made from simple repeating sugar subunits. Short chains are called oligosaccharides, and long chains are called polysaccharides.
Glycogen, for example, is a polysaccharide made entirely of glucose subunits joined together.
COMPLEX OLIGOSACCHARIDES
In many cases, a sugar sequence is nonrepetitive. Many different molecules are possible. Such complex oligosaccharides are usually linked to proteins or to lipids, as is this oligosaccharide, which is part of a cell-surface molecule that defines a particular blood group.
PANEL 2–5: Fatty Acids and Other Lipids
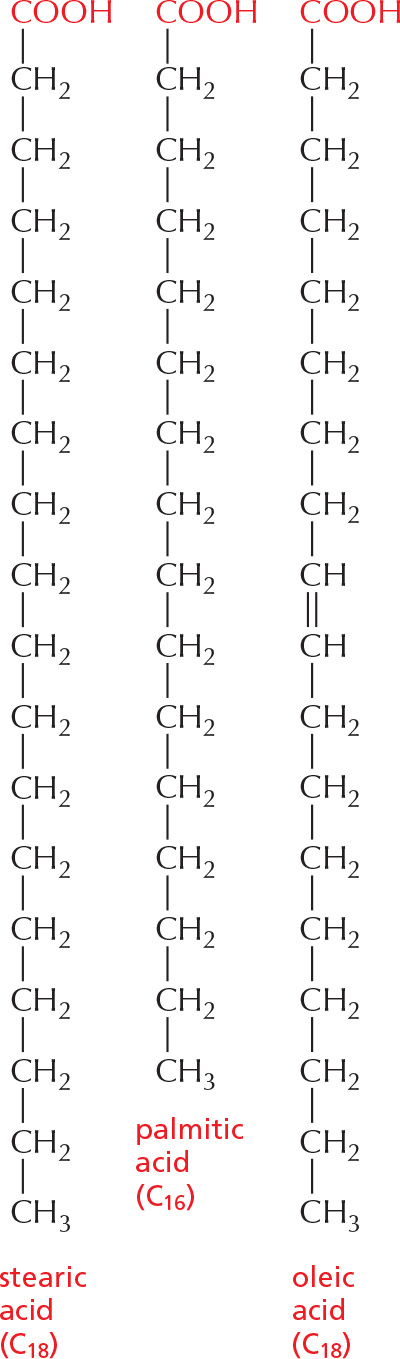
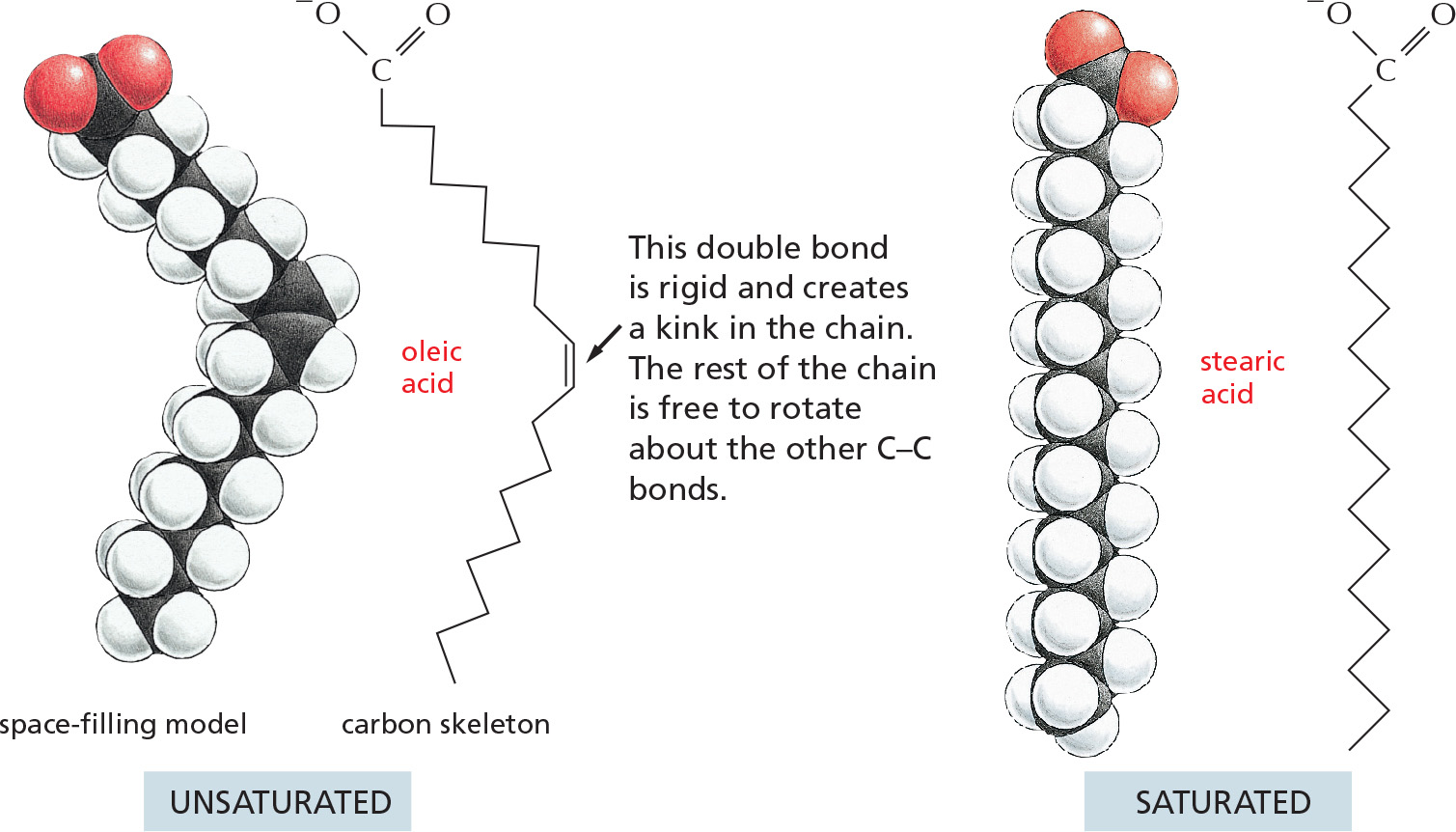
FATTY ACIDS
All fatty acids have a carboxyl group at one end and a long hydrocarbon tail at the other.
Hundreds of different kinds of fatty acids exist. Some have one or more double bonds in their hydrocarbon tail and are said to be unsaturated. Fatty acids with no double bonds are saturated.
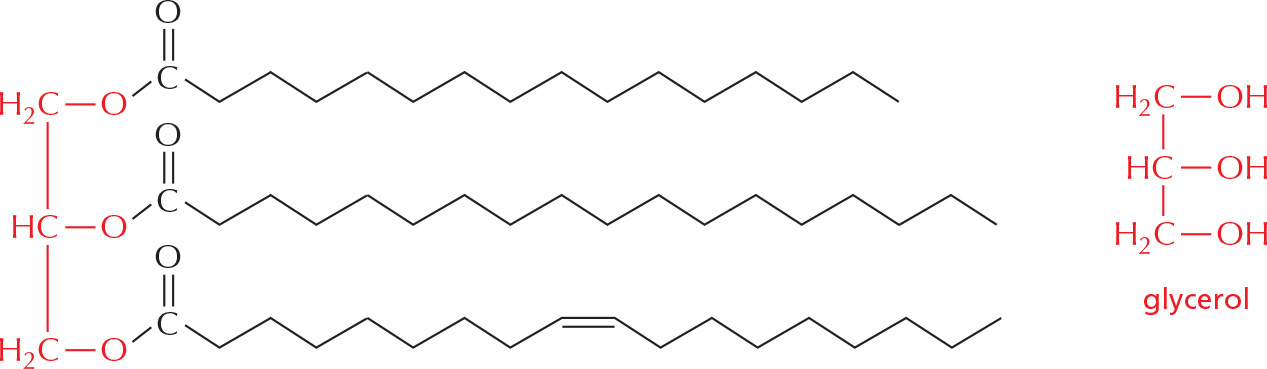
TRIACYLGLYCEROLS
Fatty acids are stored in cells as an energy reserve (fats and oils) through an ester linkage to glycerol to form triacylglycerols, also known as triglycerides.
CARBOXYL GROUP
If free, the carboxyl group of a fatty acid will be ionized.
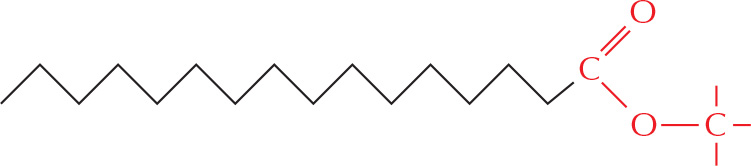
But more often it is linked to other groups to form either esters
or amides.
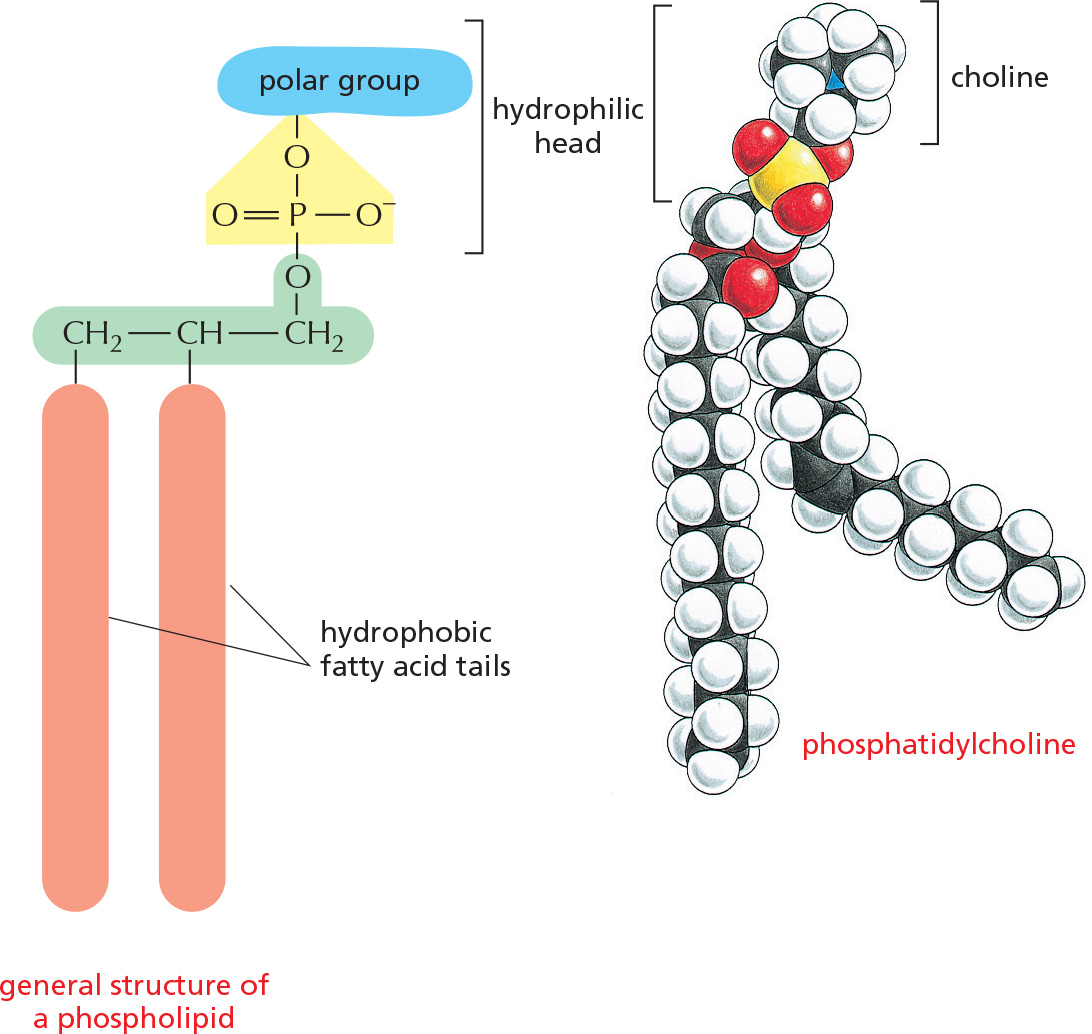
PHOSPHOLIPIDS
Phospholipids are the major constituents of cell membranes.
In phospholipids, two of the –OH groups in glycerol are linked to fatty acids, while the third –OH group is linked to phosphoric acid. The phosphate, which carries a negative charge, is further linked to one of a variety of small polar groups, such as choline.
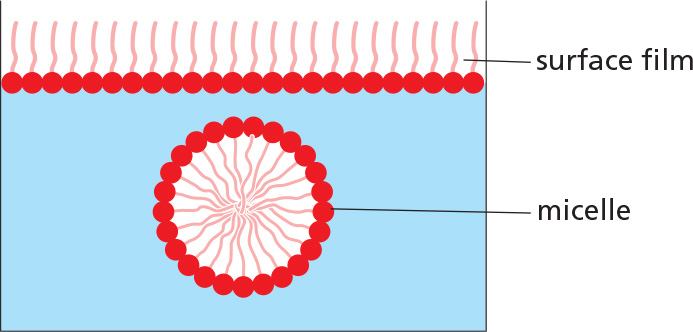
LIPID AGGREGATES
In water, they can form either a surface film or small, spherical micelles.
Their derivatives can form larger aggregates held together by hydrophobic forces:
Triacylglycerols form large, spherical fat droplets in the cell cytoplasm.
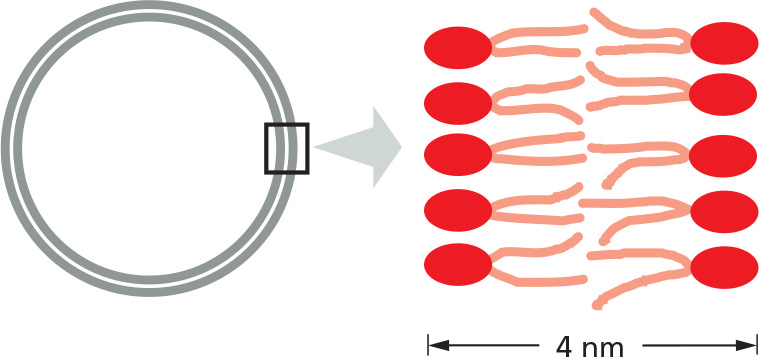
Phospholipids and glycolipids form self-sealing lipid bilayers, which are the basis for all cell membranes.
OTHER LIPIDS
Lipids are defined as water-insoluble molecules that are soluble in organic solvents. Two other common types of lipids are steroids and polyisoprenoids. Both are made from isoprene units.
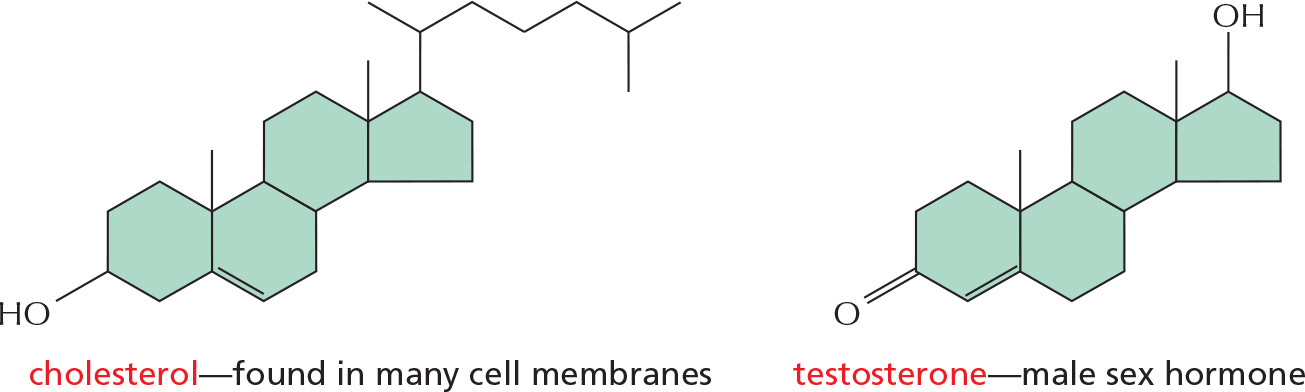
STEROIDS
Steroids have a common multiple-ring structure.
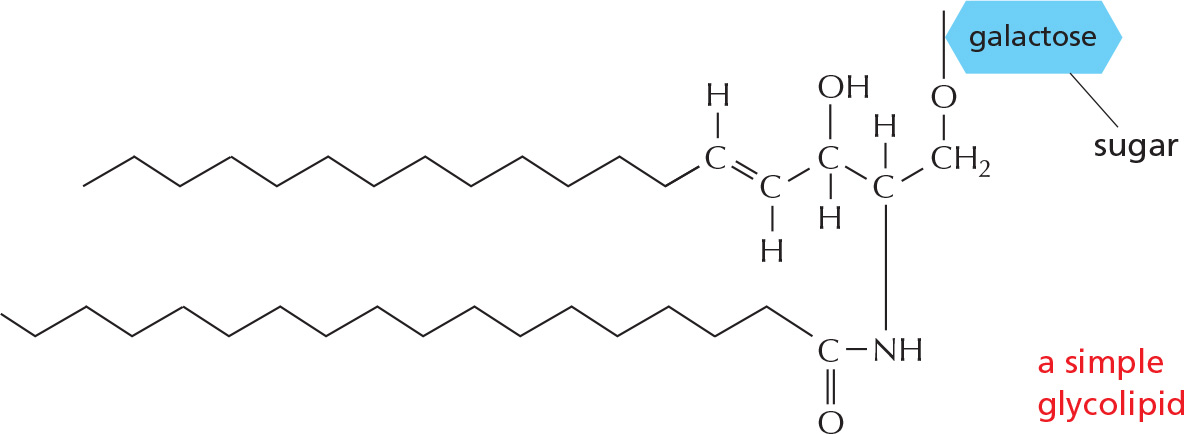
GLYCOLIPIDS
Like phospholipids, these compounds are composed of a hydrophobic region, containing two long hydrocarbon tails, and a polar region, which contains one or more sugars. Unlike phospholipids, there is no phosphate.
POLYISOPRENOIDS
Long-chain polymers of isoprene
dolichol phosphate—used to carry activated sugars in the membrane-associated synthesis of glycoproteins and some polysaccharides
PANEL 2–6: A Survey of the Nucleotides
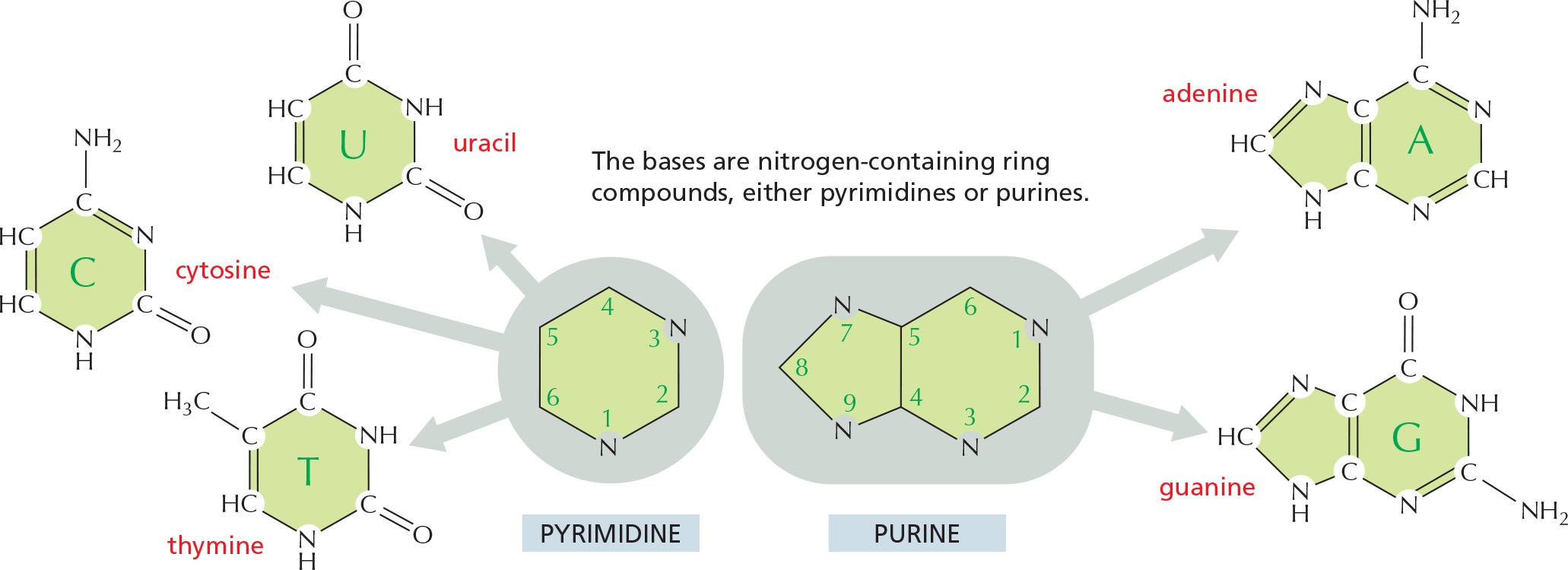
BASES
PHOSPHATES
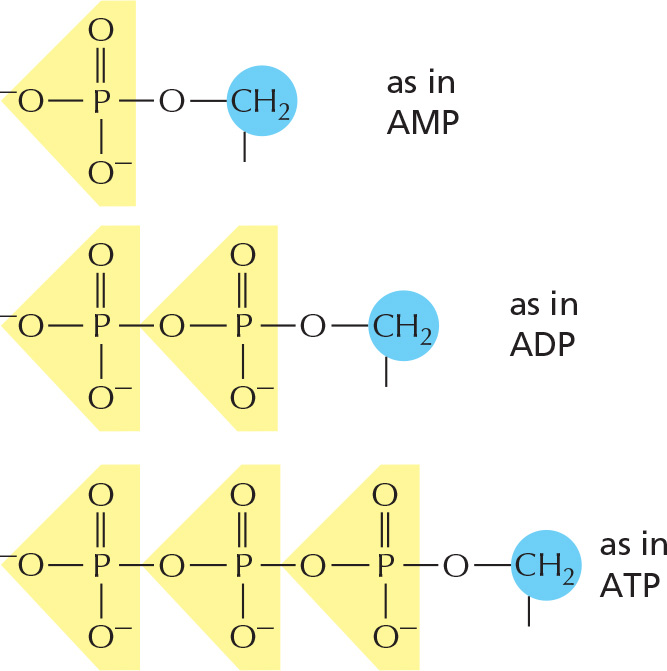
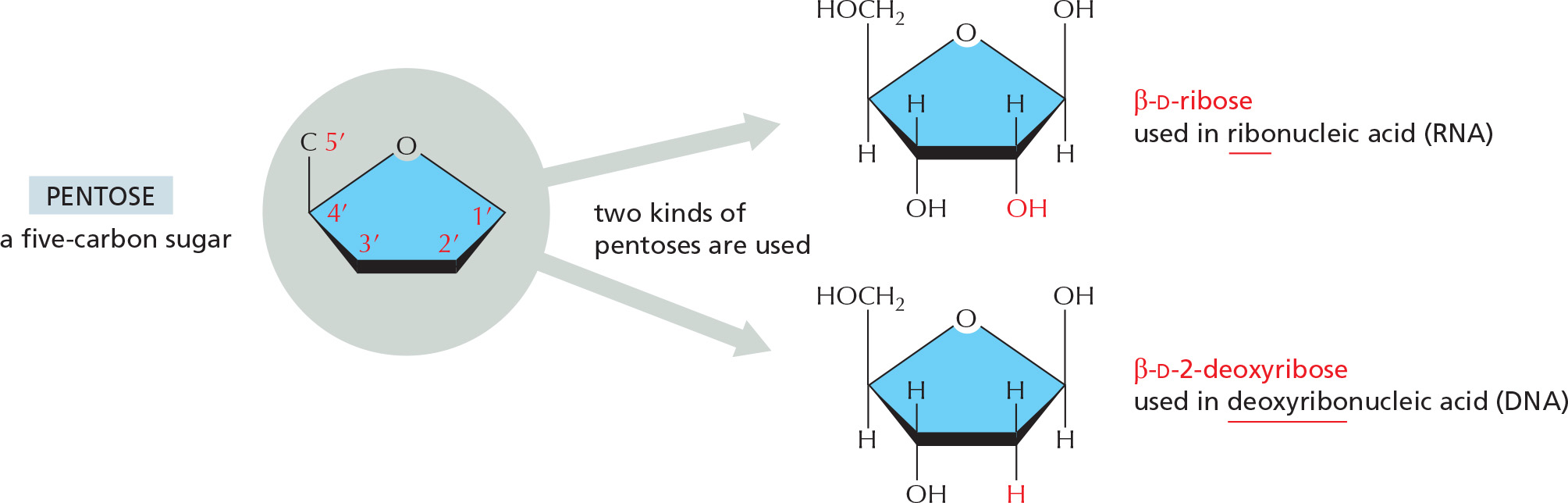
The phosphates are normally joined to the C5 hydroxyl of the ribose or deoxyribose sugar (designated 5′). Mono-, di-, and triphosphates are common.
The phosphate makes a nucleotide negatively charged.
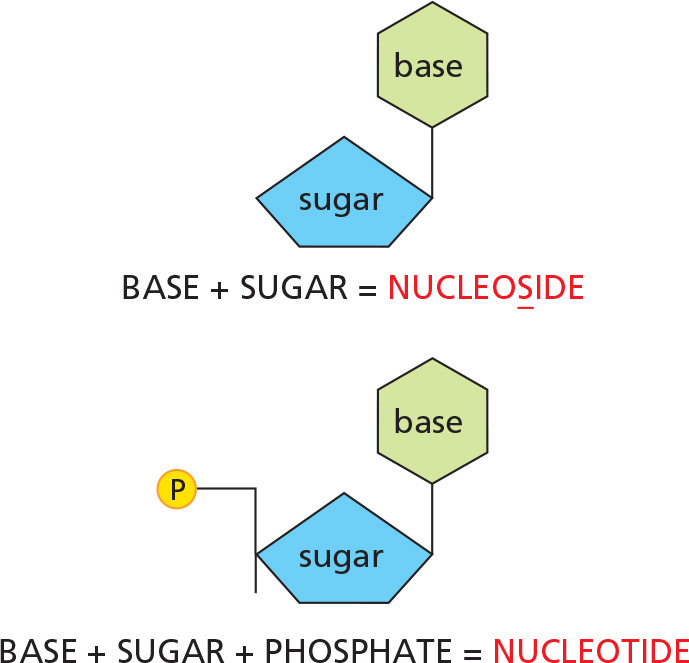
NUCLEOTIDES
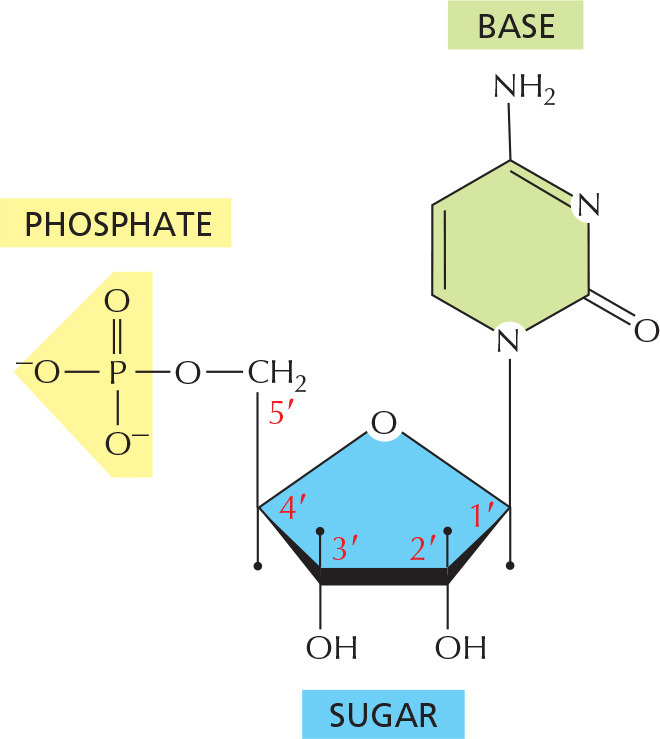
A nucleotide consists of a nitrogen-containing base, a five-carbon sugar, and a phosphate group.
Nucleotides are the subunits of the nucleic acids.
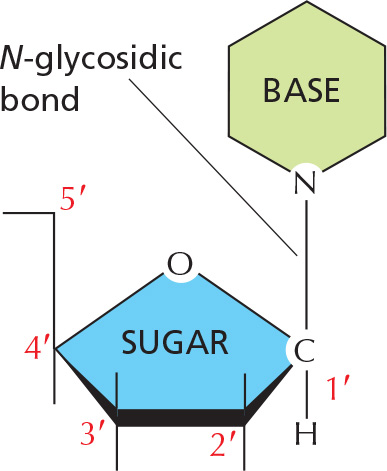
BASE–SUGAR LINKAGE
The base is linked to the same carbon (C1) used in sugar–sugar bonds.
SUGARS
Each numbered carbon on the sugar of a nucleotide is followed by a prime mark; therefore, one speaks of the “5-prime carbon,” etc.
NOMENCLATURE
BASE
NUCLEOSIDE
ABBR.
adenine
adenosine
A
guanine
guanosine
G
cytosine
cytidine
C
uracil
uridine
U
thymine
thymine
T
A nucleoside or nucleotide is named according to its nitrogenous base.
Single-letter abbreviations are used variously as shorthand for (1) the base alone, (2) the nucleoside, or (3) the whole nucleotide—the context will usually make clear which of the three entities is meant. When the context is not sufficient, we will add the terms “base,” “nucleoside,“ “nucleotide,“ or—as in the examples below—use the full 3-letter nucleotide code.
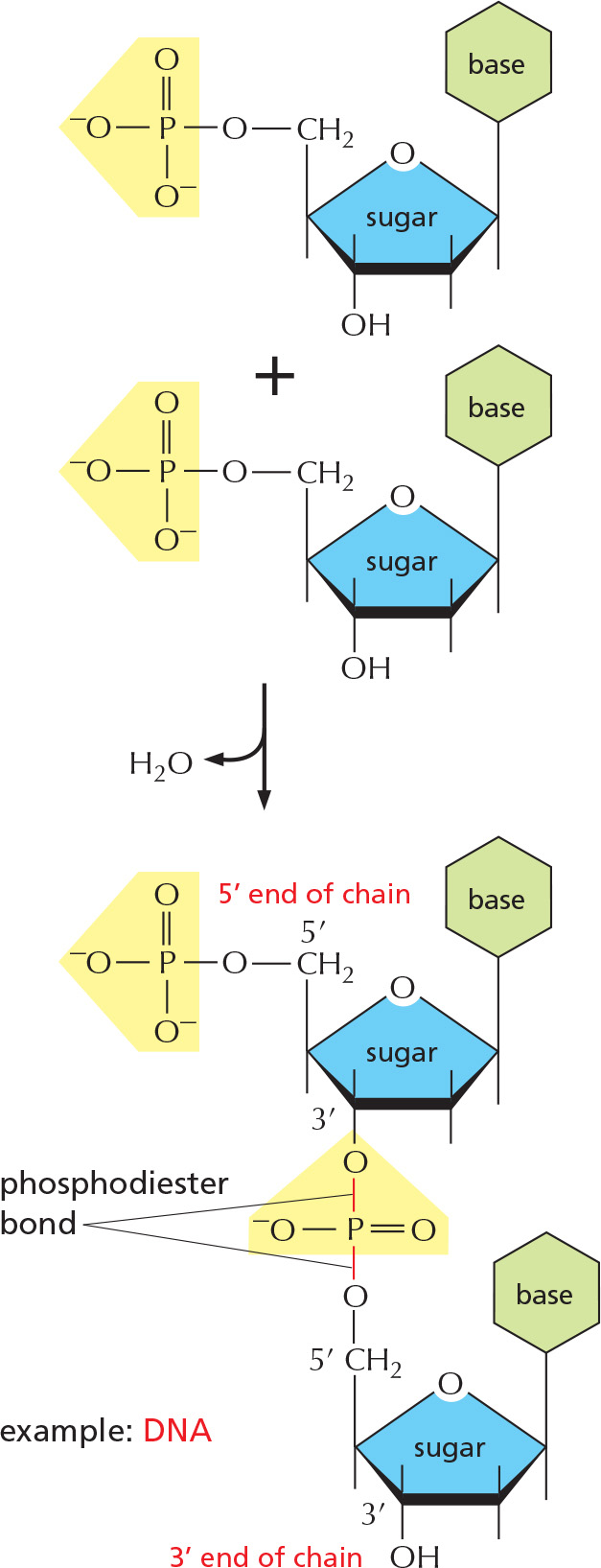
To form nucleic acid polymers, nucleotides are joined together by phosphodiester bonds between the 5' and 3' carbon atoms of adjacent sugar rings. The linear sequence of nucleotides in a nucleic acid chain is abbreviated using a one-letter code, such as AGCTT, starting with the 5' end of the chain.
NUCLEOTIDES AND THEIR DERIVATIVES HAVE MANY OTHER FUNCTIONS
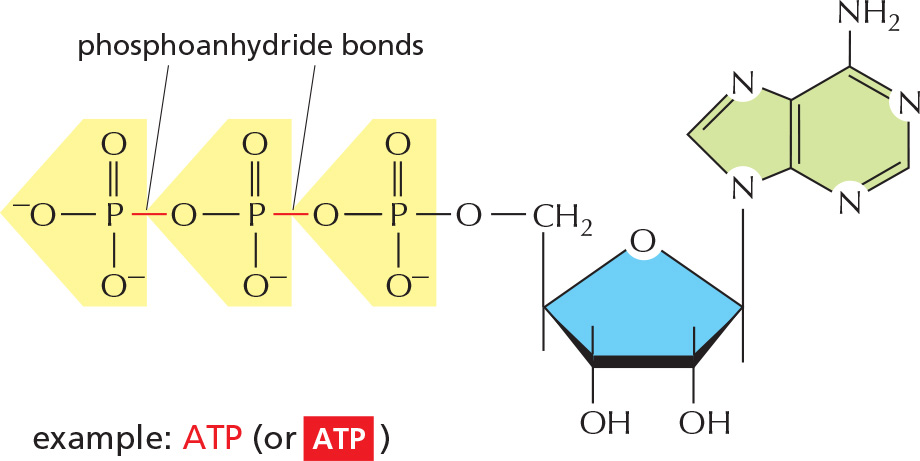
1 As nucleoside di- and triphosphates, they carry chemical energy in their easily hydrolyzed phosphoanhydride bonds.
2 They combine with other groups to form coenzymes.
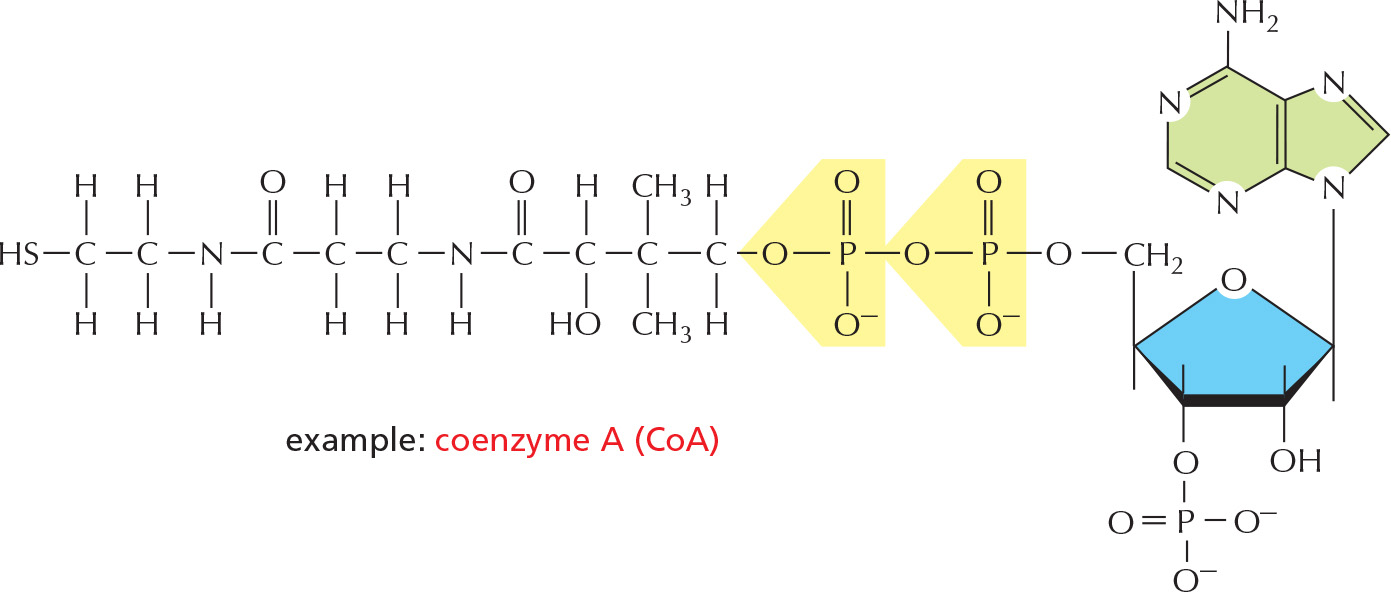
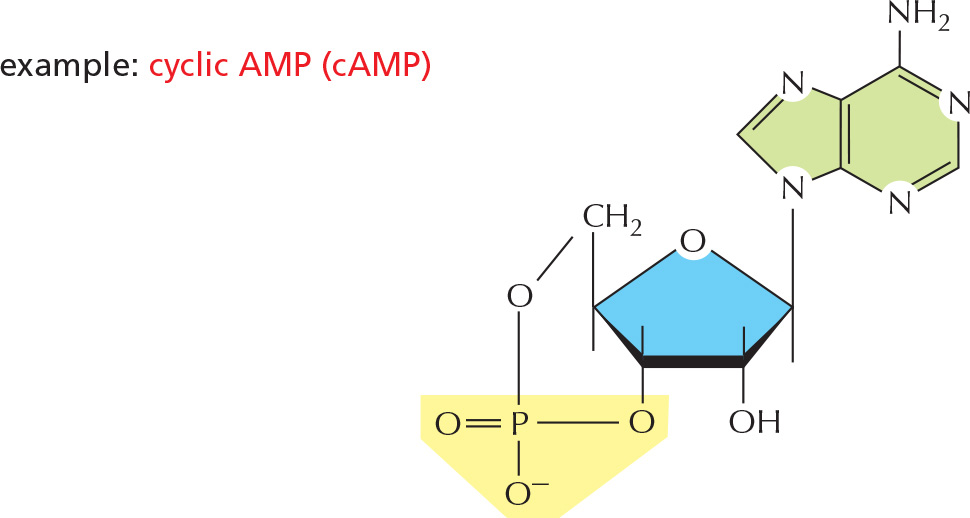
3 They are used as small intracellular signaling molecules in the cell example:
PANEL 2–7: Free Energy and Biological Reactions
THE IMPORTANCE OF FREE ENERGY FOR CELLS
Life is possible because of the complex network of interacting chemical reactions occurring in every cell. In viewing the metabolic pathways that comprise this network, one might suspect that the cell has had the ability to evolve an enzyme to carry out any reaction that it needs. But this is not so. Although enzymes are powerful catalysts, they can promote only those reactions that are thermodynamically possible; other reactions proceed in cells only because they are coupled to very favorable reactions that drive them.
The question of whether a reaction can occur spontaneously, or instead needs to be coupled to another reaction, is central to cell biology. The answer is obtained by reference to a quantity called the free energy.In this Panel, we shall explain some of the fundamental ideas—derived from a special branch of chemistry and physics called thermodynamics—that are required for understanding what free energy is and why it is so important to cells.
ENERGY RELEASED BY CHANGES IN CHEMICAL BONDING IS CONVERTED INTO HEAT
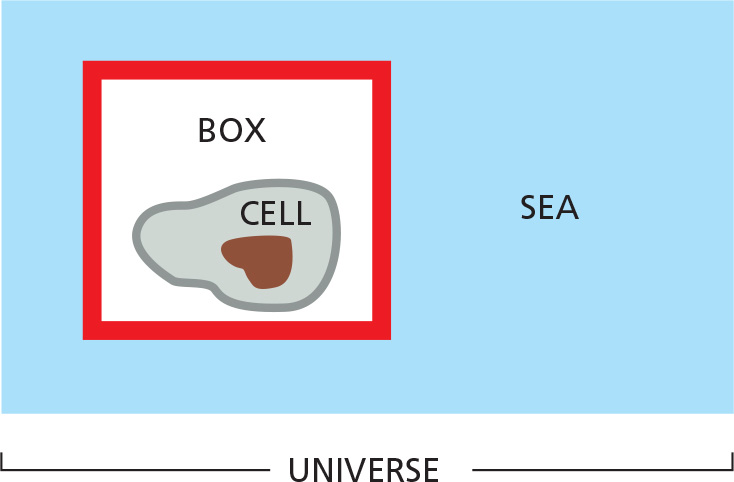
An enclosed system is defined as a collection of molecules that does not exchange matter with the rest of the universe (e.g., the “cell in a box" shown above). Any such system will contain molecules with a total energy E. This energy will be distributed in a variety of ways: some as the translational energy of the molecules, some as their vibrational and rotational energies, but most as the bonding energies between the individual atoms that make up the molecules. Suppose that a reaction occurs in the system. The first law of thermodynamics places a constraint on what types of reactions are possible: it states that “in any process, the total energy of the universe remains constant.” For example, suppose that reaction A→B occurs somewhere in the box and releases a great deal of chemical-bond energy. This energy will initially increase the intensity of molecular motions (translational, vibrational, and rotational) in the system, which is equivalent to raising its temperature. However, these increased motions will soon be transferred out of the system by a series of molecular collisions that heat up first the walls of the box and then the outside world (represented by the sea in our example). In the end, the system returns to its initial temperature, by which time all the chemical-bond energy released in the box has been converted into heat energy and transferred out of the box to the surroundings. According to the first law, the change in the energy in the box (ΔEbox, which we shall denote as ΔE) must be equal and opposite to the amount of heat energy transferred, which we shall designate as h; that is, ΔE = –h. Thus, the energy in the box (E) decreases when heat leaves the system.
E also can change during a reaction as a result of work being done on the outside world. For example, suppose that there is a small increase in the volume (ΔV) of the box during a reaction. Because the walls of the box must push against the constant pressure (P) in the surroundings in order to expand, this does work on the outside world and requires energy. The energy used is P(ΔV), which according to the first law must decrease the energy in the box (E) by the same amount. In most reactions, chemical-bond energy is converted into both work and heat. Enthalpy (H) is a composite function that includes both of these (H = E + PV). To be rigorous, it is the change in enthalpy (ΔH) in an enclosed system, and not the change in energy, that is equal to the heat transferred to the outside world during a reaction. Reactions in which H decreases release heat to the surroundings and are said to be “exothermic," while reactions in which H increases absorb heat from the surroundings and are said to be “endothermic." Thus, –h = ΔH. However, the volume change is negligible in most biological reactions, so to a good approximation
–h = ΔH ≈ ΔE
THE SECOND LAW OF THERMODYNAMICS
Consider a container in which 1000 coins are all lying heads-up. If the container is shaken vigorously, subjecting the coins to the types of random motions that all molecules experience due to their frequent collisions with other molecules, one will end up with about half the coins oriented heads-down. The reason for this reorientation is that there is only a single way in which the original orderly state of the coins can be reinstated (every coin must lie heads-up), whereas there are many different ways (about 10298) to achieve a disorderly state in which there is an equal mixture of heads and tails; in fact, there are more ways to achieve a 50–50 state than to achieve any other state. Each state has a probability of occurrence that is proportional to the number of ways it can be realized. The second law of thermodynamics states that “systems will change spontaneously from states of lower probability to states of higher probability.” Because states of lower probability are more ordered than states of higher probability, the second law can be restated: “the universe constantly changes so as to become more disordered.”
THE ENTROPY, S
The second law (but not the first law) allows one to predict the direction of a particular reaction. But to make it useful for this purpose, one needs a convenient measure of the probability or, equivalently, the degree of disorder of a state. The entropy (S) is such a measure. It is a logarithmic function of the probability. Thus the change in entropy (ΔS) that occurs when the reaction A → B converts 1 mole of A into 1 mole of B is
ΔS = R In pB/pA
where pA and pB are the probabilities of the two states A and B, R is the gas constant (8.31 J K–1 mole–1), and ΔS is measured in entropy units (eu).
For 1000 coins, the relative probability of all heads (state A) versus half heads and half tails (state B) is equal to the ratio of the number of different ways that the two results can be obtained. One can calculate that pA = 1 and pB = 1000!/(500! × 500!) = 10298. Therefore, the entropy change for the reorientation of the coins when their container is vigorously shaken and an equal mixture of heads and tails is obtained is R In (10298), or about 1370 eu per mole of such containers (6 × 1023 containers). Because ΔS defined above is positive for the transition from state A to state B (pB/pA > 1), reactions with an increase in S (i.e., for which ΔS > 0) are favored and will occur spontaneously.
Heat energy causes the random commotion of molecules. Because the transfer of heat from an enclosed system to its surroundings increases the number of different arrangements that the molecules in the outside world can have, it increases their entropy. It can be shown that the release of a fixed quantity of heat energy has a greater disordering effect at low temperature than at high temperature, and that the value of ΔS for the surroundings, as described above (ΔSsea), is precisely equal to h, the amount of heat transferred to the surroundings from the system, divided by the absolute temperature (T):
ΔSsea = h/T
THE GIBBS FREE ENERGY, G
When dealing with an enclosed biological system, one would like to have a simple way of predicting whether a given reaction will or will not occur spontaneously in the system. We have seen that the crucial question is whether the entropy change for the universe is positive or negative when that reaction occurs. In our idealized system, the cell in a box, there are two separate components to the entropy change of the universe—the entropy change for the system enclosed in the box and the entropy change for the surrounding “sea”—and both must be added together before any prediction can be made. For example, it is possible for a reaction to absorb heat and thereby decrease the entropy of the sea (ΔSsea < 0) and at the same time cause such a large degree of disordering inside the box (ΔSbox > 0) that the total ΔSuniverse = ΔSsea + ΔSbox is greater than zero. In this case, the reaction will occur spontaneously, even though the sea gives up heat to the box during the reaction. An example of such a reaction is the dissolving of sodium chloride in a beaker containing water (the “box”), which is a spontaneous process even though the temperature of the water drops as the salt goes into solution.
Chemists have found it useful to define a number of new “composite functions” that describe combinations of physical properties of a system. The properties that can be combined include the temperature (T), pressure (P), volume (V), energy (E), and entropy (S). The enthalpy (H) is one such composite function. But by far the most useful composite function for biologists is the Gibbs free energy, G. It serves as an accounting device that allows one to deduce the entropy change of the universe resulting from a chemical reaction in the box, while avoiding any separate consideration of the entropy change in the sea. The definition of G is
G = H – TS
where, for a box of volume V, H is the enthalpy described earlier (E + PV), T is the absolute temperature, and S is the entropy. Each of these quantities applies to the inside of the box only. The change in free energy during a reaction in the box (the G of the products minus the G of the starting materials) is denoted as ΔG and, as we shall now demonstrate, it is a direct measure of the amount of disorder that is created in the universe when the reaction occurs.
At constant temperature the change in free energy (ΔG) during a reaction equals ΔH – TΔS. Remembering that ΔH = –h, the heat absorbed from the sea, we have
–ΔG = –ΔH + TΔS
–ΔG = h + TΔS, so –ΔG/T = h/T + ΔS
But h/T is equal to the entropy change of the sea (ΔSsea), and the ΔS in the above equation is ΔSbox. Therefore
–ΔG/T = ΔSsea + ΔSbox = ΔSuniverse
We conclude that the free-energy change is a direct measure of the entropy change of the universe. A reaction will proceed in the direction that causes the change in the free energy (ΔG) to be less than zero, because in this case there will be a positive entropy change in the universe when the reaction occurs.
For a complex set of coupled chemical reactions involving many different molecules, the total free-energy change can be computed simply by adding up the free energies of all the different molecular species after the reaction and comparing this value with the sum of free energies before the reaction. For common substances, the required free-energy values can be found from published tables. In this way, one can predict the direction of a reaction and thereby readily check the feasibility of any proposed mechanism. (Thus, for example, from the magnitude of the electrochemical proton gradient across the inner mitochondrial membrane and the ΔG for ATP hydrolysis inside the mitochondrion, one can be certain that the ATP synthase enzyme requires that more than one proton pass through it for each molecule of ATP that it synthesizes.)
The value of ΔG for a reaction is a direct measure of how far the reaction is from equilibrium. The large negative value for ATP hydrolysis in a cell merely reflects the fact that cells keep the ATP hydrolysis reaction as much as 10 orders of magnitude away from equilibrium. If a reaction reaches equilibrium, ΔG = 0, that reaction then proceeds at precisely equal rates in the forward and backward directions. For ATP hydrolysis, equilibrium is reached when the vast majority of the ATP has been hydrolyzed, as occurs in a dead cell.
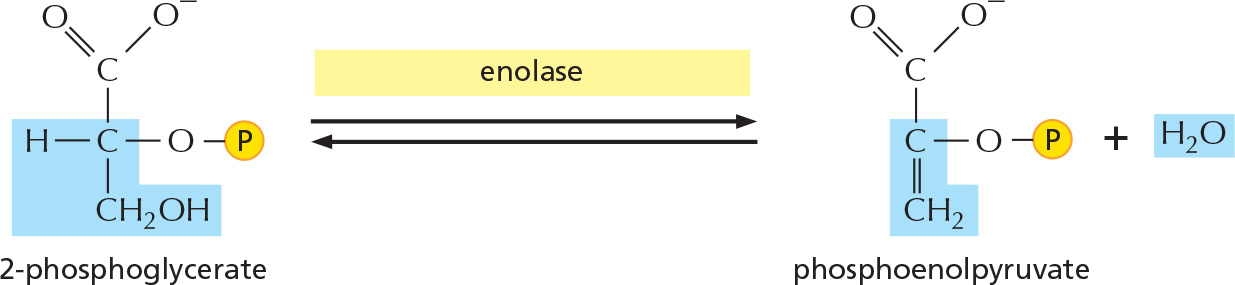
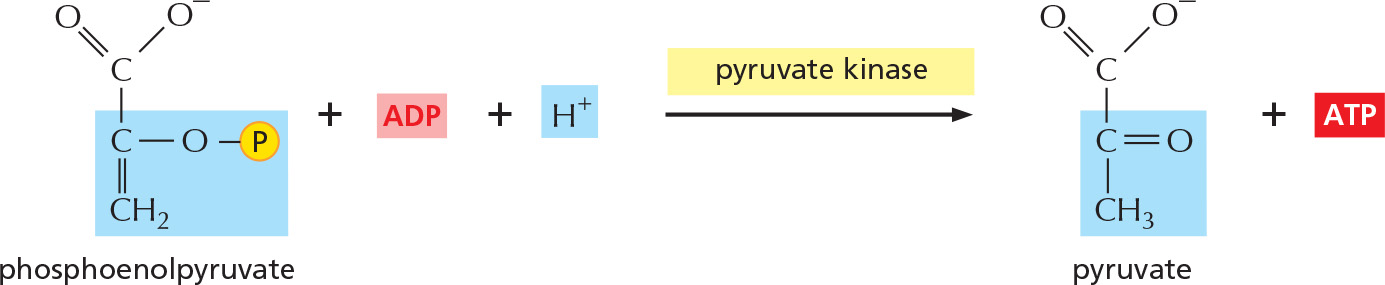
PANEL 2–8: Details of the 10 Steps of Glycolysis
For each step, the part of the molecule that undergoes a change is shadowed in blue, and the name of the enzyme that catalyzes the reaction is in a yellow box. Reactions represented by double arrows (⇄) are readily reversible, whereas those represented by single arrows (→) are effectively irreversible. To watch a video of the reactions of glycolysis, see Movie 2.5.
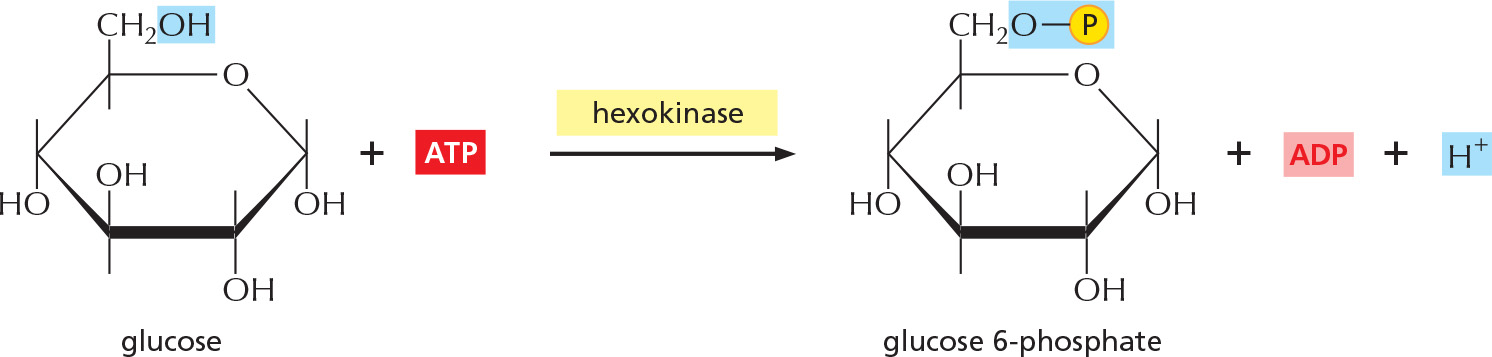
STEP 1
Glucose is phosphorylated by ATP to form a sugar phosphate. The negative charge of the phosphate prevents passage of the sugar phosphate through the plasma membrane, trapping glucose inside the cell.
STEP 2
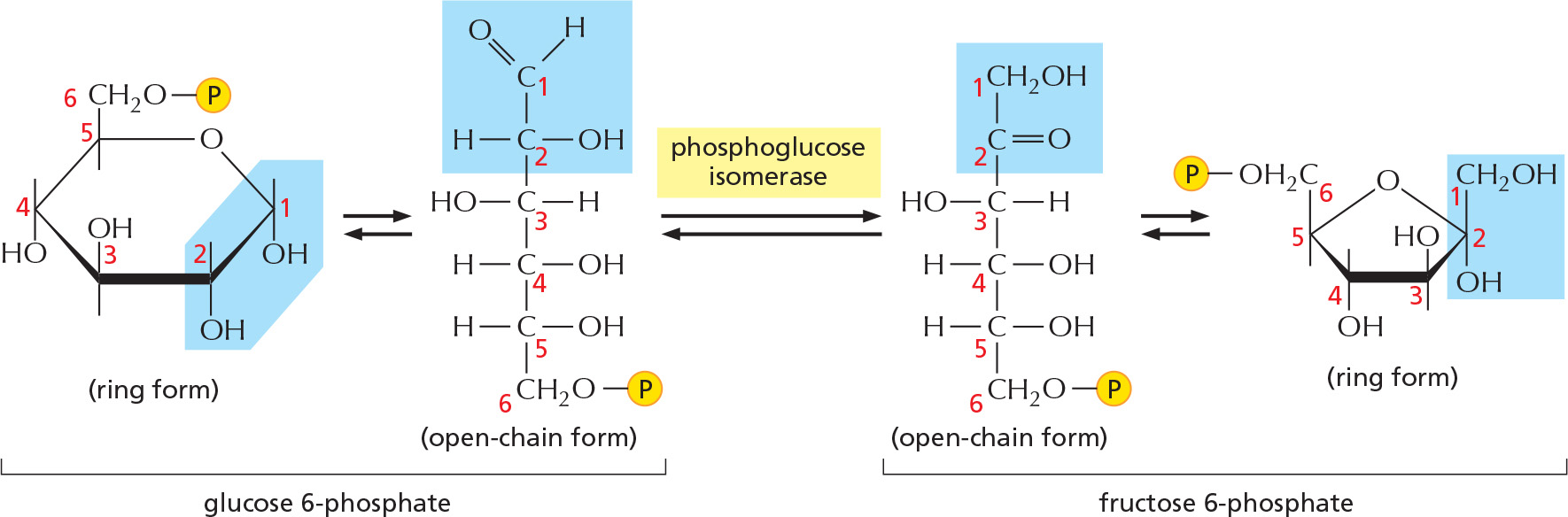
A readily reversible rearrangement of the chemical structure (isomerization) moves the carbonyl oxygen from carbon 1 to carbon 2, forming a ketose from an aldose sugar. (See Panel 2–4, pp. 100–101.)
STEP 3
The new hydroxyl group on carbon 1 is phosphorylated by ATP, in preparation for the formation of two three-carbon sugar phosphates. The entry of sugars into glycolysis is controlled at this step, through regulation of the enzyme phosphofructokinase.
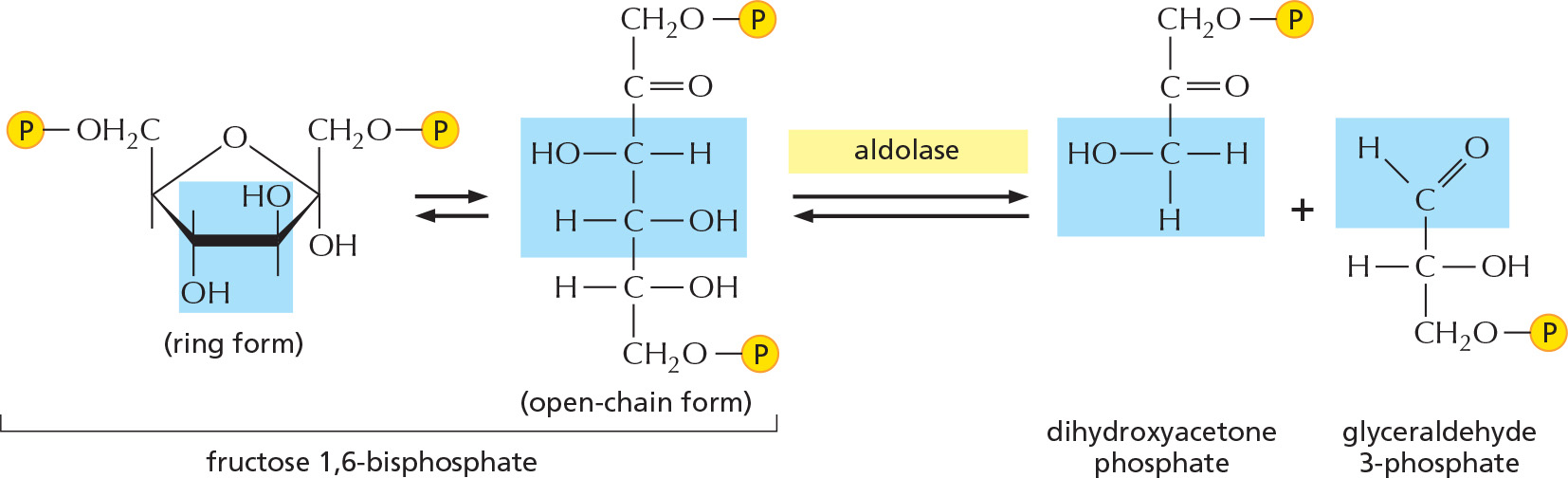
STEP 4
The six-carbon sugar is cleaved to produce two three-carbon molecules. Only the glyceraldehyde 3-phosphate can proceed immediately through glycolysis.
STEP 5
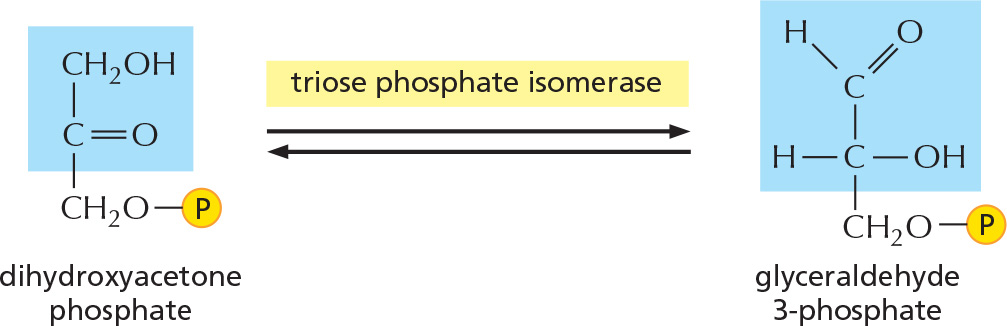
The other product of step 4, dihydroxyacetone phosphate, is isomerized to form a second molecule of glyceraldehyde 3-phosphate.
STEP 6
The two molecules of glyceraldehyde 3-phosphate produced in steps 4 and 5 are oxidized. The energy-generation phase of glycolysis begins, as NADH and a new high-energy anhydride linkage to phosphate are formed (see Figure 2-47).
STEP 7
The transfer to ADP of the high-energy phosphate group that was generated in step 6 forms ATP.
STEP 8
The remaining phosphate ester linkage in 3-phosphoglycerate, which has a relatively low free energy of hydrolysis, is moved from carbon 3 to carbon 2 to form 2-phosphoglycerate.
STEP 9
The removal of water from 2-phosphoglycerate creates a high-energy enol phosphate linkage.
STEP 10
The transfer to ADP of the high-energy phosphate group that was generated in step 9 forms ATP, completing glycolysis.
NET RESULT OF GLYCOLYSIS
In addition to the pyruvate, the net products of glycolysis are two molecules of ATP and two molecules of NADH.
PANEL 2–9: The Complete Citric Acid Cycle
Overview of the complete citric acid cycle. The two carbons from acetyl CoA that enter this turn of the cycle (shadowed in red ) will be converted to CO2 in subsequent turns of the cycle: the two carbons in the starting oxaloacetate (shadowed in blue) will be converted to CO2 in this cycle.
Details of these eight steps are shown below. In this part of the Panel, for each step, the part of the molecule that undergoes a change is shadowed in blue, and the name of the enzyme that catalyzes the reaction is in a yellow box. To watch a video of the reactions of the citric acid cycle, see Movie 2.6.
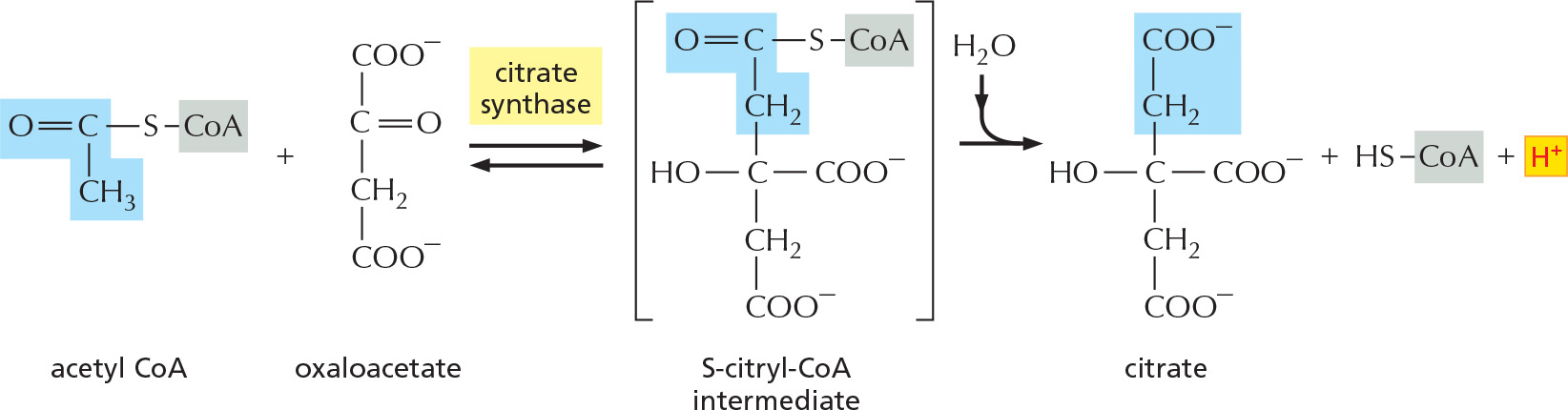
STEP 1
After the enzyme removes a proton from the CH3 group on acetyl CoA, the negatively charged CH2– forms a bond to a carbonyl carbon of oxaloacetate. The subsequent loss by hydrolysis of the coenzyme A (HS–CoA) drives the reaction strongly forward.
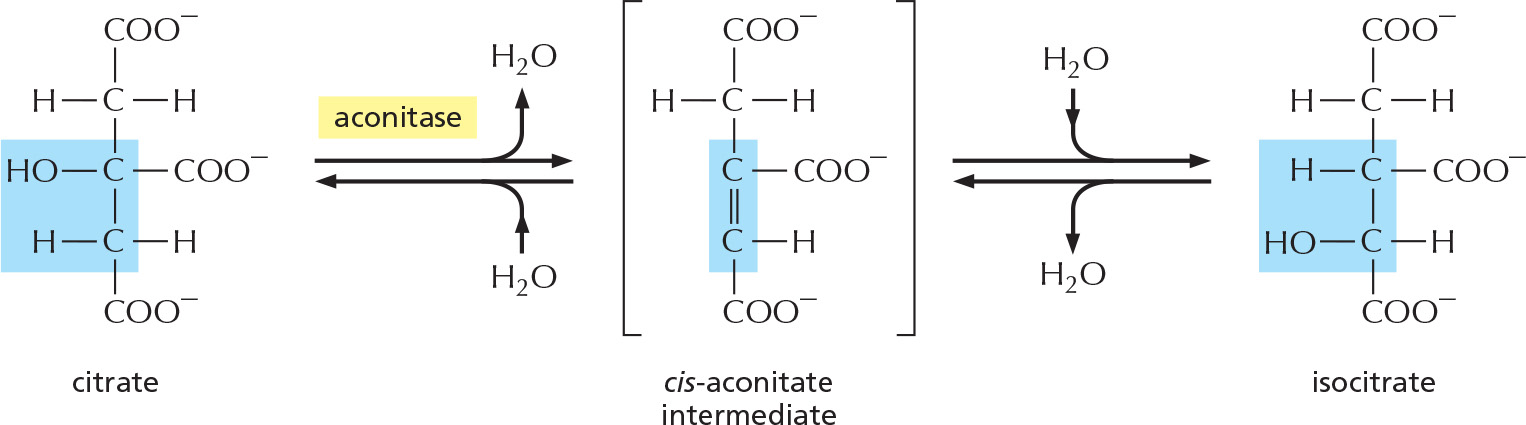
STEP 2
An isomerization reaction, in which water is first removed and then added back, moves the hydroxyl group from one carbon atom to its neighbor.
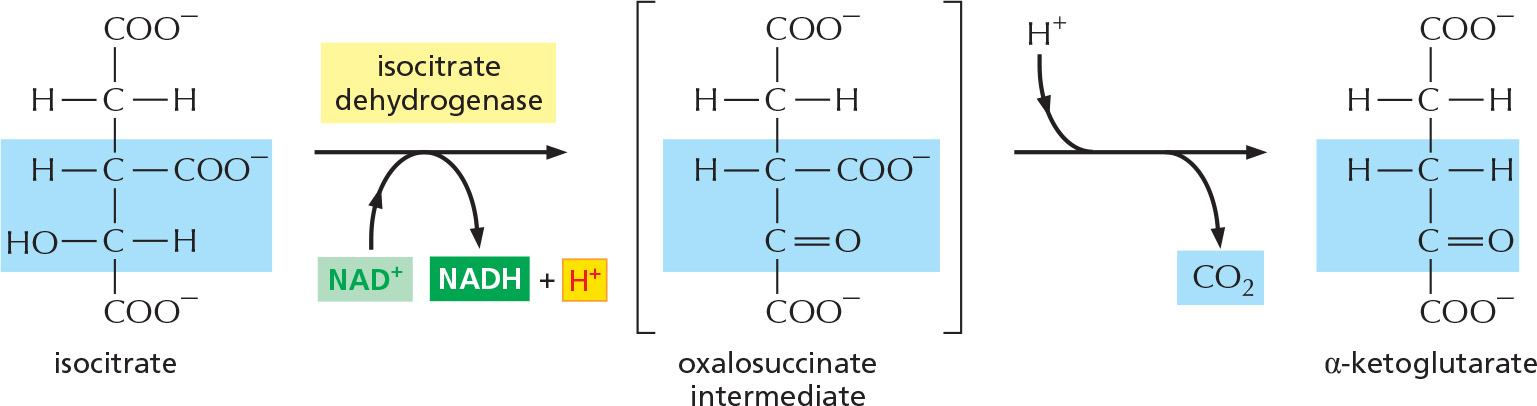
STEP 3
In the first of four oxidation steps in the cycle, the carbon carrying the hydroxyl group is converted to a carbonyl group. The immediate product is unstable, losing CO2 while still bound to the enzyme.
STEP 4
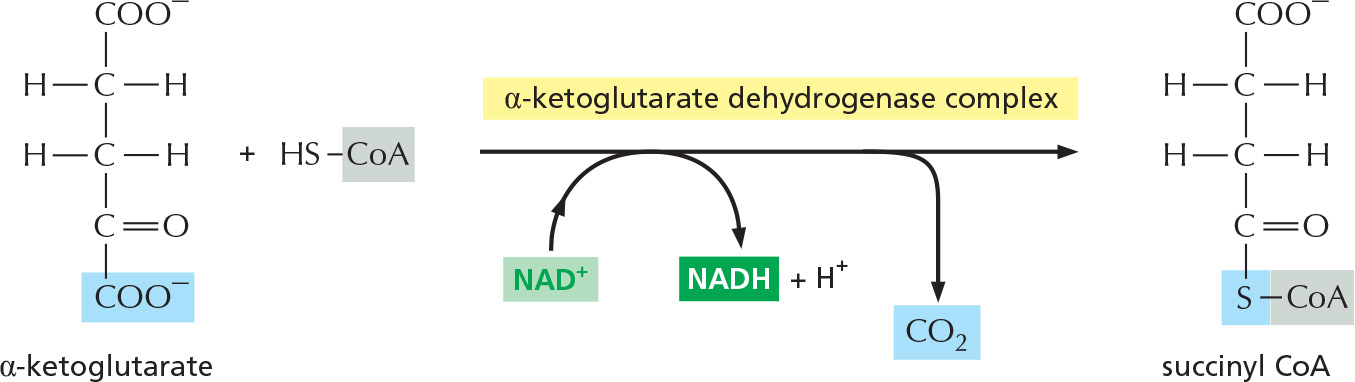
The α-ketoglutarate dehydrogenase complex closely resembles the large enzyme complex that converts pyruvate to acetyl CoA, the pyruvate dehydrogenase complex. It likewise catalyzes an oxidation that produces NADH, CO2, and a high-energy thioester bond to coenzyme A (CoA).
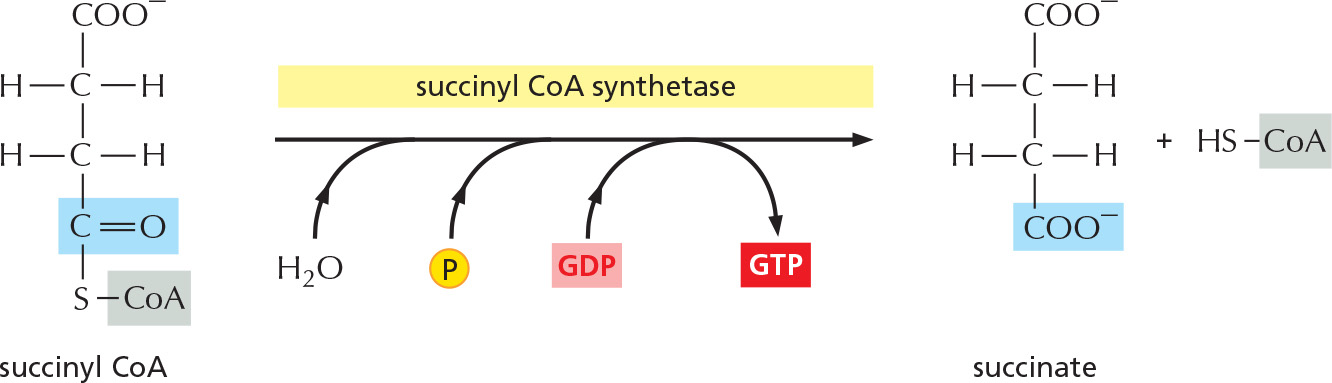
STEP 5
An inorganic phosphate displaces the CoA, forming a high-energy phosphate linkage to succinate. This phosphate is then passed to GDP to form GTP. (In bacteria and plants, ATP is formed instead.)
STEP 6
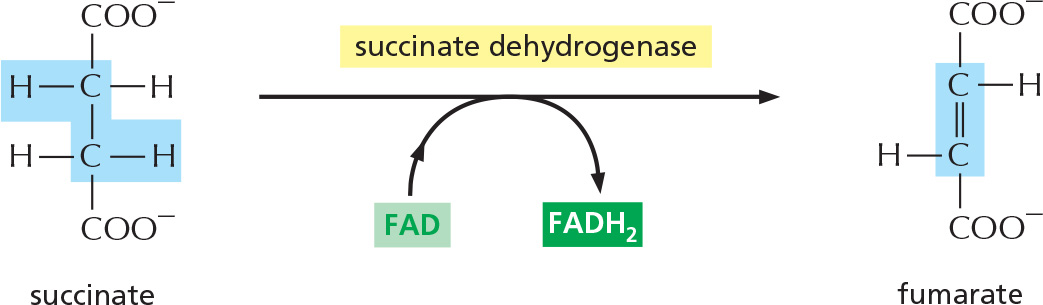
In the third oxidation step of the cycle, FAD accepts two hydrogen atoms from succinate.
STEP 7
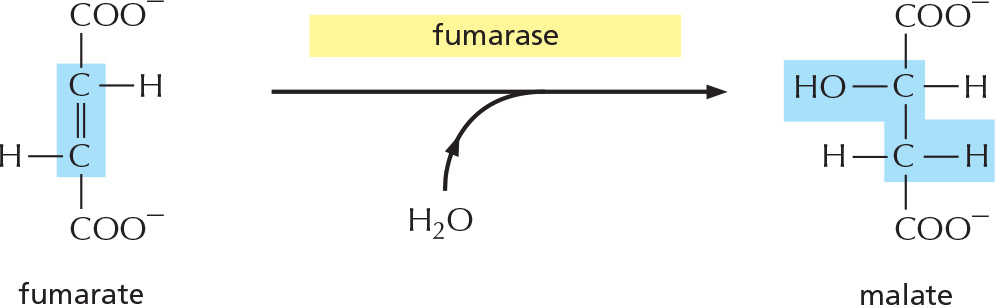
The addition of water to fumarate places a hydroxyl group next to a carbonyl carbon.
STEP 8
In the last of four oxidation steps in the cycle, the carbon carrying the hydroxyl group is converted to a carbonyl group, regenerating the oxaloacetate needed for step 1.
Anaerobic energy-yielding metabolic pathway involving the oxidation of organic molecules. Anaerobic glycolysis refers to the process whereby pyruvate is converted into lactate or ethanol, with the conversion of NADH to NAD+.
Polysaccharide composed exclusively of glucose units. Used to store energy in animal cells. Large granules of glycogen are especially abundant in liver and muscle cells.
Nucleoside triphosphate produced by the phosphorylation of GDP (guanosine diphosphate). Like ATP, it releases a large amount of free energy on hydrolysis of its terminal phosphate group. Has a special role in microtubule assembly, protein synthesis, and cell signaling.
Series of reactions in which electron carrier molecules pass electrons “down the chain” from higher to successively lower energy levels. The energy released during such electron movement can be used to power various processes. Electron-transport chains present in the inner mitochondrial membrane (called the respiratory chain) and in the thylakoid membrane of chloroplasts generate an electrochemical proton gradient across the membrane that is used to drive ATP synthesis.
Process in bacteria and mitochondria in which ATP formation is driven by the transfer of electrons through an electron-transport chain to molecular oxygen. Involves the intermediate generation of an electrochemical proton gradient across a membrane and a chemiosmotic coupling of that gradient to drive ATP production by the ATP synthase.
Biochemical process carried out by certain bacteria that reduces atmospheric nitrogen (N2) to ammonia, leading eventually to various nitrogen-containing metabolites.
[tricarboxylic acid (TCA) cycle; Krebs cycle] Central metabolic pathway found in aerobic organisms. Oxidizes acetyl groups derived from food molecules, generating the activated carriers NADH and FADH2, some GTP, and waste CO2. In eukaryotic cells, it occurs in the mitochondria. (Chapter 2) (Panel 2–9, pp. 110–111)





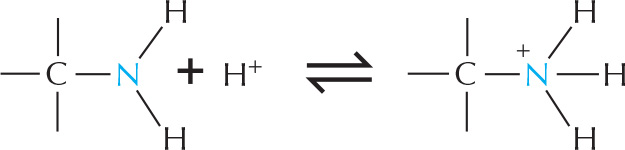
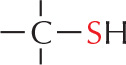 is called a sulfhydryl group. In the amino acid cysteine, the sulfhydryl group may exist in the reduced form
is called a sulfhydryl group. In the amino acid cysteine, the sulfhydryl group may exist in the reduced form 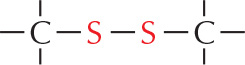
 .
.


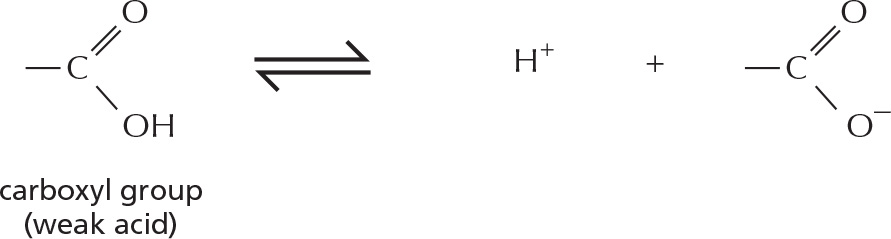
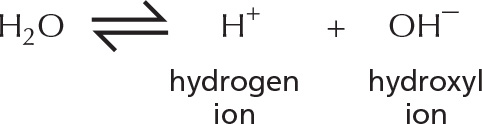
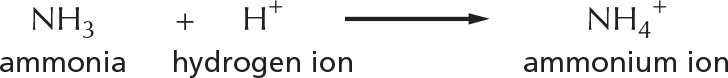

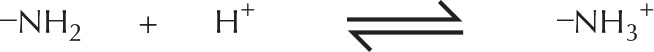
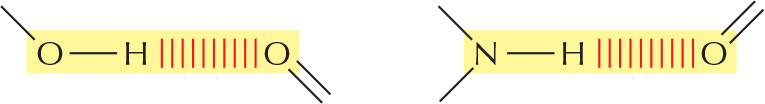

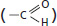 and are called aldoses or a ketone group
and are called aldoses or a ketone group 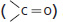 and are called ketoses.
and are called ketoses.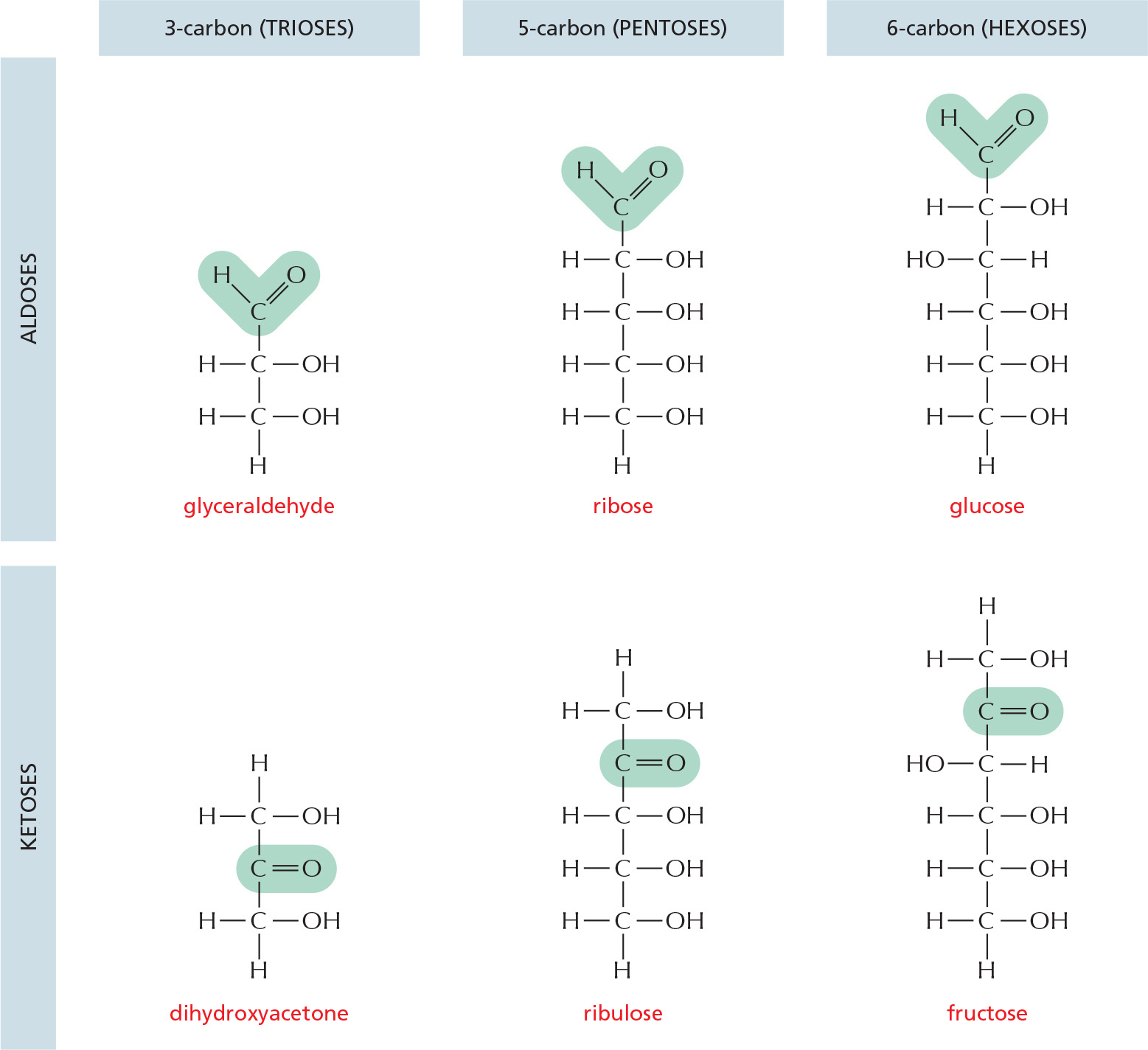


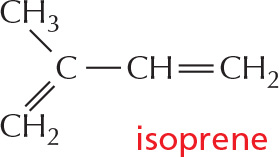



{kind=link}
{kind=link}