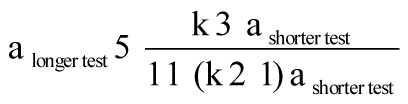Personality is complicated. It is manifested by all of the characteristic ways in which the individual thinks, feels, and behaves—the psychological triad mentioned in Chapter 1. An individual might be deeply afraid of certain things, or attracted to particular kinds of people, or obsessed with accomplishing some highly personal and idiosyncratic goals. The observable aspects of personality are best characterized as clues. The psychologist’s task is to piece these clues together, much like pieces of a puzzle, to form a clear and useful portrait of the individual’s personality.
A psychologist trying to understand an individual’s personality is like a detective solving a mystery. Clues may abound, but the trick is to interpret them correctly.
In that sense, a psychologist trying to understand an individual’s personality is like a detective solving a mystery: Clues may abound, but the trick is to interpret them correctly. A detective arriving on the scene of a burglary finds fingerprints on the windowsill and footprints in the flower bed. These are clues. The detective would be foolish to ignore them. But it might turn out that the fingerprints belong to a careless police officer, and the footprints belong to an innocent gardener. These possibilities are not reasons for the detective to ignore the clues—far from it—but they are reasons to be wary about their meaning.
“Are you just pissing and moaning, or can you verify what you’re saying with data?”
The situation is similar for a personality psychologist. The psychologist might look at an individual’s behavior, test scores, degree of success in daily living, or responses to a laboratory procedure. These are possible clues about personality. The psychologist, like the detective, would be foolish not to gather as many as possible. Also like the detective, the psychologist should maintain a healthy skepticism about the possibility that some or all of them might be misleading.
This brings us to Funder’s Second Law: There are no perfect indicators of personality; there are only clues, and clues are always ambiguous.
But this skepticism should not go too far. It can sometimes be tempting to conclude that because one kind of clue might be uninformative or misleading, it should be ignored. At different times, various psychologists have argued that self-report questionnaires, demographic data, peers’ descriptions of personality, projective personality tests, summaries of clinical cases, or certain laboratory assessment procedures should never be used. The reason given? The method might produce misleading results.
No competent detective would think this way. To ignore a source of data because it might be misleading would be like ignoring the footprints in the garden because they might not belong to the burglar. A much better strategy is to gather all the clues you can with the resources you have. Any of these clues might be misleading; on a bad day, they all might be. But this is no excuse to not gather them. The only alternative to gathering information that might be misleading is to gather no information. That is not progress.
Funder’s Third Law, then, is this: Something beats nothing, two times out of three.
Four Kinds of Clues
Many years ago, the prominent personality psychologist Henry Murray commented that in order to understand personality, first you have to look at it. This sounds obvious, but like many seemingly obvious statements, when thought about carefully it raises an interesting question. If you want to “look at” personality, what do you look at, exactly?
All sources of data are useful; none is perfect.
Four different things. First, and perhaps most obviously, you can see how the person describes herself. Personality psychologists often do exactly this. Second, you can see how other people, who know the person well, describe her. Third, you can see how the person is faring in life. And finally, you can observe what the person does and try to measure her behavior as directly and objectively as possible. These four types of clues can be called S, I, L, and B data. Each method has advantages and disadvantages; all are useful and none is perfect (see Table 2.1).2
Table 2.1ADVANTAGES AND DISADVANTAGES OF THE MAIN SOURCES OF DATA FOR PERSONALITY
Advantages
Disadvantages
S Data: Self-Reports
Large amount of information
Access to thoughts, feelings, and intentions
Some S data are true by definition (e.g., self-esteem)
Causal force
Simple and easy
Error
Bias
Too simple and too easy
I Data: Informants’ Reports
Large amount of information
Real-world basis
Common sense
Some I data are true by definition (e.g., likeability)
Causal force
Limited behavioral information
Lack of access to private experience
Error
Bias
L Data: Life Outcomes
Objective and verifiable
Intrinsic importance
Psychological relevance
Multi-determination
Possible lack of psychological relevance
B Data: Behavioral Observations
Wide range of contexts (both real and contrived)
Appearance of objectivity
Difficult and expensive
Uncertain interpretation
ASK THE PERSON DIRECTLY: S DATA If you want to know what a person is like, why not just ask? S data are self-judgments. The person simply tells the psychologist (usually by answering a questionnaire) the degree to which he is dominant, or friendly, or conscientious. This might be done on a 9-point scale, where the person checks a number from 1 (“I am not at all dominant”) to 9 (“I am very dominant”). Or the procedure might be even simpler: The person reads a statement, such as “I usually dominate the discussions I have with others,” and then responds True or False. According to most research, the way people describe themselves by and large matches the way they are described by others (Funder, 1999; McCrae, 1982; D. Watson, 1989). But the principle behind the use of S data is that the world’s best expert about your personality is very probably you.
There is nothing the least bit tricky or complicated about S data. The psychologist is not interpreting what the participant says or asking about one thing in order to find out about something else. The questionnaires used to gather S data have what is called face validity —they are intended to measure what they seem to measure, on their face.
For instance, right here and now you could make up a face-valid S-data personality questionnaire. How about a new “friendliness” scale? You might include items such as “I really like most people” and “I go to many parties” (to be answered True or False, where a True answer is assumed to reflect friendliness), and “I think people are horrible and mean” (where answering False would raise the friendliness score). In essence, all our new questionnaire really does is ask, over and over in various phrasings, “Are you a friendly person?”
Do we really know ourselves better than anybody else does? Our intuitions would seem to say yes (Vazire & Mehl, 2008). But the truth of the matter is less simple. This is because as a source of information for understanding personality, S data have five advantages and three disadvantages.
Advantage 1: Large Amount of Information While a few close acquaintances might be with you in many situations in your life, you are present in all of them. In the 1960s, a book called the Whole Earth Catalog captured the spirit of the age with cosmic-sounding aphorisms sprinkled through the margins. My favorite read, “Wherever you go, there you are.” This saying describes an important advantage of S data. You live your life in many different settings; even your closest acquaintances are with you within one or, at most, a few of them. The only person on earth in a position to know how you act at home, and at school, and at work, and with your enemies, and with your friends, and with your parents is you. This means that the S data you provide can reflect complex aspects of character that no other data source could access.
Advantage 2: Access to Thoughts, Feelings, and Intentions A second informational advantage of S data is that much, though perhaps not all, of your inner mental life is visible to you, and only you. You know your own fantasies, hopes, dreams, and fears; you directly experience your emotions. Other people can know about these things only if you reveal them, intentionally or not (Spain, Eaton, & Funder, 2000). You also have unique access to your own intentions. The psychological meaning of a behavior often lies in what it was intended to accomplish; other people must infer this intention, whereas your knowledge is more direct.
Advantage 3: Definitional Truth Some kinds of S data are true by definition—they have to be correct, because they are themselves aspects of the self-view. If you think you have high self-esteem, for example, then you do—it doesn’t matter what anyone else thinks.
Advantage 4: Causal Force S data have a way of creating their own reality. What you will attempt to do depends on what you think you are capable of, and your view of the kind of person you are has important effects on the goals that you set for yourself. This idea—the role of what is sometimes called self-efficacy—is considered more fully in Chapter 15. It is also the case that people work hard to bring others to treat them in a manner that confirms their self-conception, a phenomenon called self-verification (Swann & Ely, 1984). For example, if you see yourself as a friendly person, or intelligent, or ethical, you might make an extra effort to have other people see you that way, too.
Even 5-year-old children can provide self-judgments with a surprising degree of validity.
Advantage 5: Simple and Easy This is a big one. For cost-effectiveness, S data simply cannot be beat. As you will see later in this chapter, other kinds of data require the researcher to recruit informants, look up information in public records, or find some way to observe the participant directly. But to obtain S data, all the researcher has to do is write up a questionnaire that asks, for example, “How friendly are you?” or “How conscientious are you?” Then the psychologist prints up some copies and hands them to everybody within reach. Or, more often, the researcher sets people in front of a computer screen or posts the questionnaire on the Internet (Gosling, Vazire, Srivastava, & John, 2004). Either way, the researcher can obtain a great deal of interesting, important information about a lot of people quickly and at little cost. Even 5-year-old children can provide self-judgments that have a surprising degree of validity (though 12-year-olds do better; see Markey, Markey, Tinsley, & Ericksen, 2002; Quartier & Rossier, 2008).
Psychological research operates on a low budget compared with research in the other sciences; the research of many psychologists is “funded” essentially by whatever they can cadge from the university’s supply closet. Even psychologists with government grants have much less money to spend than their counterparts in biology, chemistry, and physics.3 Sometimes S data are all a psychologist can get.
Disadvantage 1: Bias Recall that two advantages of S data are that people have unique knowledge of their intentions, and that some self-views of personality are true by definition. The big catch in both of these advantages is that what the person chooses to tell the researcher (or anybody else) about her intentions or self-views might be biased, in at least two ways. First, many of us like to think of ourselves, and tend to describe ourselves, as smarter, kinder, more honest or more psychologically healthy than we really are, and this tendency is particularly strong in certain individuals, such as narcissists (Park & Colvin, 2014). Other people have the reverse tendency and describe themselves more negatively than others do. Interestingly, people actually seem to know whether they are positively or negatively biased about themselves, but this knowledge doesn’t get rid of the bias (Bollich, Rogers, & Vazire, 2015).
A second potential bias in self-report is that a person always has the option of just clamming up, by keeping some aspects of her intentions and experience private. There is no way to prevent someone from withholding information because of a desire for privacy (in fact, one can sympathize with this desire), but if the person does, the S data she provides will be less than thoroughly accurate. A related concern is “faking,” the idea that a person could lie on a personality questionnaire to get the score needed to get a job, for example. However, some writers have pointed out that being able to fake a good score on a personality test requires enough social skill to know what the “right” answers are, and therefore faking is harder than it looks (Hogan & Blickle, 2018). One large study of applicants for a government job showed that when people who were initially rejected for the job after taking a personality test had the opportunity to take the test again, 5.2% changed their scores, but 2.6% changed in the desirable direction and 2.6% changed in the undesirable direction (Hogan, Barrett, & Hogan, 2007)!
Disadvantage 2: Error Even if an individual were to be completely unbiased in her self-judgment and report, her S-data still could contain errors. For one thing, self-judgment can be especially difficult because of the fish-and-water effect, named after the (presumed) fact that fish do not notice they are wet (Kolar, Funder, & Colvin, 1996).4 A consistently kind or generous person might fail to perceive that her behavior is to any degree unusual—she has been that way for so long, it never occurs to her to act otherwise. In this way, an aspect of her own personality becomes invisible to herself. This kind of process can happen with negative as well as positive traits: You might know people who are so consistently manipulative, domineering, fearful, or rude that they are no longer aware that their behavior is distinctive.
The mind might also work to prevent awareness of certain aspects of the self. Freudians point out that some particularly important memories may be repressed because they are too painful to remember (see Chapter 10). Another factor is lack of insight. The self-judgment of personality, like the judgment of personality more generally, is a complex undertaking that is unlikely to be 100 percent successful (Funder, 1999). And some people just aren’t very interested in knowing about themselves. Do you know anybody like this?
Finally, a self-report might be erroneous because the person who provided it was careless. Self-report scales can be long and tedious, and not everybody answers carefully or pays attention all the way to the end. One study found that people who give unreliable S-data because they aren’t paying attention are rated by their acquaintances as unconscientious, disagreeable, and introverted, and they also have lower GPA and more class absences (Bowling et al., 2016).
Disadvantage 3: Too Simple and Too Easy I already mentioned that the single biggest advantage of S data, the one that makes them the most widely used form of data in personality psychology, is that they are so cheap and easy. If you remember Funder’s First Law (about advantages being disadvantages), you can guess what is coming next: S data are so cheap and easy that they are probably overused (Funder, 2001; Baumeister, Vohs, & Funder, 2007). According to one analysis, 70 percent of the articles in an important personality journal were based on self-report (Vazire, 2006).
The point is not that there is anything especially wrong with S data; like all the other types, as we shall see, they have advantages and disadvantages. Moreover, Funder’s Third Law (about something usually beating nothing) comes into play here; a researcher definitely should gather S data if that is all her resources will allow. The problem is that S data have been used in so many studies, for so long, that it sometimes seems as if researchers have forgotten other kinds of data even exist. But three more kinds of data are relevant to personality psychology, and each has its own special advantages and disadvantages as well.
ASK SOMEBODY WHO KNOWS: I DATA A second way to learn about an individual’s personality is to gather the opinions of the people who know that person well in daily life (Connelly & Ones, 2010). I data are judgments by knowledgeable “informants” about general attributes of the individual’s personality. Such judgments can be obtained in many ways. Most of my research has focused on college students. To gather information about their personalities, I ask each of them to provide the names and emails of the two people on campus who know him or her the best. We then recruit these people to come to the lab to describe the student’s personality, where we ask them questions such as, “On a 9-point scale, how dominant, sociable, aggressive, or shy is your acquaintance?”5 The numbers yielded by judgments like these constitute I data.
The informants might be the individual’s acquaintances from daily life (as in my research), or they could be co-workers or clinical psychologists. The key requirement is that the informants be well-acquainted with the individual they are describing, not that they necessarily have any formal expertise about psychology—usually they do not. Moreover, they may not need it. Usually, close acquaintanceship paired with common sense is enough to allow people to make impressively accurate judgments of each other (Connelly & Ones, 2010; Funder, 1993). Indeed, they may be more accurate than self-judgments, especially when the judgments concern traits that are extremely desirable or extremely undesirable (Vazire & Carlson, 2011). Only when the judgments are of a technical nature (e.g., the diagnosis of a mental disorder) does psychological education become relevant. Even then, acquaintances without professional training are typically well aware when someone has psychological problems (Oltmanns & Turkheimer, 2009; Kaurin, Sauerberger, & Funder, 2018).
Another important element of the definition of I data is that they are judgments. They derive from somebody observing somebody else in whatever context they happen to have encountered them and then rendering a general opinion (e.g., how dominant the person is) on the basis of such observation. In that sense, I data are judgmental, subjective, and irreducibly human.6
I data, or their equivalent, are used frequently in daily life. The ubiquitous “letter of recommendation” that employers and schools often insist on receiving is intended to provide I data—the writer’s opinion of the candidate—to the personnel manager or admissions committee.7 Ordinary gossip is filled with I data because few topics of conversation are more interesting than our evaluations of other people. And the first thing some people do, when invited out on a date, is to ask around: “Do you know anything about him? What’s he like?”
As a source of information for understanding personality, I data have five advantages and four disadvantages.
Advantage 1: A Large Amount of Information A close acquaintance who describes someone’s personality is in a position, in principle, to base that description on hundreds of behaviors in dozens of situations. If the informant is a college roommate, she will have observed the “target” of her judgment working, relaxing, interacting with a boyfriend or girlfriend, reacting to an A grade, receiving medical school rejection letters, and so on.
The informational advantage of I data goes beyond the degree of knowledge attained by any single acquaintance. Almost everybody has many acquaintances, which opens the possibility of obtaining more than one judgment of the same person. (This is not possible with S data, of course.) In my research, I try to find at least two acquaintances to judge each of my research participants, and then I average their judgments into a single, aggregate rating. (More would be even better, but two is generally all I can manage.) As we will see later in this chapter, the average of several judgments is much more reliable than the ratings of any single judge, and this fact gives I data a powerful advantage (Hofstee, 1994).
Advantage 2: Real-World Basis The second advantage of most I data is that they come from observing behavior in the real world. Much of the other information about people that psychologists use does not; psychologists often base their conclusions on contrived tests of one kind or another, or on observations in carefully constructed and controlled environments (such as experimental laboratories). Because I data derive from behaviors informants have seen in daily social interactions, they enjoy an extra chance of being relevant to aspects of personality that affect important life outcomes. For example, if the people who know you well rate you as highly conscientious, this is probably because they have seen you working hard and being a reliable person. Not surprisingly, then, you are likely to enjoy high academic achievement and career success (Connelly & Ones, 2010).
Advantage 3: Common Sense A third advantage of I data is that an informant with ordinary common sense will (almost automatically) consider two kinds of context (Funder, 1991). The first is the immediate situation. The psychological meaning of an aggressive behavior can change radically as a function of the situation that prompted it. It makes a difference whether you screamed and yelled at somebody who accidentally bumped you in a crowded elevator or who deliberately rammed your car in a parking lot. And, if you see an acquaintance crying, you will—appropriately—draw different conclusions about his personality depending on whether the crying was caused by the death of a close friend or by the fact that it is raining and your acquaintance was really hoping to play Ultimate Frisbee today.
A second kind of context is provided by the person’s other behaviors. Imagine that you see an acquaintance give a lavish gift to her worst enemy. Your interpretation of what this means may (and should) vary depending on whether this acquaintance is someone who, in the past, has been consistently generous, or sneaky and conniving. In the first case, the gift may be a sincere peace offering. In the second case, there are grounds for suspecting a manipulative scheme afoot (Funder, 1991). Or say your acquaintance is upset after an argument with a friend. Your interpretation depends on whether you know this acquaintance to be someone who is easily upset, or someone who is usually disturbed only under extreme circumstances.
Advantage 4: Definitional Truth Like S data, some kinds of I data are true almost by definition. Take a moment and try to rate yourself on how “charming” you are. Can you? How? It isn’t by looking inside yourself—charm only exists in the eyes of other people, and to assess your own charm you can do little other than try to recall whether people have ever told you or reacted to you as if you were charming. If a psychologist wanted to assess this attribute of your personality, he would probably do better to ask your acquaintances than to ask you. The same is true about other traits such as likeability, sense of humor, attractiveness, obnoxiousness, and other aspects of character that reside in the reactions of others. The difficulty we can have in seeing ourselves as others see us may be the reason that I data are generally better than S data for predicting outcomes such as academic achievement and occupational success, both of which depend critically on what others think of us (Connelly & Ones, 2010).
TRY FOR YOURSELF 2.1
S-Data and I-Data Personality Ratings
Self-descriptions (S data) and descriptions of a person by others (I data) can both be valuable sources of information. But the points of view may be different. On the scales below, try rating yourself and then rating someone else you know quite well. Then, if you dare, have the other person do the same to you!
S Data
Instructions: Rate each of the following items according to how well it describes you. Use a scale of 1 to 9, where 1 = “highly uncharacteristic,” 5 = “neither characteristic nor uncharacteristic,” and 9 = “highly characteristic.”
Is critical, skeptical, not easily impressed
1 2 3 4 5 6 7 8 9
Is a genuinely dependable and responsible person
1 2 3 4 5 6 7 8 9
Has a wide range of interests
1 2 3 4 5 6 7 8 9
Is a talkative individual
1 2 3 4 5 6 7 8 9
Behaves in a giving way to others
1 2 3 4 5 6 7 8 9
Is uncomfortable with uncertainty and complexities
1 2 3 4 5 6 7 8 9
Is protective of those close to him or her
1 2 3 4 5 6 7 8 9
Initiates humor
1 2 3 4 5 6 7 8 9
Is calm, relaxed in manner
1 2 3 4 5 6 7 8 9
Tends to ruminate and have persistent, preoccupying thoughts
1 2 3 4 5 6 7 8 9
I Data
Instructions: Think of a person you feel you know quite well. Rate each of the following items according to how well it describes this person. Use a scale of 1 to 9, where 1 5 “highly uncharacteristic,” 5 5 “neither characteristic nor uncharacteristic,” and 9 5 “highly characteristic.”
Is critical, skeptical, not easily impressed
1 2 3 4 5 6 7 8 9
Is a genuinely dependable and responsible person
1 2 3 4 5 6 7 8 9
Has a wide range of interests
1 2 3 4 5 6 7 8 9
Is a talkative individual
1 2 3 4 5 6 7 8 9
Behaves in a giving way to others
1 2 3 4 5 6 7 8 9
Is uncomfortable with uncertainty and complexities
1 2 3 4 5 6 7 8 9
Is protective of those close to him or her
1 2 3 4 5 6 7 8 9
Initiates humor
1 2 3 4 5 6 7 8 9
Is calm, relaxed in manner
1 2 3 4 5 6 7 8 9
Tends to ruminate and have persistent, preoccupying thoughts
1 2 3 4 5 6 7 8 9
Source: The items come from the California Q-set (J. Block, 1961, 2008) as revised by Bem & Funder (1978). The complete set has 100 items.
“Of course. Your reputation precedes you, sir.”
Advantage 5: Causal Force I data reflect the opinions of people who interact with the person every day; they are the person’s reputation. And, as one of Shakespeare’s characters once noted, reputation is important (see also R. Hogan, 1998). In Othello, Cassio laments,
Reputation, reputation, reputation! O, I have lost my reputation! I have lost the immortal part of myself, and what remains is bestial. My reputation, Iago, my reputation!8
Why is reputation so important? The opinions of others greatly affect both your opportunities and expectancies (Craik, 2009). If a person who is considering hiring you believes you to be competent and conscientious, you are much more likely to get the job than if that person thought you did not have those qualities. Similarly, someone who believes you to be honest will be more likely to lend you money than someone who believes otherwise. If you impress people who meet you as warm and friendly, you will develop more friendships than if you appear cold and aloof. If someone you wish to date asks around and gets a good report, your chances of romantic success can rise dramatically—the reverse will happen if your acquaintances describe you as creepy. Any or all of these appearances may be false or unfair, but their consequences will nonetheless be important.
Moreover, there is evidence (considered in Chapter 5) that, to some degree, people become what others expect them to be. If others expect you to be sociable, aloof, or even intelligent, you may tend to become just that! This phenomenon is sometimes called the expectancy effect (Rosenthal & Rubin, 1978) and sometimes called behavioral confirmation (M. Snyder & Swann, 1978). By either name, it provides another reason to care about what others think of you.
Now consider some drawbacks of I data.
Disadvantage 1: Limited Behavioral Information One disadvantage of I data is the reciprocal of the first advantage. Although an informant might have seen a person’s behavior in a large number and variety of situations, he still has not been with that person all of the time. There is a good deal that even someone’s closest friends do not know. Their knowledge is limited in two ways.
First, there is a sense in which each person lives inside a series of separate compartments, and each compartment contains different people. For instance, much of your life is probably spent at work or at school, and within each of those environments are numerous individuals whom you might see quite frequently there but no place else. When you go home, you see a different group of people; at church or in a club, you see still another group; and so forth. The interesting psychological fact is that, to some degree, you may be a different person in each of these different environments. As William James, one of the first American psychologists, noted long ago,
Many a youth who is demure enough before his parents and teachers swears and swaggers like a pirate among his “tough” young friends. We do not show ourselves to our children as to our club-companions, to our customers as to the laborers we employ, to our masters and employers as to our intimate friends. (James, 1890, p. 294)
An example of what James was talking about arises when people, whose knowledge of one another has developed in and adapted to one life environment, confront each other in a different environment in which they have developed distinct identities. You may be a conscientious and reliable employee much appreciated by your boss, but you will probably be disconcerted if you suddenly encounter her at a wild Friday night party where you are dancing with a lampshade on your head. (Does anyone actually do this?) At work, seeing your boss is not a problem, but at that party, what do you do? In general, people are more comfortable if those who inhabit the compartments of their lives just stay put and do not cross over into where they do not belong. To the extent that you are a different person in these different compartments, the I data provided by any one person will have limited validity as a description of what you are like in general.
Disadvantage 2: Lack of Access to Private Experience A related limitation is that everybody has an inner mental life, including fantasies, fears, hopes, and dreams. These are important aspects of personality, but they can be reflected in I data only to the extent that they have been revealed to someone else. I data provide a view of personality from the outside; information about inner psychology must be obtained in some other manner—in most cases via S data (McCrae, 1994; Spain, Eaton, & Funder, 2000; Vazire, 2010)—and in some cases perhaps not at all.
Disadvantage 3: Error Because informants are only human, their judgments will sometimes be mistaken. I data provided by a close acquaintance can be based on the observation of hundreds of behaviors in dozens of situational contexts. But that is just in principle. As in the case of S data, where it simply is not possible to remember everything you have ever done, no informant can remember everything he has ever seen another person do either.
It is the behaviors that a person performs consistently, day in and day out, that are most informative about personality.
The behaviors that are most likely to stick in memory are those that are extreme, unusual, or emotionally arousing (Tversky & Kahneman, 1973). An informant judging an acquaintance might tend to forget the ordinary events he has observed but remember vividly the fistfight the acquaintance got involved in (once in four years), or the time she got drunk (for the first and only time), or how she accidentally knocked a bowl of guacamole dip onto the white shag carpeting (perhaps an unusually clumsy act by a normally graceful person). And, according to some psychologists, people have a tendency to take single events like these and imply a general personality trait where none may actually exist (Gilbert & Malone, 1995). Extreme behaviors do deserve extra attention; if you detect signs that a person is dangerous, for example, it is only rational to have this fact influence how you deal with him (Lieder, Griffiths, & Hsu, 2018). However, in most cases, it is the behaviors that a person performs consistently, day in and day out, that are most informative about personality. As a result, the tendency by informants to especially remember the unusual or dramatic may lead to judgments that are less accurate than they could be.
Disadvantage 4: Bias The term error refers to mistakes that occur more or less randomly because memory is not perfect. As with self-reports, the term bias refers to something more systematic, such as seeing someone in more positive or negative terms than they really deserve. In other words, personality judgments can be unfair as well as mistaken.
Perhaps an informant does not like, or even detests, the person he was recruited to describe. On the other hand, perhaps he is in love!9 Or, perhaps the informant is in competition for some prize, job, boyfriend, or girlfriend—all quite common situations. The most common problem that arises from letting people choose their own informants—the usual practice in research—may be the “letter of recommendation effect” (Leising, Erbs, & Fritz, 2010). Just as you would not ask for a letter of recommendation from a professor who thinks you are a poor student, research participants may nominate informants who think well of them, leading to I data that provide a more positive picture than might have been obtained from more neutral parties.
Biases of a more general type are also potentially important. Perhaps the participant is a member of a minority racial group and the informant is racist. Perhaps the informant is sexist, with strong ideas about what all women (or men) are like. If you are studying psychology, you may have experienced another kind of bias. People might have all sorts of ideas about what you must be like based on their knowledge that you are a “psych major.” Is there any truth to what they think?
LIFE OUTCOMES: L DATA Have you ever been arrested? Did you graduate from high school? Are you married? How many times have you been hospitalized? Are you employed? What is your annual income? The answers to questions like these constitute L data, which are verifiable, concrete, real-life facts that may hold psychological significance. The L stands for “life.”
L data can be obtained from archival records such as police blotters, medical files, web pages, or questions directly asked of the participant. An advantage of using archival records is that they are not prone to the potential biases of self-report or the judgments of others. But getting access to such data can be tricky and sometimes raises ethical issues. An advantage of directly asking participants is that access is easier and raises fewer ethical issues, because if participants don’t want the researcher to know, they don’t have to answer. But participants sometimes have faulty memories (exactly how many days did you miss because of illness when you were in elementary school?), and also may distort their reports of some kinds of information (why were you arrested? what is your income?).
L data can be thought of as the results, or “residue,” of personality. They reflect how a person has affected her world, including important life outcomes, such as health or occupational success. Or even, consider the condition of your bedroom. Its current state is determined by what you have done in it, which is, in turn, affected by the kind of person you are. One study sent observers into college students’ bedrooms to rate them on several dimensions. These ratings were then compared with personality assessments obtained separately. It turns out that people with tidy bedrooms tended to be conscientious, and people whose rooms contained a wide variety of books and magazines tended to be open to experience (Gosling, Ko, Mannarelli, & Morris, 2002; see Figure 2.1). Conscientious people make their beds. Curious people read a lot. But a person’s degree of extraversion cannot be diagnosed from peeking at her bedroom—the rooms of extraverts and introverts looked about the same.
Figure 2.1What Your Personal Space Says About You One example of L data (life-outcome data) that can reveal something about personality is the physical space an individual creates. One of these dorm rooms belongs to someone high in the trait of “conscientiousness”; the other to someone low in this trait. Can you tell which is which? (Of course you can.)
No matter how L data are gathered, as information about human personality, they have three advantages and one big disadvantage.
Advantage 1: Objective and Verifiable The first and perhaps most obvious advantage of L data is their specific and objective nature. The number of times someone has been arrested, his income, his marital status, his health status, the number of his Facebook friends and many other psychologically important outcomes are admirably concrete and may even be expressed in exact, numeric form. This kind of precision is rare in psychology.
Advantage 2: Intrinsic Importance An even more important reason L data are important is that often—when they concern outcomes more consequential than the neatness of one’s bedroom—they constitute exactly what the psychologist needs to know. The goal of every applied psychologist is to predict, and even have a positive effect on, real-life consequences such as criminal behavior, employment status, success in school, accident-proneness, or the health of her clients.
Advantage 3: Psychological Relevance The third reason L data matter is that in many cases they are strongly affected by, and uniquely informative about, psychological variables. Some people have traits that make them more likely than others to engage in criminal behavior. Some people tend to get in more automobile accidents than others, which is why your rates go up after you file a claim. A certain amount of conscientiousness is necessary to hold a job or to graduate from school (Borman, Hanson, & Hedge, 1997). And, as will be described in Chapter 7, relationship satisfaction, occupational success, and health are all importantly affected by personality.
Disadvantage 1: Multidetermination However, it is important to keep one important fact in mind. L data have many causes, so trying to establish direct connections between specific attributes of personality and life outcomes is chancy.
Even an arrest record doesn’t mean much if the person was arrested for a crime she didn’t commit.
During a recession, many people lose their jobs for reasons that have nothing to do with their degree of conscientiousness or any other psychological attribute. Whether one graduates from school may depend on finances rather than dedication. A messy room may be the result of inconsiderate guests, not the personality of the inhabitant. Health might be affected by behavior and mental outlook, but it is also a function of sanitation, exposure to toxins, and the availability of vaccines, among other factors. Sometimes an accident is just an accident. Even an arrest record doesn’t mean much if, as occasionally happens, the person was arrested for a crime she didn’t commit.
The ability to predict a life outcome from personality is constrained by the degree to which it is determined by personality in the first place.
This disadvantage has an important implication: If your business is to predict L data from a person’s personality, no matter how good you are at it, your chances of success are limited. Even if you (somehow) came to fully understand an individual’s psychological makeup, your ability to predict his criminal behavior, employment status, academic success, health, accidents, marriage, or anything else is constrained by the degree to which any of these outcomes is determined by the individual’s personality in the first place.
This fact needs to be kept in mind more often. Psychologists who have the difficult job of trying to predict L data are often criticized for their limited success, and they are sometimes even harsher in their criticism of themselves. But even in the absolute best case, a psychologist can predict a particular outcome from psychological data only to the degree that the outcome is psychologically caused. L data often are psychologically caused only to a small degree. Therefore, a psychologist who attains any degree of success at predicting criminality, employment, school performance, health, or marriage has accomplished something rather remarkable.
WATCH WHAT THE PERSON DOES: B DATA The most visible indication of an individual’s personality is what she does. Observations of a person’s behavior in daily life or in a laboratory produce B data (Furr, 2009); the B, as you probably already figured out, stands for “behavior.”
The idea of B data is that participants are found, or put, in some sort of a situation, sometimes referred to as a testing situation, and then their behavior is directly observed. The situation might be a context in the person’s real life (e.g., a student’s classroom, an employee’s workplace) or a setting that a psychologist has arranged in an experimental laboratory (see Figure 2.2). B data also can be derived from certain kinds of personality tests. What all these cases have in common is that the B data derive from the researcher’s direct observation and recording of what the participant has done.
Figure 2.2Naturalistic and Laboratory B Data Observations of children at play can yield valuable data, whether they are viewed in a natural school situation or a contrived laboratory setting.
NATURAL B DATA The ideal way to collect B data would be to hire a private detective, armed with state-of-the-art surveillance devices and a complete lack of respect for privacy, secretly to follow the participant around night and day. The detective’s report would specify in exact detail everything the participant said and did, and with whom. Ideal, but impossible—and probably unethical, too. So, psychologists have to compromise.
“You’re a good listener.”
One compromise is provided by diary and experience-sampling methods. Research in my own lab has used both. Participants fill out daily diaries that detail what they did that day: how many people they talked to, how many times they told a joke, how much time they spent studying or sleeping, and so on (Spain, 1994). Or, they might report how talkative, confident, or insecure they acted in a situation they experienced the previous day (Sherman, Nave, & Funder, 2010). In a sense, these data are self-reports (S data), but they are not self-judgments; they are reasonably direct indications of what the participant did, described in specific terms close to the time the behavior was performed. But they are a compromise kind of B data because the participant, rather than the psychologist, is the one who actually makes the behavioral observations.
TRY FOR YOURSELF 2.2
What Can L Data Reveal About Personality?
Many kinds of L data are gathered in psychological research. Below are a few examples. On a separate piece of paper, write down the following facts about yourself:
Your age.
Your gender.
The amount of money you earned last month.
The number of days of school or work you missed last year because of illness.
Your grade point average.
The number of miles you travel (driving or otherwise) in an average week.
Is your bedroom neat and tidy right now?
How much and what kind of food is currently in your kitchen?
Have you ever been fired from a job?
Are you or have you ever been married?
Do you hold a valid passport?
How many texts, emails, tweets, or other electronic communications do you receive during an average day?
After you have written your answers, read them over, and answer (to yourself) the following questions:
Are any of these answers particularly revealing about the kind of person you are?
Are any of these answers completely uninformative about the kind of person you are?
Are you certain about your answer to the previous question?
If someone who didn’t know you read these answers, what conclusions would they draw about you?
In what ways would these conclusions be right or wrong?
Experience-sampling methods try to get more directly at what people are doing and feeling moment by moment (Tennen, Affleck, & Armeli, 2005). One early technique was called the “beeper” method (Csikszentmihalyi & Larson, 1992; Spain, 1994) because participants wore radio-controlled pagers that beeped several times a day. The participants then wrote down exactly what they were doing. Technological innovations have updated this procedure; participants carry around handheld computers and enter their reports directly into a database (Feldman-Barrett & Barrett, 2001). Either way, one might suspect that participants would edit what they report, producing sanitized versions of their life events. Based on the reports I have read, I think this is unlikely. At least I hope so! A colleague of mine once did an experience sampling study at his university just after sending his own 18-year-old twin daughters to college in another state. After reading the unvarnished reports of his students’ activities, he came very close to summoning his daughters back home.
One useful technique for direct behavioral assessments in real life is the electronically activated recorder (EAR), developed by psychologist Matthias Mehl and his colleagues (Mehl, Pennebaker, Crow, Dabbs, & Price, 2001; Mehl, 2017). The EAR is a digital audio recorder, carried in a research participant’s pocket or purse, which samples sounds at preset intervals such as, in one study, for 30 seconds at a time, every 12.5 minutes (Vazire & Mehl, 2008). Afterward, research assistants note what the person was doing during each segment, using categories such as “on the phone,” “talking one-on-one,” “laughing,” “singing,” “watching TV,” “attending class,” and so forth. This technique has some limitations, two of which are that the record is audio only (no pictures) and that for practical reasons the recorder can sample only intermittently during the research participant’s day.
But there is more to come, because technology is changing rapidly. Small wearable cameras—only a little larger than lapel pins—are starting to be used. One recent study with 298 participants used cameras that took images every 30 seconds, all day long, producing 254,208 images of 5280 situations (Brown, Blake, & Sherman, 2017). In the face of such massive amounts of data, researchers have had to develop new methods for ambulatory assessment, computer-assisted techniques to assess behaviors, thoughts, and feelings during participants’ normal daily activities (Fahrenberg, Myrtek, Pawlik, & Perrez, 2007).10 To share these methods, a Society for Ambulatory Assessment now holds regular conferences.11
A relatively new and particularly rich source of real-life B data is social media, such as Facebook and Twitter (Kern et al., 2016). Many people enact a good proportion of their social lives online, and the records of these interactions (which, on the Internet, never go away) can provide a valuable window into their personalities (Gosling, Augustine, Vazire, Holtzman, & Gaddis, 2011). One study found from looking at Facebook profiles it was possible to judge the traits of openness, extraversion, conscientiousness, and agreeableness—but not neuroticism (Back et al., 2010). Another study found that when a Facebook page reflected a large amount of social interaction and prominently displayed an attractive photo of the page’s owner, viewers of the page tended to infer—for the most part correctly—that he was relatively narcissistic (Buffardi & Campbell, 2008). And still another study found that friends and romantic partners tend to use and express themselves on Facebook in similar ways (Youyou et al., 2017).
The great thing about B data gathered from real life is that they are realistic; they can describe what people have actually done in their daily lives, including their virtual, online lives. The disadvantages of naturalistic B data are their considerable difficulty—the EAR method and wearable cameras, in particular, are challenging to use—and the fact that some contexts one might wish to observe, such as how somebody would behave in a crisis, seldom occur under ordinary circumstances. For both of these reasons, B data derived from laboratory contexts remain important.
Laboratory B Data Behavioral observations in the laboratory come in two varieties.
Experiments The first variety is the psychological experiment. A participant is put into a room, something is made to happen, and the psychologist directly observes what the participant then does.12 The “something” that happens can be dramatic or mundane. The participant might be given a form to fill out, and then suddenly there is a crisis; smoke is pouring under the door. The psychologist, sitting just outside holding a stopwatch, intends to measure how long it will take before the participant goes for help, if she ever does. (Some sit until the smoke is too thick to see through.) If a researcher wanted to assess the participant’s latency of response to smoke from naturalistic B data, it would probably take a long time, if ever, before the appropriate situation came along. In an experiment, the psychologist can just make it happen.
Other examples of B data are more mundane, but still interesting. One study asked participants to flip a coin and report how many times it came up heads. Under the honor system, they were paid more money the more heads they reported. Suspiciously, but interestingly, the most heads were reported by people high in the “dark triad” traits of psychopathy, narcissism, and Machiavellianism (Jones & Paulhus, 2017). Another imaginative study asked people to construct computer “avatars” to represent themselves (Kong & Mar, 2015; see Figure 2.3). The results showed that their personalities could be accurately judged, to some degree, on the basis of their avatars alone. The properties of these avatars, which included what they wore, whether their eyes were open or closed, and their facial expressions, were rated by research assistants and became B data.
Figure 2.3Which Avatar Is You? Research has shown that the avatar you choose to represent yourself may reveal something about your personality.
In my own research, I often have participants sit down with partners of the opposite sex and engage in a conversation. This is not a completely bizarre situation compared to what happens in daily life, although it is unusual because the participants know it is an experiment and know it is being video recorded. The purpose is to observe directly aspects of interpersonal behavior and personal style. In other video recorded situations, participants play competitive games, cooperate in building Tinkertoy models, or engage in a group discussion. All of these artificial settings allow direct observation of behaviors that would be difficult to access otherwise. The observations become B data (Funder & Colvin, 1991; Funder, Furr, & Colvin, 2000; Furr & Funder, 2004, 2007).
Physiological Measures Physiological measures provide another, increasingly important source of laboratory-based B data. These include measures of blood pressure, galvanic skin response (which varies according to moisture on the skin, that is, sweating), heart rate, and even highly complex measures of brain function, such as pictures derived from CT scans or PET scans (which detect blood flow and metabolic activity in the brain; see Chapter 8). All of these can be classified as B data because they are things the participant does—albeit via his autonomic nervous system—and are measured directly in the laboratory. (In principle, these could be measured in real-life settings as well, but the technical obstacles are formidable.)
B data have two advantages and two disadvantages.
Advantage 1: Range of Contexts Some aspects of personality are regularly manifested in people’s ordinary, daily lives. Your sociability is probably evident during many hours every day. But other aspects are hidden or, in a sense, latent. How could you know how you would respond to being alone in a room with smoke pouring under the door unless you were actually confronted with that situation? One important advantage of laboratory B data is that the psychologist does not have to sit around waiting for a situation like this; if people can be enticed into an experiment, the psychologist can make it happen. The variety of B data that can be gathered is limited only by the psychologist’s resources, imagination, and ethics.
Advantage 2: Appearance of Objectivity Probably the most important advantage of B data, and the basis of most of their appeal to scientifically minded psychologists, is this: To the extent that B data are based on direct observation, the psychologist is gathering his own information about personality and does not have to take anyone else’s word for it. Perhaps even more importantly, the direct gathering of data makes it possible for the psychologist to devise techniques to increase their precision.
Often the measurement of behavior seems so direct that it is possible to forget that it is just an observation. For example, when a cognitive psychologist measures how long it takes, in milliseconds, for a participant to respond to a visual stimulus flashed on a tachistoscope, this measurement is a behavioral observation. A biological psychologist can take measurements of blood pressure or metabolic activity. Similarly, a social psychologist can measure the degree to which a participant conforms to the opinions of others, or reacts aggressively to an insult. In my laboratory, from the video recordings of my participants’ conversations, I can measure how long each one talked, how much each one dominated the interaction, how nervous each one seemed, and so forth (Funder et al., 2000).
Still, even B data are not quite as objective as they might appear because many subjective judgments must be made on the way to deciding which behaviors to observe and how to rate them (Sherman, Nave, & Funder, 2009). Even the definition of behavior can be tricky. Is “arguing with someone” a single behavior? Is “raising one’s left arm 2 inches” also a single behavior? How about “completing a painting”? However one chooses to answer these questions, B data have two important, powerful disadvantages.
Disadvantage 1: Difficult and Expensive Whether in real-life settings or in the laboratory, most kinds of B data are expensive to gather. Experience-sampling methods require major efforts to recruit, instruct, and motivate research participants, and may also need expensive equipment. Laboratory studies require the researcher to set up the testing situation, to recruit participants (and induce them to show up on time), and to code the observational data. This is probably the main reason B data are not used very often compared to the other types (Baumeister et al., 2007). Relatively few psychologists have the necessary resources and want to make the effort.
Disadvantage 2: Uncertain Interpretation No matter how it is gathered, a bit of B data is just that: a bit of data. It is usually a number, and numbers do not interpret themselves. Worse, when it comes to B data, appearances are often ambiguous or even misleading, making it impossible to be entirely certain what they mean.
For example, consider again the situation in which someone gives you an extravagant gift. Do you immediately conclude that this person is generous, likes you very much, or both? Perhaps, but you are probably sensible enough to consider other possibilities. The conclusion you draw about this behavior will be based on much more than the behavior itself; it depends on the context in which the gift was given and, even more importantly, what else you know about the giver.
The same thing is true of any behavior seen in real life or the laboratory. The person may give a gift or have a sudden intense spike in heart rate or metabolic activity in the prefrontal cortex, or select an avatar with an unhappy expression, or simply sit and wait a long time for a small reward. All these behaviors, and more, can be measured with great precision. But to determine what the behaviors mean, psychologically, requires more information. The most important information is how the B data are associated with the other kinds: S, I, and L data. For example, the reason we know that facial expressions on avatars are informative is that they vary according to the personalities (measured via S data and I data) of the people who choose them.
MIXED TYPES OF DATA It is easy to come up with simple and obvious examples of the four kinds of data. With a little thought, it is almost as easy to come up with confusing or mixed cases.13 For example, a self-report of your own behaviors during the day is what kind of data? As mentioned earlier, it seems to be a hybrid of B data and S data. Another hybrid between B data and S data is the kind sometimes called behavioroid, in which participants report what they think they would do under various circumstances. For example, if your neighbor’s house suddenly caught on fire, what would you do? The answer to this kind of question can be interesting, but what people think they would do and what they actually do are not always the same (Sweeney & Moyer, 2014). What about a self-report of how many times you have suffered from the flu? This might be regarded as a mixture of L data and S data. What about your parents’ report of how healthy you were as a child? This might be a mixture of L data and I data. You can invent many more examples on your own.
The point of the four-way classification offered in this chapter is not to place every kind of data neatly into one and only one category. Rather, the point is to illustrate the types of data that are relevant to personality and to show how they all have both advantages and disadvantages. S, I, L, and B data—and all their possible combinations and mixtures—each provide information missed by the other types, and each raises its own distinctive possibilities for error.
Quality of Data
Alice Waters, the owner of the Chez Panisse restaurant in Berkeley, California, is famous for her passion about ingredients. She insists on personally knowing everybody who supplies her fruits, vegetables, and meats, and frequently visits their farms and ranches. If the ingredients are good, she believes, superb cooking is possible, but if they are bad, you have failed before you started. The ingredients of research are data and, just like in a restaurant, if the ingredients are bad the final product can be no better. We have looked at four basic types of data for personality research: S, I, L, and B data. For each of these—and, indeed, for any type of data in any field—two aspects of quality are paramount: (1) Are the data reliable? (2) Are the data valid? These two questions can be combined into a third question: (3) Are the data generalizable?
RELIABILITY In science, the term reliability has a technical meaning that is narrower than its everyday usage. The common meaning refers to someone or something that is dependable, such as a person who is always on time or a car that never breaks down. Reliable data are sort of like that, but more precisely they are measurements that reflect what you are trying to assess and are not affected by anything else. For example, if you found that a personality test taken by the same person gives different scores on different days, you might worry, with good reason, that the test is not very reliable. Probably, in this case, the test score is being overly influenced by things it shouldn’t be, which might be anything from the participant’s passing mood to the temperature of the room—you may never know. The cumulative effect of such extraneous influences is called measurement error (also called error variance), and the less there is of such error, the more reliable the measurement.
The influences that are considered extraneous depend on what is being measured. If you are trying to measure a person’s mood—a current and presumably temporary state—then the fact that he just found out he won the lottery is highly relevant and not extraneous at all. But if you are trying to measure the person’s usual, or trait, level of emotional experience, then this sudden event is extraneous, the measurement will be misleading, and you might choose to wait for a more ordinary day to administer your questionnaire.
When trying to measure a stable attribute of personality—a trait rather than a state—the question of reliability reduces to this: Can you get the same result more than once? For example, a personality test that, over a long period of time, repeatedly picked out the same individuals as the friendliest in the class would be reliable (although not necessarily valid—that’s another matter we will get to shortly). However, a personality test that on one occasion picked out one student as the most friendly, and on another occasion identified a different student as the most friendly, would be unreliable. It could not possibly be a valid measure of a stable trait of friendliness. Instead, it might be a measure of a state or momentary level of friendliness, or (more likely) it might not be a good measure of anything at all.
Reliability is something that can and should be assessed with any measurement, whether it be a personality test, a thermometer reading, a blood-cell count, or the output of a brain scan (Vul, Harris, Winkielman, & Pashler, 2009). This point is not always appreciated. For example, an acquaintance of mine, a research psychologist, once had a vasectomy. As part of the procedure, a sperm count was determined before and after the operation. He asked the physician a question that is natural for a psychologist: “How reliable is a sperm count?” What he meant was, does a man’s sperm count vary widely according to time of day, or what he has eaten lately, or his mood? Moreover, does it matter which technician does the count, or does the same result occur regardless? The physician, who apparently was trained technically rather than scientifically, failed to understand the question and even seemed insulted. “Our lab is perfectly reliable,” he replied. My acquaintance tried to clarify matters with a follow-up question: “What I mean is, what’s the measurement error of a sperm count?” The physician really was insulted now. “We don’t make errors,” he huffed.
But every measurement includes a certain amount of error. No instrument or technique is perfect. In psychology, at least four things can undermine reliability. First is low precision. Measurements should be taken as exactly as possible, as carefully as possible. This might seem to go without saying, but every experienced researcher has had the nightmarish experience of discovering that a research assistant wandered away for a drink of water when she was supposed to be timing how long it took a participant to solve a problem, or that an item on a questionnaire was so confusing that participants answered almost at random. Mishaps like this happen surprisingly often; be careful.
Second, the state of the participant might vary for reasons that have nothing to do with what is being studied. Some show up ill, some well; some are happy and others are sad; many college student participants are amazingly short on sleep. One study found that about 3 percent to 9 percent of research subjects14 are so inattentive that the data they provide are probably not valid (Maniaci & Rogge, 2014). There is not much that researchers can do about this; variations in the state of the participants are a source of error variance or random “noise” in every psychological study.
A third potential pitfall is the state of the experimenter. One would hope that experimenters, at least, would come to the lab well rested and attentive, but alas, this is not always the case. Variation due to the experimenter is almost as inevitable as variation due to the participants; experimenters try to treat all participants the same but, being human, will fail to some extent. Moreover, participants may respond differently to an experimenter, depending on whether the experimenter is male or female, of a different race than the participant, or even depending on how the experimenter is dressed. B. F. Skinner famously got around this problem by having his subjects—rats and pigeons—studied within a mechanically controlled enclosure, the Skinner box. But for research with humans, we usually need them to interact with other humans, including research assistants.
A final potential pitfall can come from the environment in which the study is done. Experienced researchers have all sorts of stories that never make it into their reports, involving fire alarms (even sprinklers) that go off in the middle of experiments, noisy arguments that suddenly break out in the room next door, laboratory thermostats gone berserk, and so forth. Events like these are relatively unusual, fortunately, and when they happen, all one can usually do is cancel the study for the day, throw the data out, and hope for better luck tomorrow. But minor variations in the environment are constant and inevitable; noise levels, temperature, the weather, and a million other factors vary constantly and provide another potential source of data unreliability.
At least four things can be done to try to enhance reliability (see Table 2.2). One, obviously, is just to be careful. Double-check all measurements, have someone proofread (more than once!) the data-entry sheets, and make sure the procedures for scoring data are clearly understood by everyone. A second way to improve reliability is to use a constant, scripted procedure for data gathering.
Table 2.2RELIABILITY OF PSYCHOLOGICAL MEASUREMENT
Factors That Undermine Reliability
Low precision
State of the participant
State of the experimenter
Variation in the environment
Techniques to Improve Reliability
Care with research procedure
Standardized research protocol
Measure something important
Aggregation
A third way to enhance reliability in psychological research is to measure something that is important rather than trivial. For example, an attitude about an issue that matters to someone is easy to measure reliably, but if the person doesn’t really care (What’s your opinion on lumber tariffs?), then the answer doesn’t mean much. Experimental procedures that engage participants will yield better data than those that fail to involve them; measurement of big important variables (e.g., the degree of a person’s extraversion) will be more reliable than narrow trivial variables (e.g., whether the person is chatting with someone at 1:10 P.M. on a given Saturday).
The fourth and by far the most useful way to enhance the reliability of measurement in any domain is aggregation, or averaging. When I was in high school, a science teacher who I now believe was brilliant (I failed to be impressed at the time) provided the class with the best demonstration of aggregation that I have ever seen. He gave each of us a piece of wood cut to the length of 1 meter. We then went outside and measured the distance to the elementary school down the street, about a kilometer (1,000 meters) away. We did this by laying our stick down, then laying it down again against the end of where it was before, and counting how many times we had to do this before we reached the other school.
In each class, the counts varied widely—from about 750 meters to over 1,200 meters, as I recall. The next day, the teacher wrote all the different results on the blackboard. It seemed that the elementary school just would not hold still! To put this observation another way, our individual measurements were unreliable. It was hard to keep lying the meter stick down over and over again with precision, and it was also hard not to lose count of how many times we did it.
But then the teacher did an amazing thing. He took the 35 measurements from the 9:00 A.M. class and averaged them. He got 957 meters. Then he averaged the 35 measurements from the 10:00 A.M. class. He got 959 meters. The 35 measurements from the 11:00 A.M. class averaged 956 meters. As if by magic, the error variance had almost disappeared, and we suddenly had what looked like a stable estimate of the distance.
What had happened? The teacher had taken advantage of the power of aggregation. Each of the mistakes we made in laying our meter sticks down and losing count was essentially random. And over the long haul, random influences tend to cancel one another out. (Random influences, by definition, sum to zero—if they didn’t, they wouldn’t be random!) While some of us may have been laying our sticks too close together, others were surely laying them too far apart. When all the measurements were averaged, the errors almost completely canceled each other out.
The more error-filled your measurements are, the more of them you need.
This is a basic and powerful principle, and the Spearman-Brown formula in psychometrics, the technology of psychological measurement, quantifies how it works (in case you are curious, the exact formula can be found in footnote 9 of Chapter 3). The more error-filled your measurements are, the more of them you need. The “truth” will emerge in there someplace, near the average.
Aggregation is particularly important if your goal is to predict behavior. Personality psychologists once got into a bitter debate (the “consistency controversy”; see Chapter 4) because single behaviors are difficult to predict accurately from personality measurements. This fact caused some critics to conclude that personality didn’t exist! However, based on the principle of aggregation, it should be much easier to predict the average of a person’s behaviors than single acts. Maybe a friendly person is more friendly at some times than at other times—everyone has bad days. But the average of the person’s behaviors over time should be reliably more friendly than the average of an unfriendly person (Epstein, 1979).
VALIDITY Validity is different from reliability. It also is a more slippery concept. Validity is the degree to which a measurement actually measures what it is supposed to. The concept is slippery for a couple of reasons.
One reason is that, for a measure to be valid, it must be reliable. But a reliable measure is not necessarily valid. Should I say this again? A measure that is reliable gives the same answer time after time. If the answer is always changing, how can it be the right answer? But even if a measure does give consistent results, that does not necessarily mean it is correct. Maybe it reliably gives the wrong answer (like the clock in my old Toyota, which was correct only twice each day). People who study logic distinguish between what they call necessary and sufficient conditions. An example is getting a college education: It might be necessary to get a good job, but it is surely not sufficient. In that sense, reliability is a necessary but not a sufficient condition for validity.
A second and even more difficult complication in the idea of validity is that it seems to invoke a notion of ultimate truth. On the one hand, you have ultimate, true reality. On the other hand, you have a measurement. If the measurement matches ultimate, true reality, it is valid. Thus, an IQ measure is valid if it really measures intelligence. A sociability score is valid if it really measures sociability (Borsboom, Mellenbergh, & van Heerden, 2004). But here is the problem: How does anyone know what intelligence or sociability “really” is?
Some years ago, methodologists Lee Cronbach and Paul Meehl (1955) proposed that attributes like intelligence or sociability are best thought of as constructs.15 A construct is something that cannot be directly seen or touched, but which affects and helps to explain things that are visible. A common example is gravity. Nobody has ever seen or touched gravity, but we know it exists from its many effects, which range from causing apples to fall on people’s heads to keeping planets in their proper astronomical paths. Nobody has ever seen or touched intelligence either, but it affects many aspects of behavior and performance, including test scores and achievement in real life (G. Park, Lubinski, & Benbow, 2007). This range of implications is what makes intelligence important. An old-time psychologist once said, “Intelligence can be defined as what IQ tests measure.” He was wrong.
Personality constructs are the same as gravity or IQ, in this sense. They cannot be seen directly and are known only through their effects. And their importance stems from their wide implications—they are much more than test scores. They are ideas about how behaviors hang together and are affected by a particular attribute of personality. For example, the invisible construct of “sociability” is seen through visible behaviors such as going to parties, smiling at strangers, and posting frequently on Facebook. And the construct implies that these behaviors, and more, should tend to be associated with each other—that somebody who does one of them probably does the others as well. This is because they all are hypothesized to have the same cause: the personality trait of sociability (Borsboom et al., 2004).
However, this hypothesis must be tested, through a process called construct validation (Cronbach & Meehl, 1955). For example, you might give participants a sociability test, ask their acquaintances how sociable they are, and count the number of Facebook entries they post and parties they go to in a week. If these four measures are related—if they all tend to pick out the same individuals as being highly sociable—then you might start to believe that each of them has some degree of validity as a measure of sociability. At the same time, you would become more confident that the overarching construct makes sense, that sociability is useful for predicting and explaining behavior. Even though you never reach ultimate truth, you can start to reasonably believe you are measuring something real when you can develop a group of different measurements that yield more or less the same result.
GENERALIZABILITY Traditional treatments of psychometrics regarded reliability and validity as distinct. When two measures that were supposed to be “the same” were compared, the degree to which they yielded the same result indicated their reliability. But if the two measures were different, then their relationship would indicate the first (or perhaps the second) measure’s degree of validity. For example, if one’s score on a friendliness test is pretty much the same as one’s score on the same test a month later, this would indicate the test’s reliability. But if it also can be used to predict the number of one’s Facebook friends, then this fact would indicate the test’s validity. Or, alternatively, it could be taken to mean that the number of Facebook friends is a valid measure of friendliness. So, you see that the idea of validity is a bit fuzzy, as is the distinction between measures that should be considered “the same” or “different.”
For this reason, modern psychometricians view reliability and validity as aspects of a single, broader concept called generalizability (Cronbach, Gleser, Nanda, & Rajaratnam, 1972). The question of generalizability, applied to a measurement or to the results of an experiment, asks the following: To what else does the measurement or the result generalize? That is, is the result you get with one test largely equivalent to the result you would get using a different test? Does your result also apply to other kinds of people than the ones you assessed, or does it apply to the same people at other times, or would the same result be found at different times, in different places? All of these questions regard facets of generalizability.
Generalizability Over Participants One important facet is generalizability over participants. Most psychological research is done by university professors, and most participants are college students. (There tend to be a lot of students in the vicinity of professors, and gathering data from anybody else—such as randomly selected members of the community—is more difficult and expensive.) But college students are not very good representatives of the broader population. They are, on average, more affluent, more liberal, healthier, younger, and less likely to belong to ethnic minorities. These facts can make you wonder whether research results found with such students will prove to be true about the national population, let alone the world (Henrich, Heine, & Norenzayan, 2010; D. O. Sears, 1986).
Gender Bias An even more egregious example of conclusions based on a limited sample of humanity comes from the fact that until well into the 1960s, it was fairly routine for American psychological researchers to gather data only from male participants. Some classic studies, such as those by Henry Murray (1938) and Gordon Allport (1937), examined only men. I once had a conversation with a major contributor to personality research during the 1940s and 1950s who admitted frankly that he was embarrassed to have used only male participants. “It is hard to recall why we did that,” he said in 1986. “As best as I can remember, it simply never occurred to any of us to include women in the groups we studied.”
Since then, the problem may have reversed. There is one particular fact about recruiting participants, rarely mentioned in methods textbooks, that nearly all researchers know from experience: Women are more likely than men to sign up to be in experiments, and once signed up they are more likely to appear at the scheduled time. The difference is not small. From my desk in the psychology department, I used to look directly across the hallway at a sign-up sheet for my research project, which used paid volunteer participants.16 Because my work needed an exactly equal number of men and women, the sign-up sheet had two separate columns. At any hour of any day, there would be more than twice as many names in the “women” column as in the “men” column, sometimes up to five times as many.
This big difference raises a couple of issues. One is theoretical: Why this difference? One hypothesis could be that college-age women are generally more conscientious and cooperative than men in that age range (which I believe is true), or the difference might go deeper than that. A second issue is that this difference raises a worry about the participants that researchers recruit. It is not so much that samples are unbalanced. Researchers can keep them balanced; in my lab, I simply call all of the men who sign up and about one in three of the women. Rather, the problem is that because men are less likely to volunteer than women, the men in the studies are, by definition, unusual. They are the kind of men who are willing to be in a psychological experiment. Most men aren’t, yet researchers generalize from their willing male participants to men in general.17
Shows Versus No-Shows A related limitation of generalizability is that the results of psychological research depend on the people who show up at the laboratory. Anyone who has ever done research knows that a substantial proportion of the participants who sign up never actually appear. The results, in the end, depend on the attributes of the participants who do appear. This fact presents a problem if the two groups are different.
People who are included in psychology studies may not always be similar to the many others who aren’t.
There is not much research on this issue—it is difficult to study no-shows, as you might expect—but there is a little. According to one study, the people who are most likely to appear for a psychological experiment at the scheduled time are those who adhere to standards of “conventional morality” (Tooke & Ickes, 1988). In another, more recent study, 1,442 college freshmen consented to be in a study of personality, but 283 of these never showed up (Pagan, Eaton, Turkheimer, & Oltmanns, 2006). However, the researchers had personality descriptions of everybody from their acquaintances (I-data). It turned out that the freshmen who showed up were more likely to be described as histrionic (emotionally over-expressive), compulsive, self-sacrificing, and needy. The freshmen who never appeared were described as relatively narcissistic (self-adoring) and low on assertiveness. It is not clear to me how to put these two studies together, but they do serve as warnings that the people who are included in psychology studies may not always be similar to the many others who aren’t.
Ethnic and Cultural Diversity A generalizability issue receiving increased attention concerns the fact that most research is based on a limited subset of the modern population—specifically, the mostly white, middle-class college students referred to earlier. This is a particular issue in the United States, where ethnic diversity is wide, and where minority groups are becoming more assertive about being included in all aspects of society, including psychological research. The pressure is political as well as scientific. One place to see it is in grant application guidelines published by one branch of the U.S. government:
Applications for grants . . . that involve human subjects are required to include minorities and both genders in study populations. . . . This policy applies to all research involving human subjects and human materials, and applies to males and females of all ages. . . . Assess carefully the feasibility of including the broadest possible representation of minority groups. (Public Health Service, 1991, p. 21)
This set of guidelines addresses the representation of American ethnic minorities in research funded by the U.S. government. As the tone of this directive hints, such representation is difficult. But notice that even if every goal it espouses were to be achieved, the American researchers subject to its edict would still be restricted to studying residents of a modern, Western, capitalist, postindustrial society.18
Indeed, Canadian psychologist Joseph Henrich and his colleagues have argued that many conclusions in psychological research are too heavily based on participants who are “WEIRD” in this way, meaning they come from countries that are Western, Educated, Industrialized, Rich, and Democratic (Henrich et al., 2010). The largest part of the research literature is based on participants from the United States, and other leading contributors include Canada, Britain, Germany, Sweden, Australia, and New Zealand—all of which are WEIRD by Henrich’s definition. This is a problem, because Henrich presents evidence that people from countries like these are different from denizens of poor, uneducated, preindustrial, autocratic, and Eastern countries19 on psychological variables ranging from visual perception to moral reasoning.
We should resist making facile and simplistic generalizations about members of other cultures—including jumping to conclusions about ways they might be different.
Still, getting the facts straight about members of our own culture in our own time is difficult enough, so we should resist making facile generalizations about members of other cultures—including jumping to conclusions about ways they might be different. To really understand how psychological processes vary around the world will require a vast amount of further research more equally spread across cultures and less concentrated in WEIRD places. Such research is beginning to appear, but we still have much to learn about cross-cultural differences, including how pervasive they really are (see Chapter 13).
The degree to which an assessment instrument, such as a questionnaire, on its face appears to measure what it is intended to measure. For example, a face-valid measure of sociability might ask about attendance at parties.
The tendency for someone to become the kind of person others expect him or her to be; also known as a self-fulfilling prophecy and behavioral confirmation.
Behavioral data, or direct observations of another’s behavior that are translated directly or nearly directly into numerical form. B data can be gathered in natural or contrived (experimental) settings.
The degree to which a measurement can be found under diverse circumstances, such as time, context, participant population, and so on. In modern psychometrics, this term includes both reliability and validity.
Notes
2. If you have read the writing of other psychologists or even earlier editions of this book, you may notice that these labels keep changing, as do, in subtle ways, the kinds of data to which they refer. Jack Block (J. H. Block & J. Block, 1980) also propounded four types of data, calling them L, O, S, and T. Raymond Cattell (Cattell, 1950, 1965) propounded three types called L, Q, and T. Terri Moffitt (Caspi, 1998; Moffitt, 1991) proposed five types, called S, T, O, R, and I (or STORI). In most respects, Block’s L, O, S, and T data match my L, I, S, and B data; Cattell’s L, Q, and T data match my L (and I), S, and B data; and Moffitt’s T and O match my B, and her R, S, and I match my L, S, and I, respectively. But the definitions are not exactly equivalent across systems. For a detailed typology of B data, see Furr (2009).
3. This discrepancy might make sense (a) if people were easier to understand than cells, chemicals or particles or (b) if it were less important to understand people than cells, chemicals or particles. Is either of these presumptions true?
4. I don’t actually know whether this is true. There is little research on the self-perception of fishes.
5. For obvious reasons, we don’t show their answers to the acquaintance.
6. Their use is not limited to describing humans, though. I-data personality ratings have been successfully used to assess the personalities of chimpanzees, gorillas, monkeys, hyenas, dogs, cats, donkeys, pigs, rats, guppies, and octopuses (Gosling & John, 1999)!
7. In many cases, the letter writer is also asked to fill out a form rating the candidate, using numerical scales, on attributes such as ability, integrity, and motivation.
8. Iago was unimpressed. He replied, in part, “Reputation is an idle and most false imposition, oft got without merit, and lost without deserving” (Othello, act 2, scene 3).
9. Love is not completely blind, though. People are aware that while they find their romantic partners attractive, others might not share their perception (Solomon & Vazire, 2014).
10. Recording behavior in real-life settings also raises ethical issues, which will be considered in Chapter 3.
11. Recent conferences have been held in Greifswald (Germany), Ann Arbor, Amsterdam, and Luxembourg. I bet these meeting are a lot of fun but if you decide to attend, be careful how you behave.
12. By this definition, nearly all data gathered by social and cognitive psychologists are B data, even though those psychologists are ordinarily not accustomed to classifying their data as such. They also do not usually devote much thought to the fact that their technique of data gathering is limited to just one of four possible types.
14. The term subject became passé in psychological research years ago when the Publication Manual of the American Psychological Association mandated that the term participant be used instead. However, the 2010 edition announced a change in policy: Both terms are again acceptable. Hooray. But you will notice that in this book, I almost always use the term “participant.” Once I got in the habit, it was hard to change back.
15. Sometimes the term hypothetical construct is used to underline that the existence of the attribute is not known for certain but instead is hypothesized.
16. These days, of course, we sign up participants via the Internet.
17. It was once suggested to me, quite seriously, that the imbalance could be fixed if we simply paid male participants twice as much as female participants. Does this seem like a good idea to you?
18. Moreover, an astute reader of a previous edition pointed out that even this diversity prescription is limited to people who identify with one of the traditional genders. It overlooks people who identify as genderqueer, of which there are several varieties (Nestle, Howell, & Wilchins, 2002).
19. I suppose we could call these “PUPAE” countries, but I doubt the label will stick.